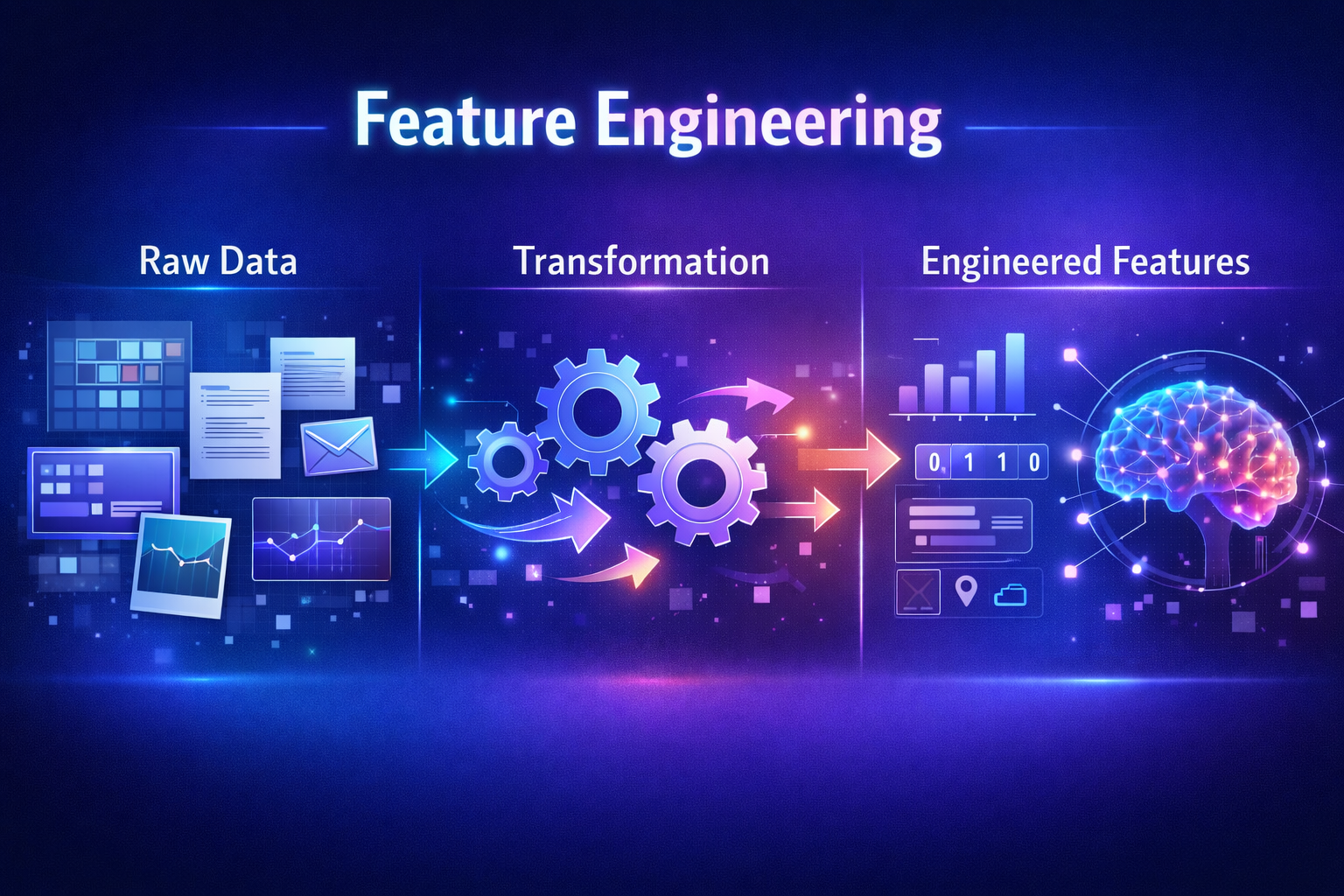
Most machine learning models don’t fail because of bad algorithms—they fail because of bad data.
That’s where feature engineering comes in.
If you want to truly understand how AI models improve performance, this is one of the most important concepts to master.
Introduction to Feature Engineering
Feature engineering explained is like preparing ingredients before cooking.
