Chatbots Explained: A Beginner’s Guide to AI-Powered Conversations
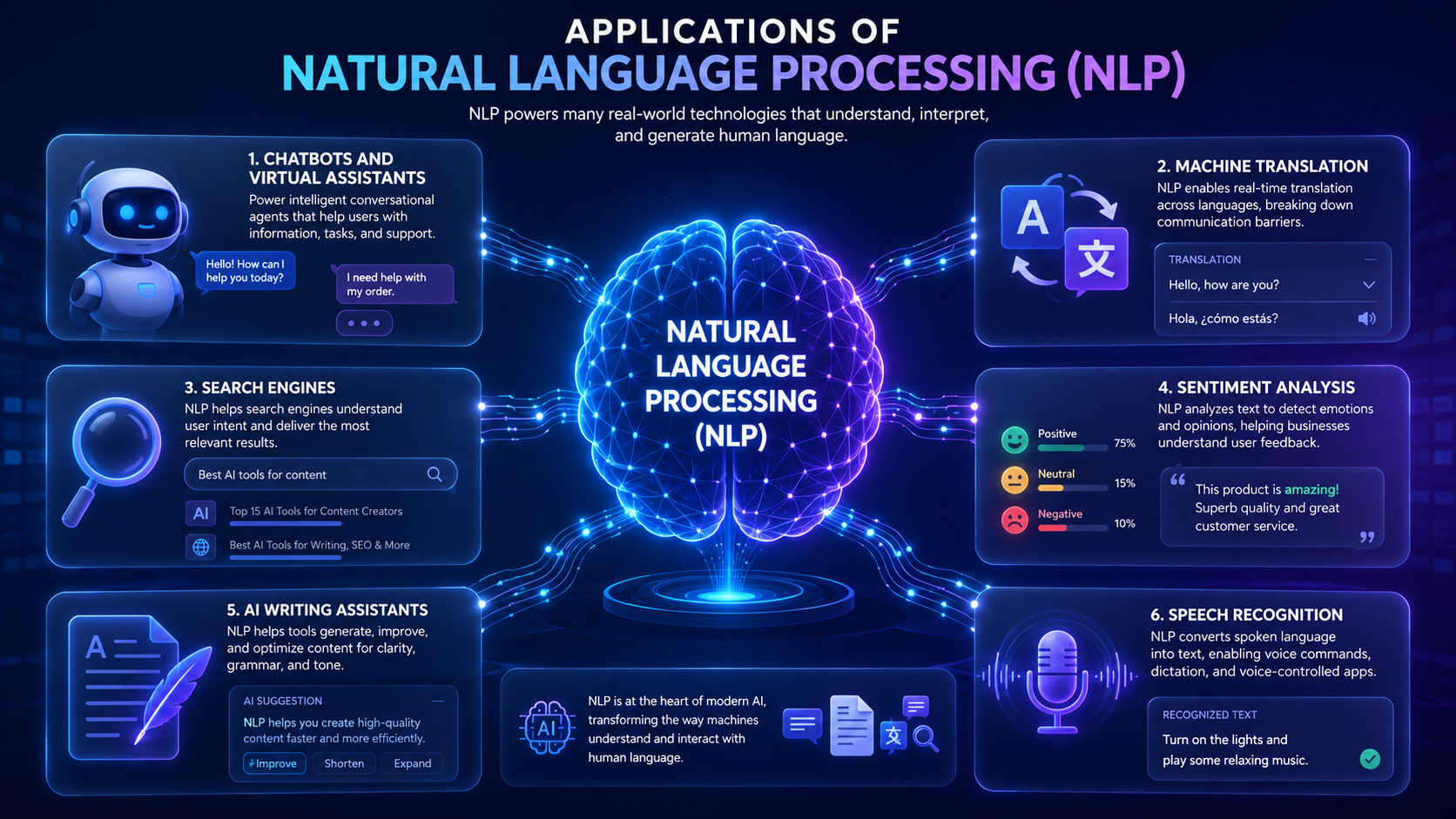
