Introduction
Machine learning algorithms learn patterns from data to make predictions and decisions. Some algorithms build complex mathematical models, while others rely on much simpler logic.
K-Nearest Neighbors (KNN) is one of the simplest and most beginner-friendly machine learning algorithms. Instead of building a complicated formula, KNN makes predictions by comparing new data to similar examples it has already seen.
Imagine moving into a new neighborhood and asking nearby neighbors for restaurant recommendations. If most of the people closest to you recommend the same place, you would probably trust their opinion. KNN works in a very similar way.
Even though KNN is simple, it powers many real-world AI systems, including:
- Netflix recommendations
- Amazon product suggestions
- image recognition systems
- fraud detection tools
- medical diagnosis systems
In this guide, you’ll learn:
- What K-Nearest Neighbors is
- How KNN works step-by-step
- Important beginner concepts
- Types of KNN
- Real-world applications
- Advantages and limitations
- How KNN compares to other machine learning algorithms
If you are new to AI, you may also want to read:
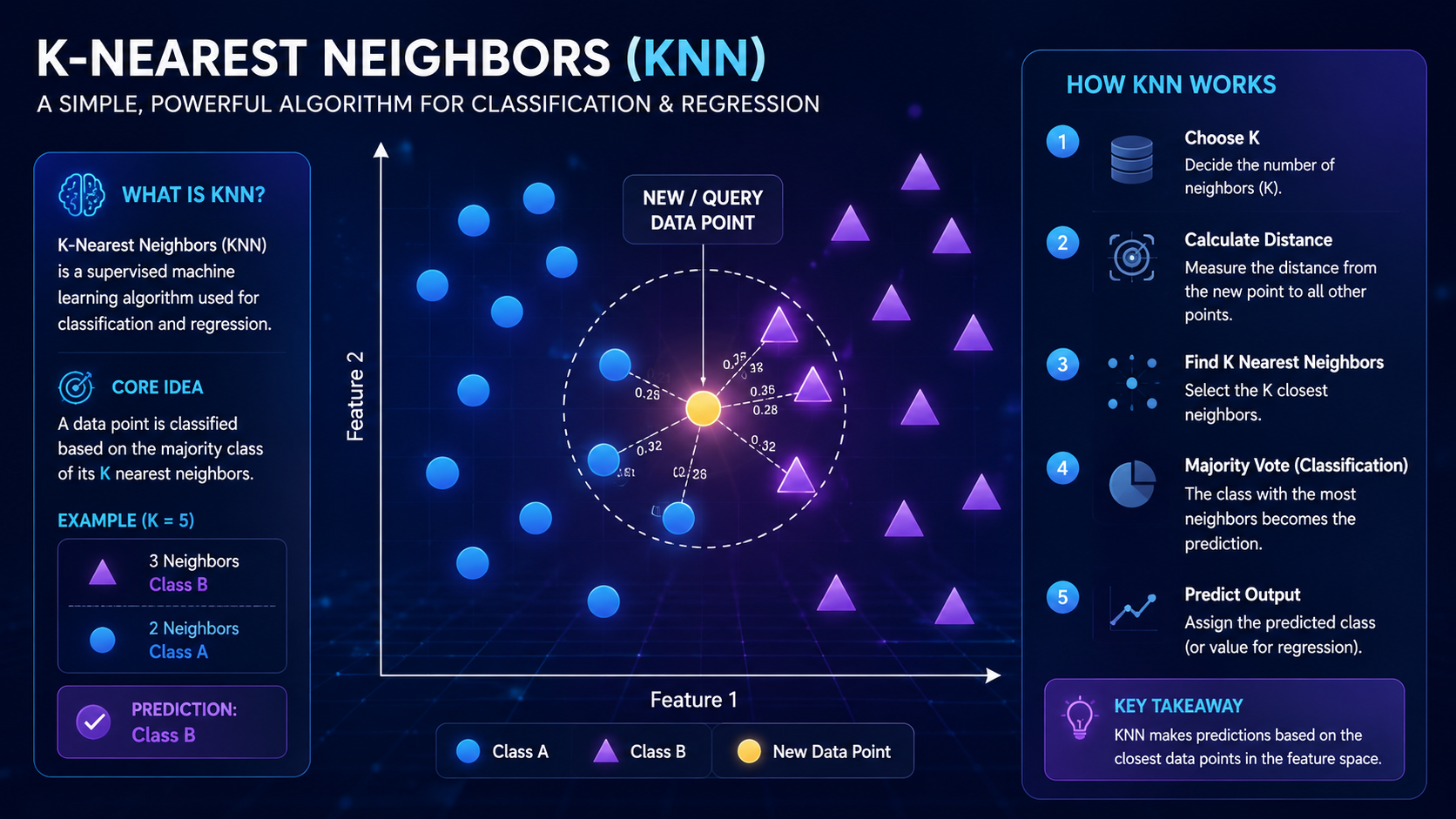
What Is K-Nearest Neighbors?
K-Nearest Neighbors (KNN) is a simple machine learning algorithm that predicts outcomes by comparing new data to similar examples in a dataset. It works by finding the closest nearby data points — called neighbors — and making predictions based on those neighbors.