You wouldn’t throw raw, unprepared ingredients into a dish and expect great results.
Instead, you clean, cut, and combine them to create something useful.
Machine learning works the same way.
Raw data is often:
- Messy
- Incomplete
- Hard to interpret
Feature engineering is an important part of machine learning and artificial intelligence because better data features can improve model accuracy, training quality, and prediction performance.
👉 Within the Data & Fundamentals cluster, feature engineering is a core step in building effective AI systems.
What Is Feature Engineering?
Feature Engineering Explained:
Feature engineering is the process of selecting, transforming, and creating input variables (features) from raw data to improve the performance of machine learning models.
It helps models learn patterns more effectively by making data more meaningful and structured.
Feature engineering involves:
- Selecting relevant data
- Transforming it into better formats
- Creating new features from existing data
Simple Example
Let’s say you’re building a model to predict house prices.
Raw data:
- Sale date
- Square footage
- Location
After feature engineering:
- House age (instead of raw date)
- Price per square foot
- Neighborhood category
👉 These new features make patterns easier for the model to learn.
Why Feature Engineering Is So Important
Feature engineering is often the biggest driver of model performance.
Even simple models can outperform advanced ones if they use better features.
Key Benefits:
- Improves model accuracy
- Makes patterns easier to detect
- Reduces noise in data
- Speeds up learning
Key Insight:
Better data often beats better algorithms.
Feature engineering often works together with data preprocessing, datasets, and neural networks to improve machine learning performance and prediction accuracy.
How Feature Engineering Works (Step-by-Step)

Let’s walk through a real-world example:
👉 Imagine building a movie recommendation system (like Netflix).
Step 1 – Understand the Data
Raw data might include:
- User watch history
- Ratings
- Timestamps
Goal: Understand what each piece of data represents.