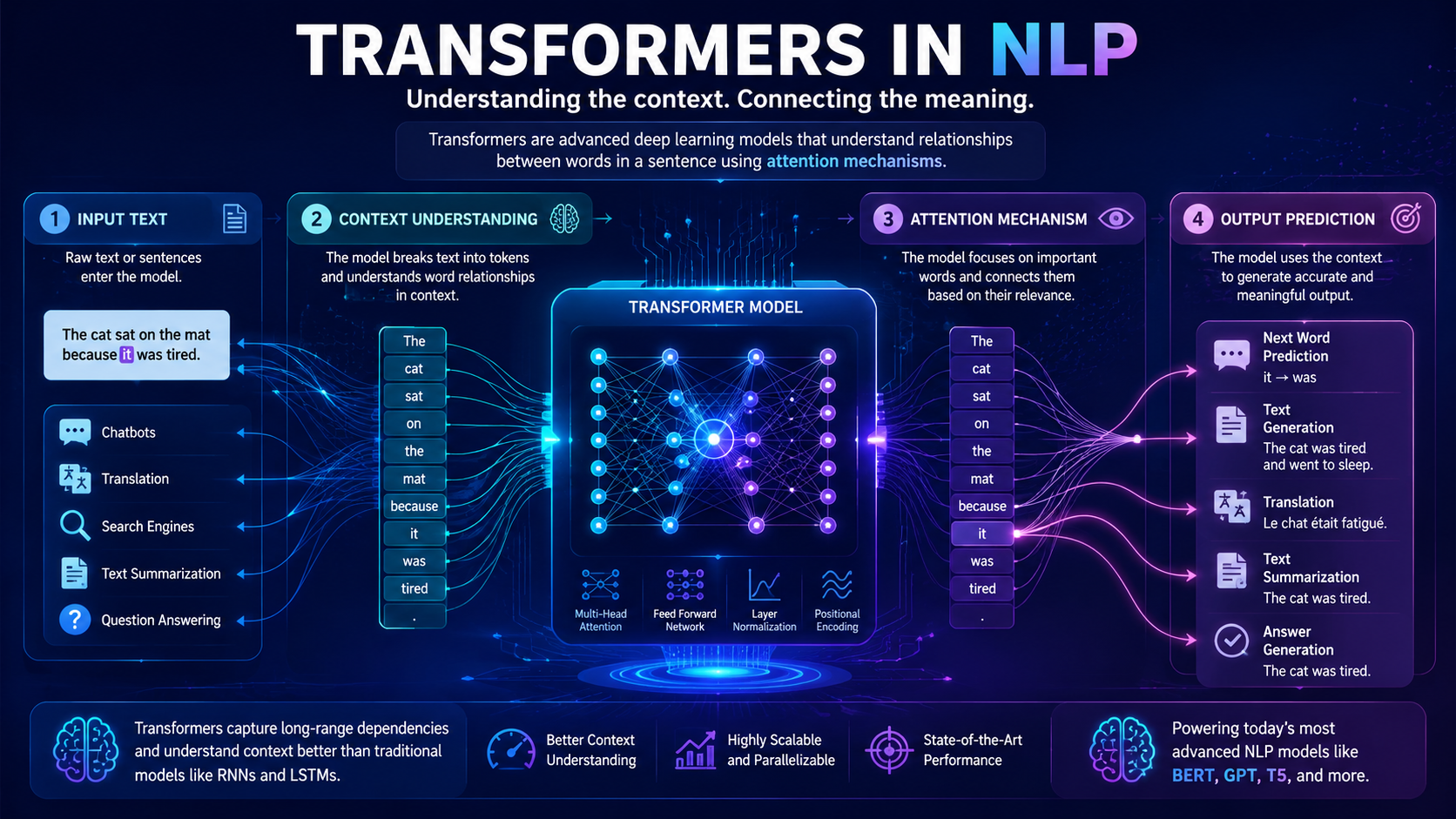