K-Nearest Neighbors is commonly used in recommendation systems, image recognition, fraud detection, and AI classification tasks because it is easy to understand and effective for many beginner-level machine learning problems.
K-Nearest Neighbors (KNN) is a supervised machine learning algorithm used for:
- classification
- regression
- recommendation systems
Its main idea is simple:
Similar data points are usually located close together.
When a new data point appears, KNN looks at nearby examples in the dataset and predicts the result based on those neighbors.
For example:
- If most nearby images are labeled “dog,” the new image is probably a dog.
- If nearby customers liked a product, a new customer with similar behavior may also like it.
KNN is known as a lazy learning algorithm because it does not build a training model ahead of time. Instead, it stores the dataset and performs calculations only when predictions are needed.
This makes KNN very different from algorithms like:
K-Nearest Neighbors is a supervised machine learning algorithm that classifies data based on the similarity of nearby examples.
How K-Nearest Neighbors Works
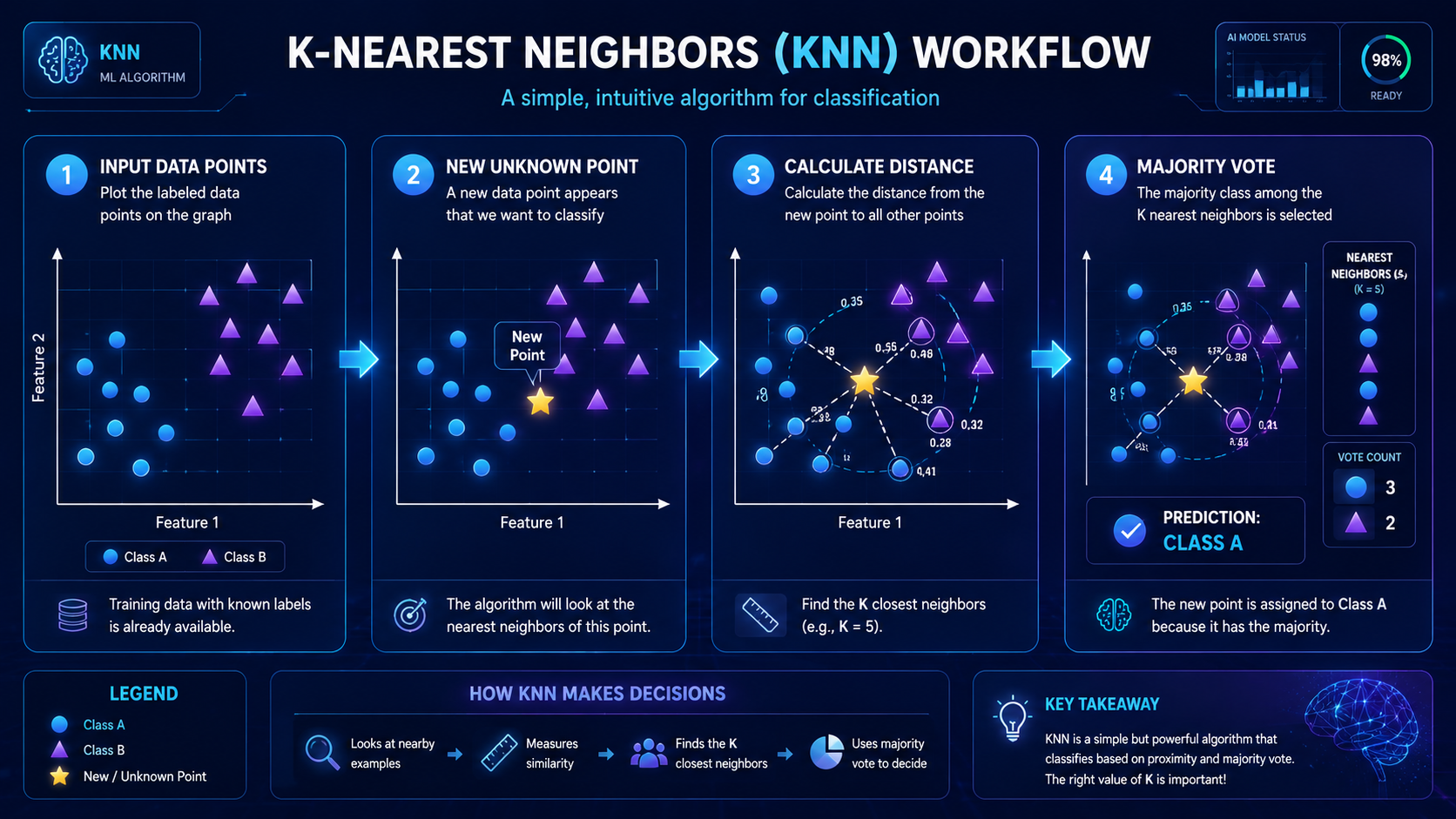
KNN follows a simple step-by-step process.
Imagine plotting data points on a graph. Similar items appear close together, while different items appear farther apart. KNN uses these distances to make decisions.