Step 2 – Clean the Data
Fix issues like:
- Missing ratings
- Duplicate users
- Incorrect timestamps
👉 Related: Data Preprocessing Explained
Step 3 – Transform Features
Convert data into usable formats:
Examples:
- Convert timestamps → time of day
- Normalize ratings
- Encode categories (genres)
Step 4 – Create New Features
This is where the magic happens.
Examples:
- Average watch time per user
- Favorite genre
- Watch frequency
👉 These features reveal deeper behavior patterns.
Step 5 – Select Important Features
Remove:
- Irrelevant features
- Redundant data
- Noise
👉 Related: Feature Selection vs Feature Extraction
Step 6 – Test and Improve
- Train the model
- Evaluate results
- Adjust features
Feature engineering is iterative, not one-time.
Key Concepts Beginners Must Understand
Features vs Raw Data
- Raw data = unprocessed input
- Features = meaningful inputs used by models
Feature Scaling
Ensures all values are comparable.
Example:
- Income = 100,000
- Age = 25
Without scaling, income dominates learning.
Encoding Categorical Data
Convert text into numbers:
- One-hot encoding
- Label encoding
Handling Missing Data
Common methods:
- Remove rows
- Fill with averages
- Predict missing values
Types of Feature Engineering Techniques
Feature Transformation
Changing format or scale:
- Normalization
- Standardization
- Log transformation
Feature Creation
Creating new variables:
- Ratios
- Time-based features
- Aggregations
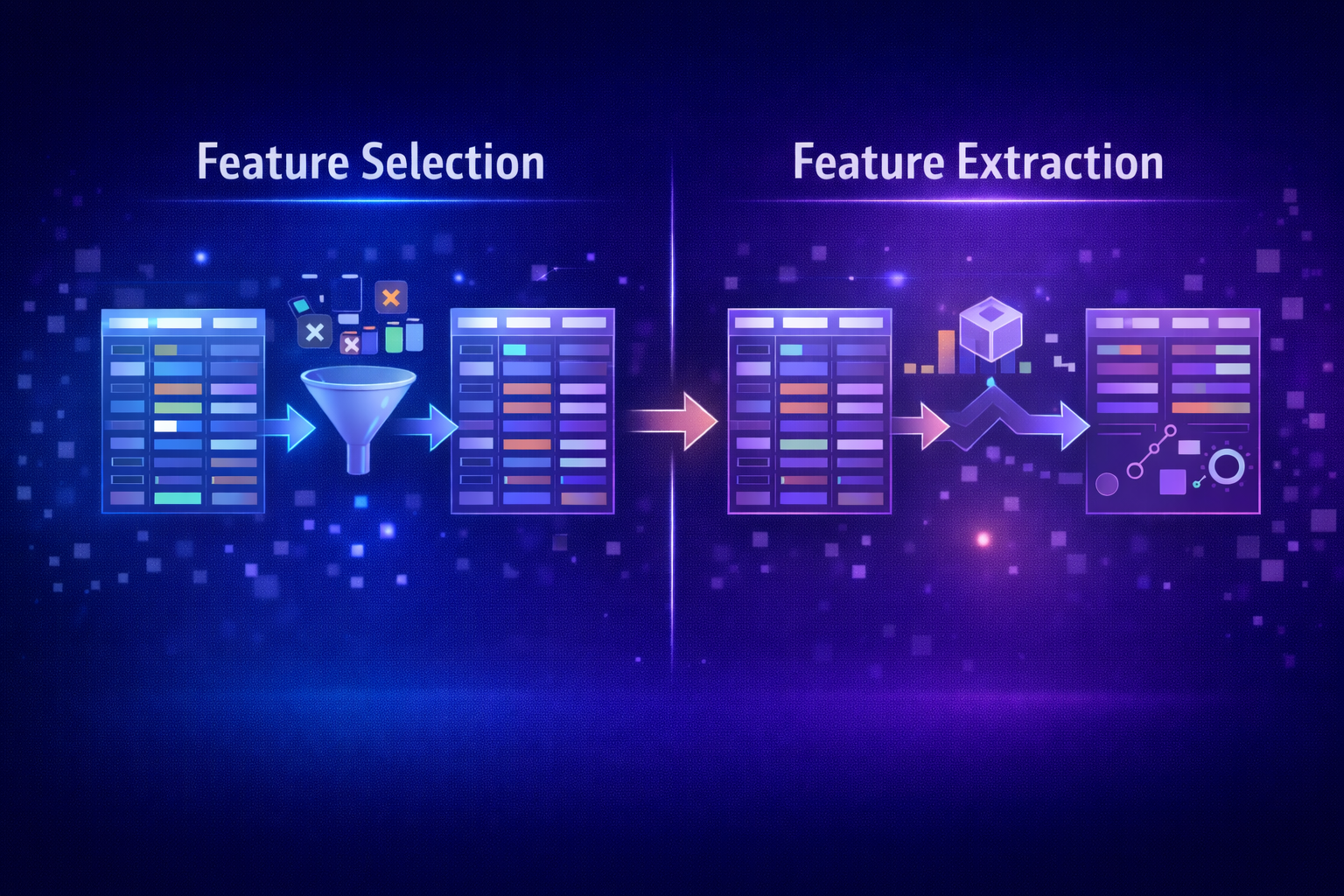
Feature Selection
Choosing the most useful features:
- Improves performance
- Reduces complexity
Feature Extraction
Reducing dimensions while keeping information:
- Example: PCA
Common Feature Engineering Mistakes (Avoid These)
This is where many beginners go wrong.
Using Too Many Features
More data isn’t always better—too many features can confuse the model.
Data Leakage
Using future or hidden information that wouldn’t be available in real-world predictions.
Over-Engineering Features
Creating overly complex features that don’t actually improve performance.
Ignoring Domain Knowledge
Understanding the problem domain is critical for creating meaningful features.