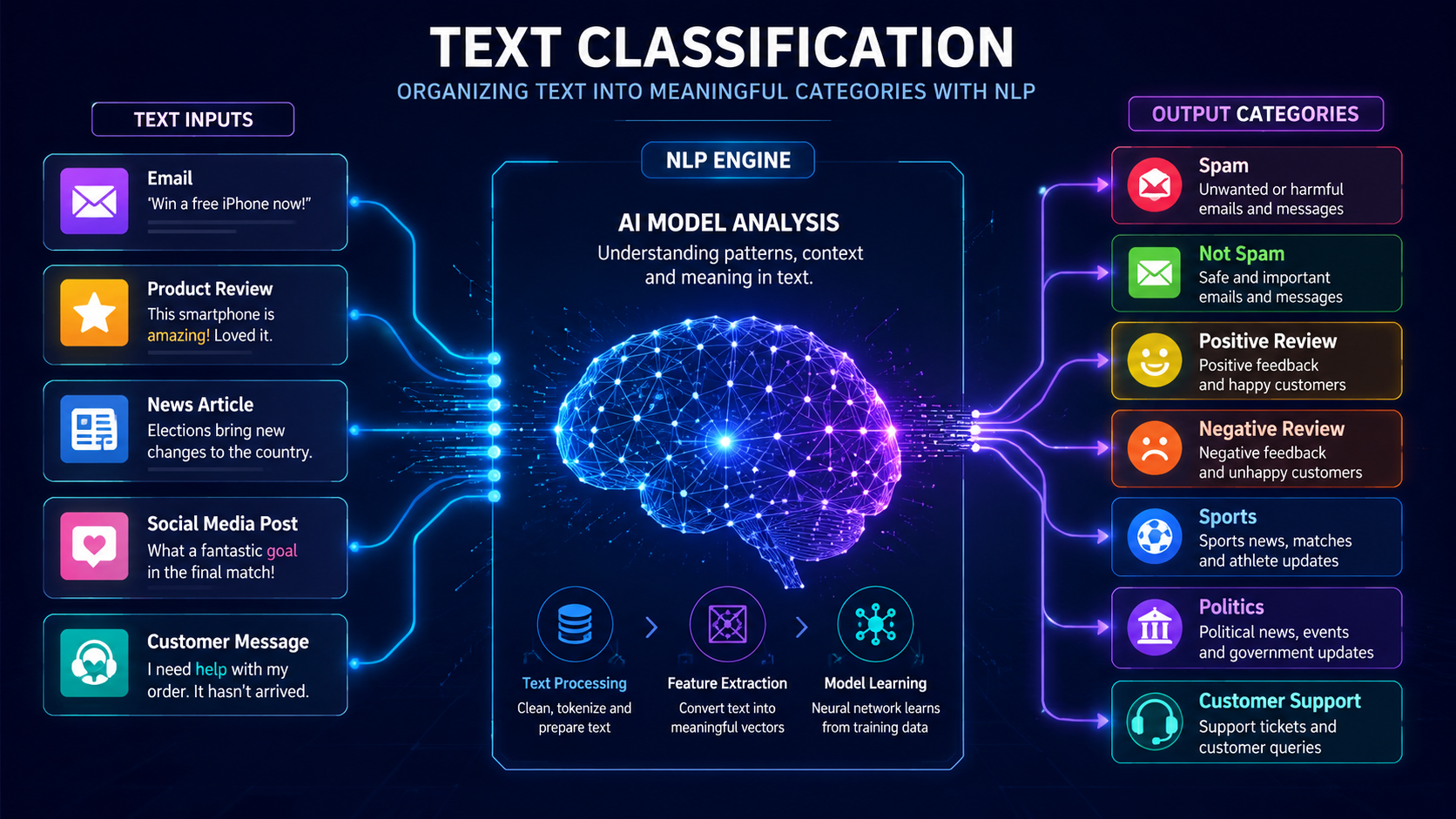