Step 1: Store the Training Data
KNN begins by storing labeled examples in memory.
For example, imagine a dataset containing:
- age
- height
- favorite sport
Each person already belongs to a known category.
Unlike many algorithms, KNN does not build a complex mathematical model during training.
Step 2: Choose a Value for K
The “K” represents the number of nearby neighbors the algorithm examines.
Examples:
- K = 3 → look at the 3 nearest neighbors
- K = 5 → look at the 5 nearest neighbors
Choosing the right K value is important because it affects accuracy.
Step 3: Measure Distance
When new data appears, KNN calculates how close it is to existing examples.
Think of placing dots on a graph. KNN measures which dots are physically closest to the new point.
Common distance methods include:
- Euclidean distance
- Manhattan distance
The closer the data points are, the more similar they are considered.
Step 4: Find the Nearest Neighbors
The algorithm selects the K closest data points.
For example:
- If K = 5, KNN finds the 5 nearest examples.
These nearby neighbors help determine the prediction.
Step 5: Make a Prediction
KNN then uses the nearby neighbors to make a final decision.
For Classification
The algorithm chooses the most common category.
Example:
- 4 neighbors = “cat”
- 1 neighbor = “dog”
Prediction → Cat
For Regression
The algorithm averages nearby values.
Example:
Nearby house prices:
- $300,000
- $320,000
- $310,000
Prediction → Approximately $310,000
Why Is the Value of K Important?
The value of K determines how many neighboring data points are used when making a prediction.
For example:
- K = 1 uses only the closest neighbor.
- K = 5 uses the five closest neighbors.
- K = 10 uses the ten closest neighbors.
Choosing a very small K can make the model sensitive to noise, while choosing a very large K may oversimplify the results.
Finding the right value of K is an important part of optimizing a KNN model.
How KNN Measures Distance
Distance measurement is one of the most important parts of KNN.
The algorithm must determine which data points are “closest” to each other.
Euclidean Distance
Euclidean distance measures the straight-line distance between two points.
Imagine using a ruler to measure the shortest path between two dots on paper.
This is the most common distance method in KNN.
Manhattan Distance
Manhattan distance measures movement along grid-like paths.
Imagine driving through city streets where you can only move horizontally or vertically.
This method works well for certain types of structured data.
Why Distance Matters
KNN depends entirely on similarity.
If the distance calculations are poor, predictions become less accurate.
This is why:
- clean data matters
- feature scaling matters
- preprocessing matters
You can learn more in:
Key Concepts Beginners Must Understand
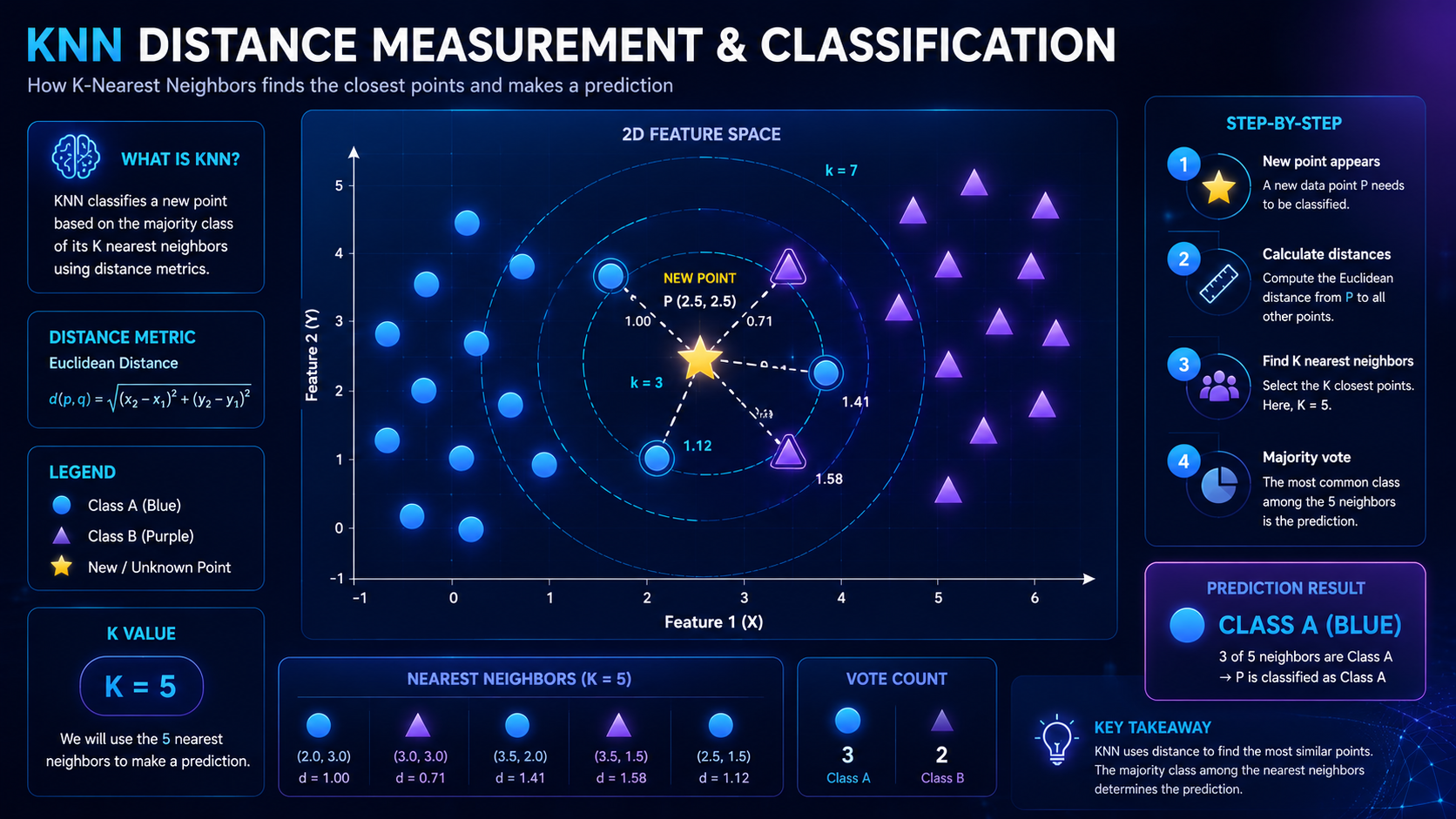
What Does “Nearest” Mean?