Real-World Applications of Feature Engineering
Finance
- Fraud detection
- Credit scoring
Example:
- Transaction frequency
- Spending patterns
Healthcare
- Disease prediction
- Risk analysis
Example:
- BMI
- Age groups
E-commerce
- Recommendation systems
- Customer segmentation
Example:
- Purchase history
- Browsing behavior
Self-Driving Cars
- Object detection
- Road analysis
Example:
- Extracting features from images and sensors
Advantages of Feature Engineering
- Significantly improves accuracy
- Works with all ML models
- Makes models more interpretable
- Reduces overfitting
Limitations of Feature Engineering
- Time-consuming
- Requires domain knowledge
- Can introduce bias
- Hard to scale manually
Feature Engineering vs Related Concepts
| Concept | Purpose | Key Difference |
| Feature Engineering | Improve input data | Creates better features |
| Data Preprocessing | Clean data | Happens before engineering |
| Feature Selection | Choose best features | Removes unnecessary data |
| Feature Extraction | Reduce dimensions | Compresses data |
External Resources for Further Learning
Future of Feature Engineering

Feature engineering is evolving rapidly.
Key Trends:
- Automated Feature Engineering (AutoML)
- AI-generated features
- Real-time feature pipelines
- Deep learning reducing manual effort
Big Question:
Will feature engineering disappear?
👉 Not completely.
Even as AI automates more tasks, human intuition and domain knowledge remain essential for creating meaningful features.
Key Takeaways
- Feature engineering transforms raw data into meaningful inputs
- It is one of the most important steps in machine learning
- Better features often matter more than better algorithms
- It improves accuracy, speed, and model performance
- It requires both technical skills and real-world understanding
FAQ: Feature Engineering Explained
What is feature engineering in simple terms?
Feature engineering is the process of improving raw data so machine learning models can learn patterns more effectively. It involves transforming and creating features that make the data easier for algorithms to understand.
Why is feature engineering important?
Feature engineering directly impacts how well a machine learning model performs. Better features help models detect patterns more accurately, leading to improved predictions and higher accuracy.
What is an example of feature engineering?
A common example is transforming a timestamp into:
- Day of the week
- Time of day
- Season
This helps models understand patterns related to time.
Is feature engineering still important with deep learning?
Yes, feature engineering is still important. However, deep learning models can automatically learn features from raw data, reducing the need for manual feature engineering.
What is the difference between preprocessing and feature engineering?
Data preprocessing focuses on cleaning and preparing data, while feature engineering focuses on improving and creating features to enhance model performance.
Can feature engineering reduce overfitting?
Yes, feature engineering can reduce overfitting by removing irrelevant features and improving data quality, which helps models generalize better to new data.
What tools are used for feature engineering?
Common tools include:
- Python (Pandas, NumPy) for data manipulation
- Scikit-learn for preprocessing and transformations
- TensorFlow for advanced pipelines and deep learning
What is automated feature engineering?
Automated feature engineering uses AI tools and algorithms to automatically generate useful features from raw data, saving time and improving efficiency.
Do all models require feature engineering?
Most machine learning models benefit from feature engineering. However, deep learning models can automatically learn features, reducing the need for manual work.
What techniques are used in feature engineering?
Common techniques include:
- Feature scaling
- Encoding categorical data
- Creating new features
- Feature selection
- Feature extraction
Is feature engineering hard to learn?
Feature engineering can be challenging at first, but it becomes easier with practice. Understanding your data and the problem you’re solving is the most important part.
How long does feature engineering take?
Feature engineering can take a large portion of a machine learning project—sometimes up to 80%—because it involves cleaning, transforming, and improving data.
Explore More Data & Machine Learning Guides
If you want to continue learning about feature engineering and machine learning systems, explore these beginner-friendly guides covering datasets, preprocessing, neural networks, and AI model optimization.
Artificial Intelligence Foundations
👉 Artificial Intelligence Explained
Data & Training
👉 What Is a Dataset in Machine Learning
👉 Data Preprocessing Explained
👉 Feature Selection vs Feature Extraction
Neural Networks & Deep Learning
👉 Deep Learning vs Machine Learning
Model Evaluation & Optimization
👉 Model Evaluation Metrics Explained
👉 Accuracy vs Precision vs Recall
These guides will help you build a stronger understanding of feature engineering systems and modern artificial intelligence technologies.
Conclusion
Feature engineering is one of the most powerful tools in machine learning.
It transforms raw data into meaningful signals that models can understand.
While algorithms are important, the quality of your features often determines success.
If you master feature engineering, you unlock the ability to build far more accurate and effective AI systems.