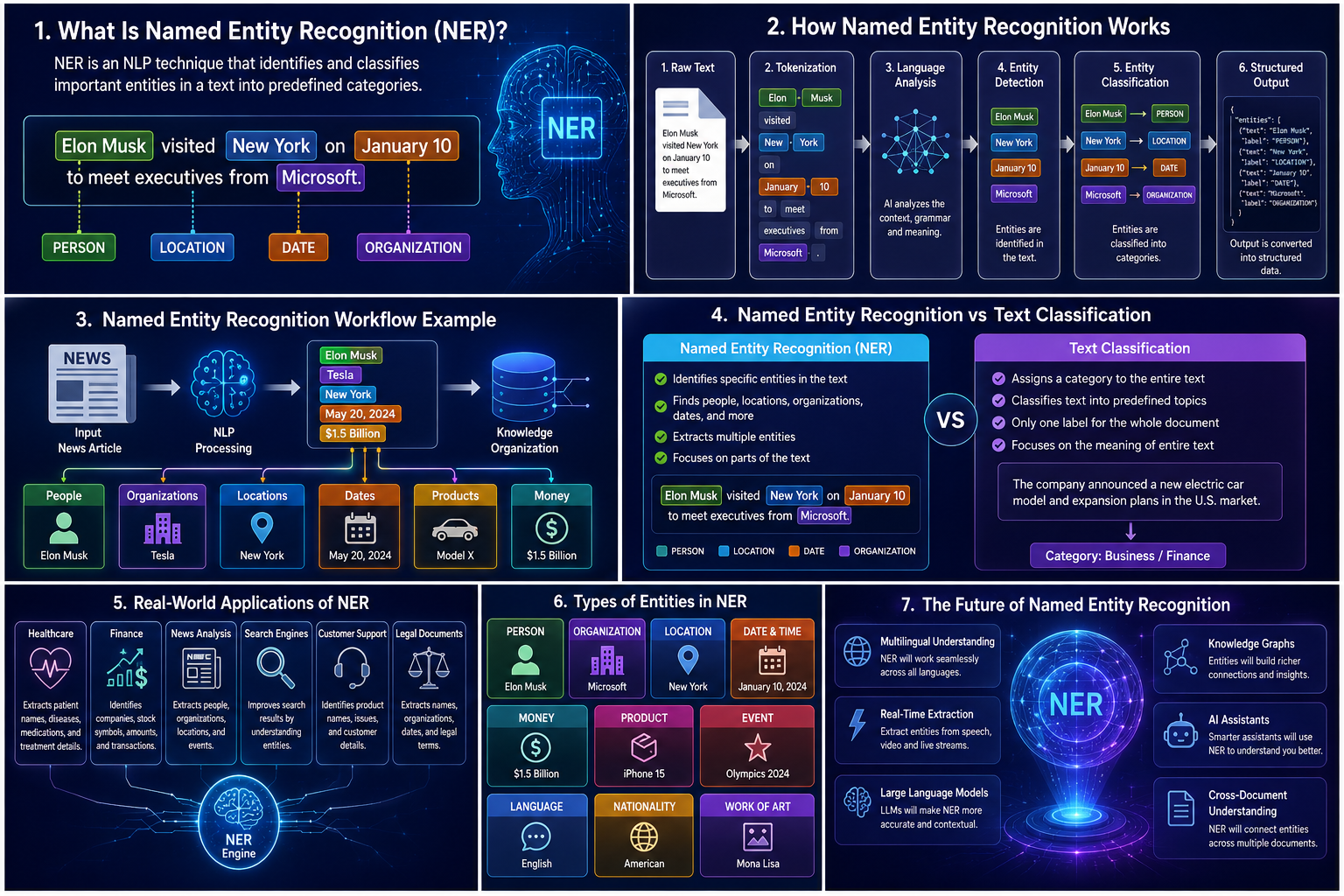
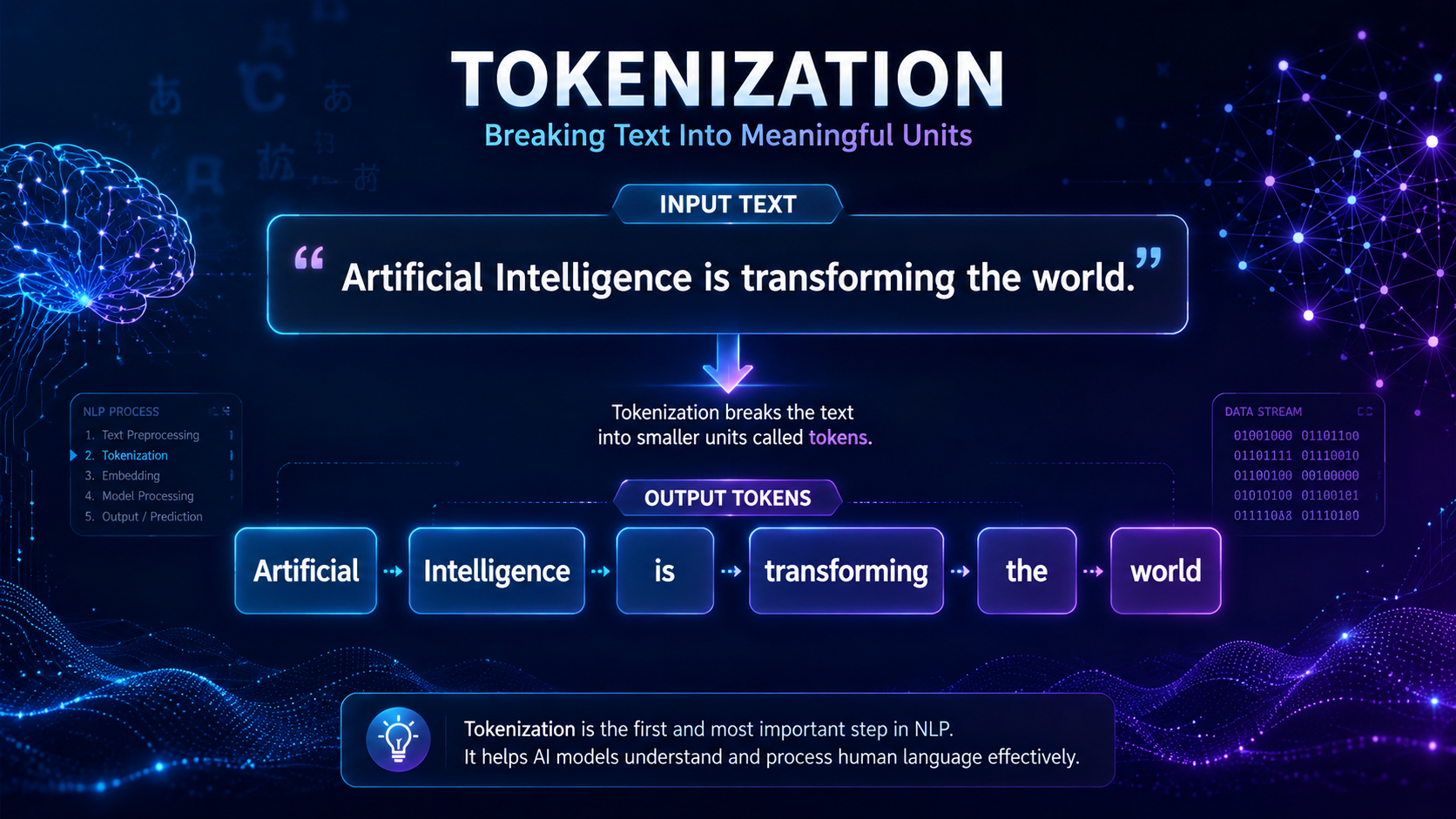