“Nearest” simply means “most similar.”
Data points with similar characteristics are usually grouped close together.
Examples:
- customers with similar shopping habits
- movies with similar genres
- patients with similar symptoms
KNN assumes similar items usually belong to the same category.
The Importance of Choosing the Right K Value
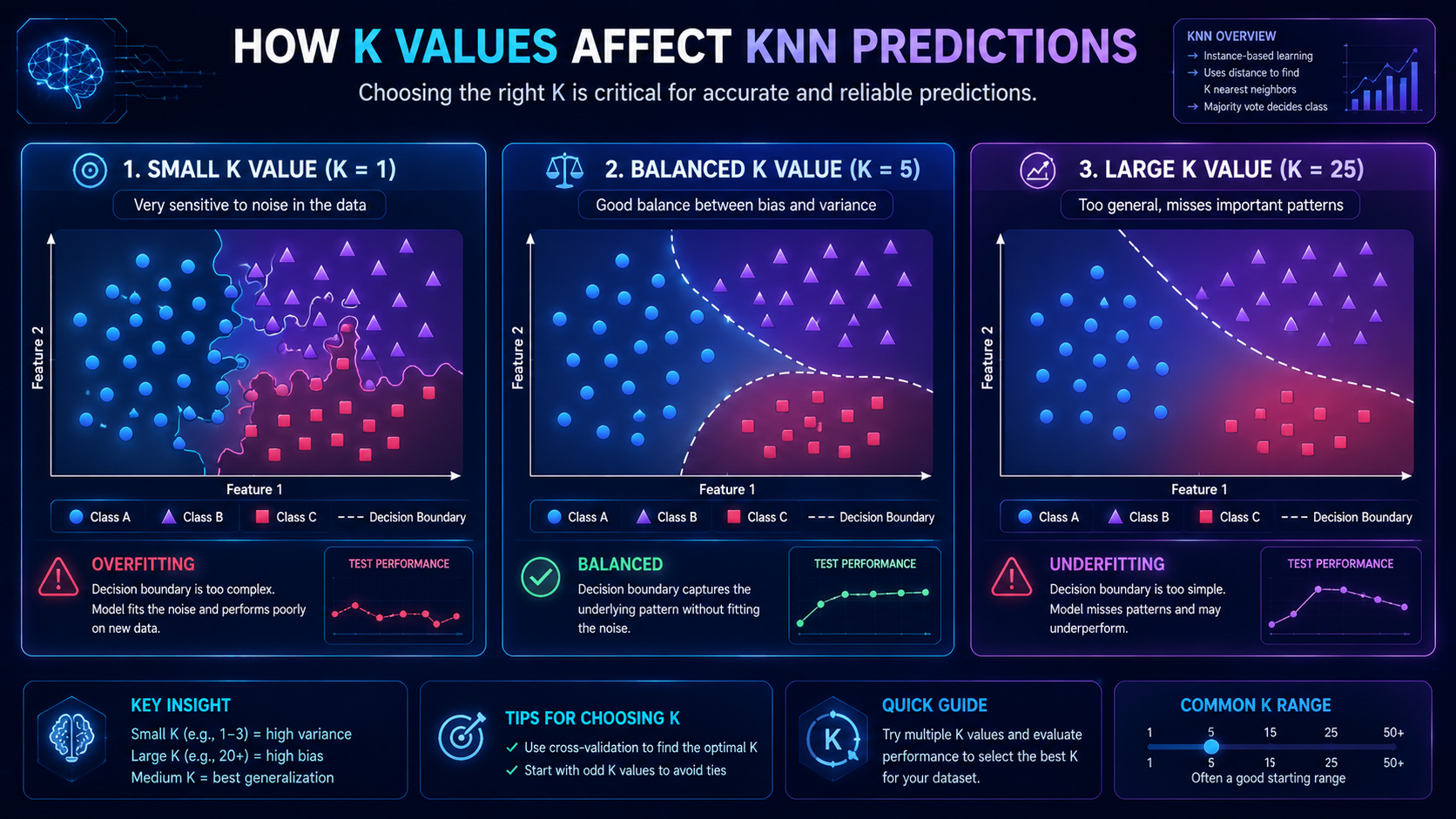
The K value strongly affects prediction quality.
Small K Values
Small values may:
- react too strongly to noise
- create overfitting
- become unstable
Example:
- K = 1 may rely on one unusual data point.
Large K Values
Large values may:
- oversimplify predictions
- ignore local patterns
- create underfitting
Example:
- K = 50 may average too many unrelated neighbors.
This connects closely to:
Why Is Feature Scaling Important for KNN?
Because KNN relies on distance calculations, features with larger numerical values can disproportionately influence predictions. Techniques such as normalization and standardization help ensure that all features contribute fairly to the model.
To learn more, see Data Preprocessing Explained and Feature Engineering Explained.
If one feature has much larger numbers than another, it can dominate the results.
Example:
- Age range: 1–100
- Salary range: 20,000–200,000
Without scaling, salary may overpower age completely.
This is why machine learning often requires:
- normalization
- standardization
- preprocessing
KNN Is Instance-Based Learning
KNN memorizes examples instead of learning formulas.
This means:
- training is fast
- predictions can become slower on large datasets
Types of K-Nearest Neighbors
Classification KNN
Classification KNN predicts categories.
Examples:
- spam vs non-spam emai
- cat vs dog images
- fraudulent vs normal transactions
This is the most common use of KNN.
Regression KNN
Regression KNN predicts numerical values.
Examples:
- house prices
- sales forecasting
- temperature prediction
Instead of voting, the algorithm averages nearby values.
Weighted KNN
Weighted KNN gives closer neighbors more influence than distant neighbors.
For example:
- very close neighbors matter more
- farther neighbors matter less
This often improves prediction accuracy.
Real-World Example: How Netflix Could Use KNN
KNN is commonly used in recommendation systems.
Imagine Netflix analyzing viewer behavior.
Step 1: Compare Users
Netflix identifies users with similar watching habits.
Example:
- User A likes action movies and sci-fi shows
- User B likes
Step 2: Find Similar Neighbors
KNN identifies viewers whose preferences are closest to User A.
These similar viewers become the “nearest neighbors.”
Step 3: Recommend New Content
If similar users enjoyed a movie User A has not watched yet, Netflix may recommend it.
This is a simplified example of similarity-based recommendation systems.
Real-World Applications of K-Nearest Neighbors
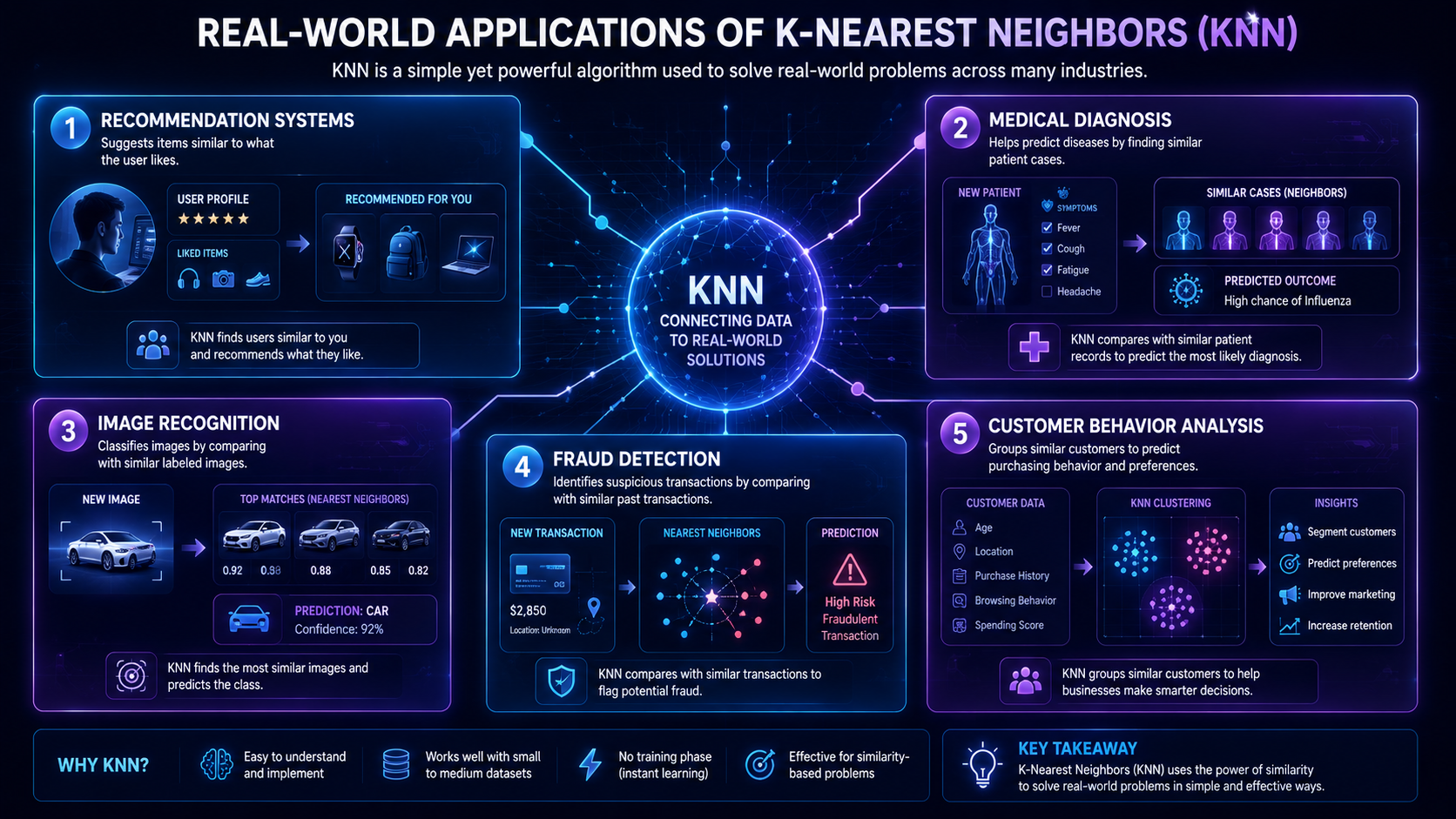
Recommendation Systems
KNN helps recommend:
- movies
- products
- music
- online content
Examples include:
- Netflix
- Amazon
- Spotify
Image Recognition
KNN helps classify images by comparing visual similarities.
Applications include:
- facial recognition
- handwriting recognition
- object detection
This connects closely to:
- Computer Vision Explained
- Neural Networks Explained
Healthcare and Medical Diagnosis
AI systems can compare patient symptoms to previous cases.
Applications include:
- disease prediction
- tumor classification
- patient risk analysis
Fraud Detection
Banks use KNN to identify suspicious transactions.
If a transaction behaves very differently from nearby normal examples, it may be flagged as fraud.
E-Commerce Personalization
Online stores use KNN to:
- personalize shopping recommendations
- predict customer interests
- improve search suggestions
When Should You Use K-Nearest Neighbors?
K-Nearest Neighbors is often used when similar data points are expected to have similar outcomes. The algorithm works particularly well for classification and recommendation tasks where patterns can be identified based on proximity to other examples.
KNN is commonly used for:
- Recommendation systems
- Customer segmentation
- Image classification
- Fraud detection
- Medical diagnosis support
- Pattern recognition
Because KNN is simple to understand and requires minimal training, it is often used as a starting point for machine learning projects and educational demonstrations.
For more advanced classification methods, see Support Vector Machines Explained and Random Forest Explained.
Advantages of K-Nearest Neighbors
| Advantage | Explanation |
| Easy to understand | Simple logic makes KNN beginner-friendly |
| No complex training | KNN stores data directly |
| Works well for small datasets | Effective when datasets are manageable |
| Flexible | Supports classification and regression |
| Easy to update | New data can be added easily |
K-Nearest Neighbors vs Other Machine Learning Algorithms
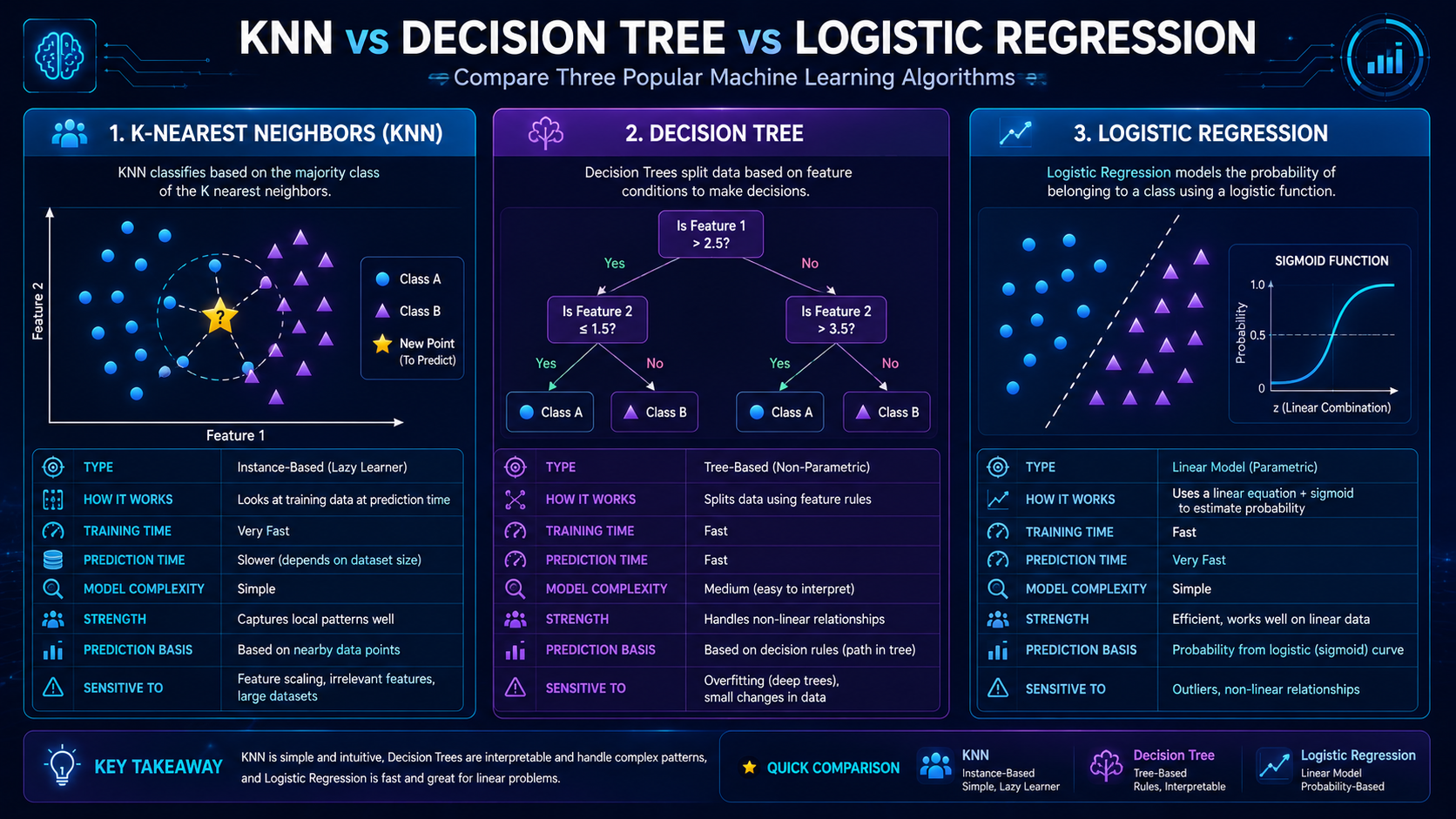
| Algorithm | Main Idea | Strength |
| K-Nearest Neighbors | Uses nearby examples | Simple and intuitive |
| Decision Trees | Splits data into branches | Easy to visualize |
| Random Forest | Combines multiple trees | High accuracy |
| Support Vector Machines | Finds optimal boundaries | Powerful classification |
| Neural Networks | Learns deep patterns | Excellent for complex AI |
KNN is often one of the first algorithms beginners learn because it clearly demonstrates how machine learning identifies patterns.
You may also want to explore:
KNN and Supervised Learning
KNN is a supervised learning algorithm because it learns from labeled examples.
This means:
- training data already contains correct answers
- the algorithm uses those examples to predict future outcomes
Example:
- images labeled “cat” or “dog”
KNN studies those labels and predicts future images.
Compare this with:
Future Outlook of K-Nearest Neighbors
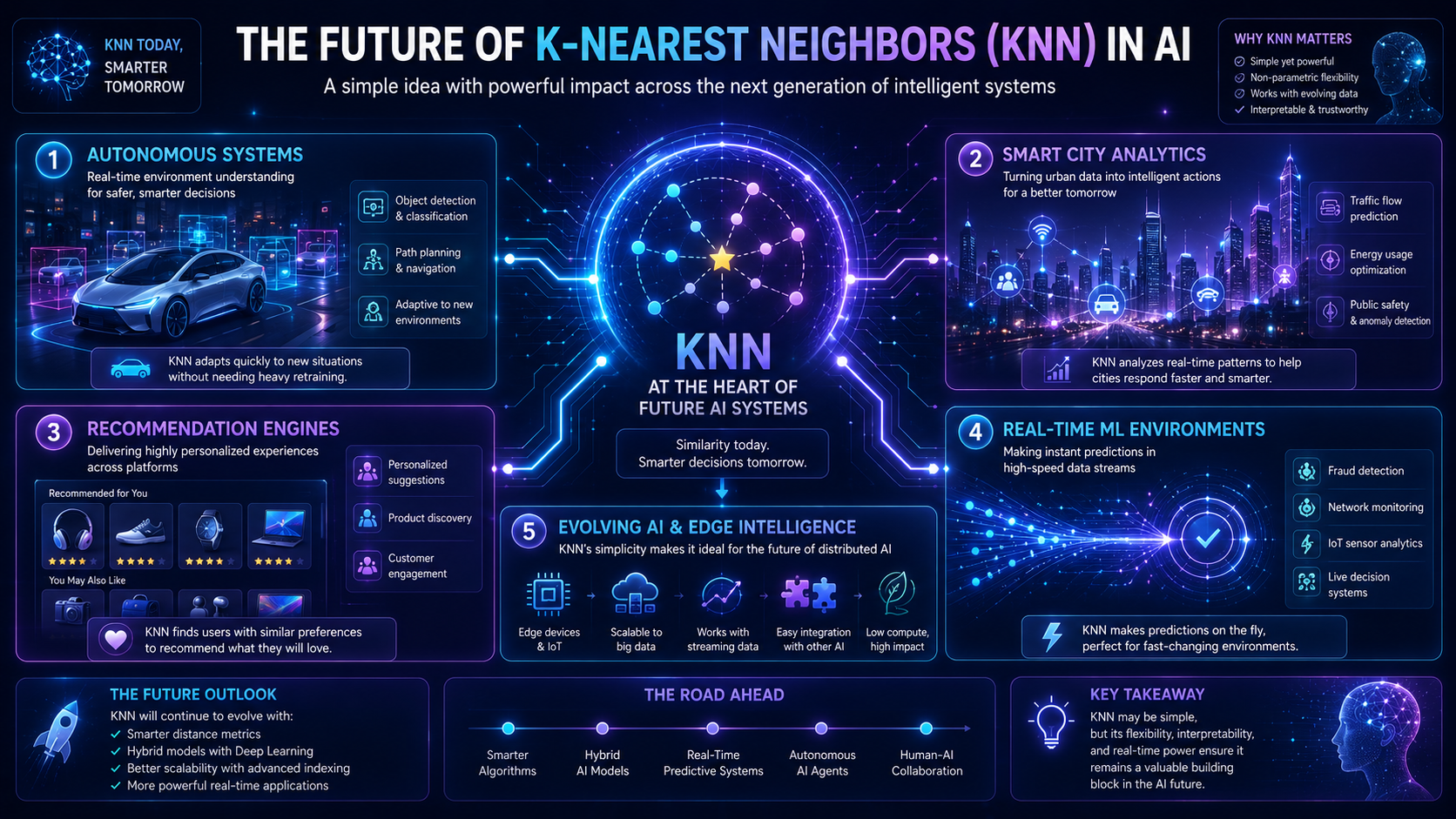
KNN remains important in both AI education and practical applications.
Although modern deep learning systems dominate large-scale AI, KNN still offers several advantages:
- simplicity
- interpretability
- strong performance on smaller datasets
Modern AI systems are improving KNN using:
- faster nearest-neighbor search algorithms
- vector databases
- dimensionality reduction
- embedding-based similarity search
These technologies are especially important in:
- recommendation systems
- semantic search
- AI personalization
- retrieval-based AI systems
Although newer machine learning algorithms such as Random Forests, Gradient Boosting models, and Deep Learning networks often receive more attention, K-Nearest Neighbors remains an important educational and practical algorithm.
Its simplicity makes it valuable for learning machine learning concepts, building recommendation systems, and solving classification problems where data relationships can be measured through similarity.
Even as AI evolves, KNN will likely remain one of the most valuable beginner machine learning algorithms because it teaches core concepts so clearly.
FAQ: K-Nearest Neighbors Explained
What is K-Nearest Neighbors in simple terms?
K-Nearest Neighbors is a machine learning algorithm that predicts outcomes by comparing similar nearby examples.
Why is KNN called a lazy learning algorithm?
KNN is called lazy learning because it stores data instead of building a training model ahead of time.
Is KNN supervised or unsupervised learning?
K-Nearest Neighbors is typically considered a supervised learning algorithm because it uses labeled training data to make predictions and classifications.
What does the “K” mean in KNN?
The “K” represents the number of nearby neighbors the algorithm examines before making a prediction.
What is the best K value in KNN?
There is no universal best value. The ideal K depends on the dataset and is usually found through testing and experimentation.
Why is KNN slow with large datasets?
KNN must calculate distances between many data points, which becomes computationally expensive as datasets grow.
Can KNN work with images?
Yes. KNN can classify images by comparing visual similarities between image features.
Is KNN still used today?
Yes. KNN is still widely used in recommendation systems, search engines, and similarity-based AI applications.
What are the disadvantages of KNN?
KNN can become slow with large datasets and is sensitive to noisy or poorly scaled data
Is KNN part of deep learning?
No. KNN is a traditional machine learning algorithm, while deep learning uses neural networks with many layers.
Conclusion
K-Nearest Neighbors is one of the simplest and most beginner-friendly machine learning algorithms. Instead of learning complicated formulas, KNN predicts outcomes by comparing new data to similar examples.
Although newer deep learning models dominate many advanced AI systems, KNN remains extremely valuable because it clearly demonstrates core machine learning concepts such as:
- similarity
- classification
- distance measurement
- supervised learning
By understanding KNN, beginners build a strong foundation for learning more advanced AI algorithms later.
As your AI knowledge grows, the next topics to explore include:
- Decision Trees Explained
- Random Forest Explained
- Support Vector Machines Explained
- Neural Networks Explained
- Deep Learning Explained
You should also continue building your AI foundations with:
- Artificial Intelligence Explained
- Machine Learning Explained
- Supervised Learning Explained
- Machine Learning Algorithms Overview
- Logistic Regression Explained
- Model Evaluation Metrics Explained
- Feature Engineering Explained
- Data Preprocessing Explained
- Accuracy vs Precision vs Recall
- Cross-Validation Explained
Recommended External Resources
- Learn more from IBM’s guide to machine learning
- Explore Google’s Machine Learning Crash Course for beginner-friendly AI tutorials