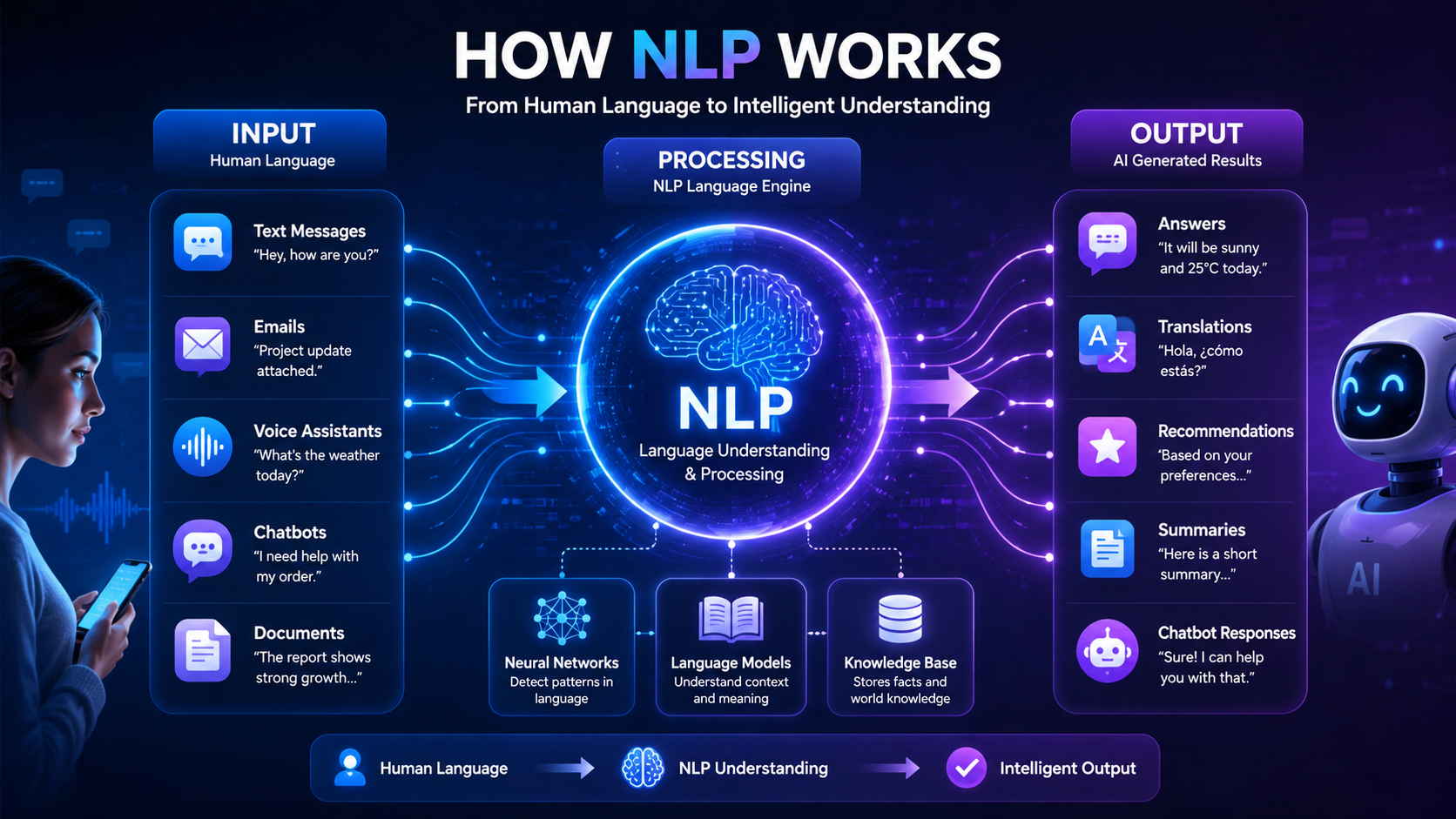
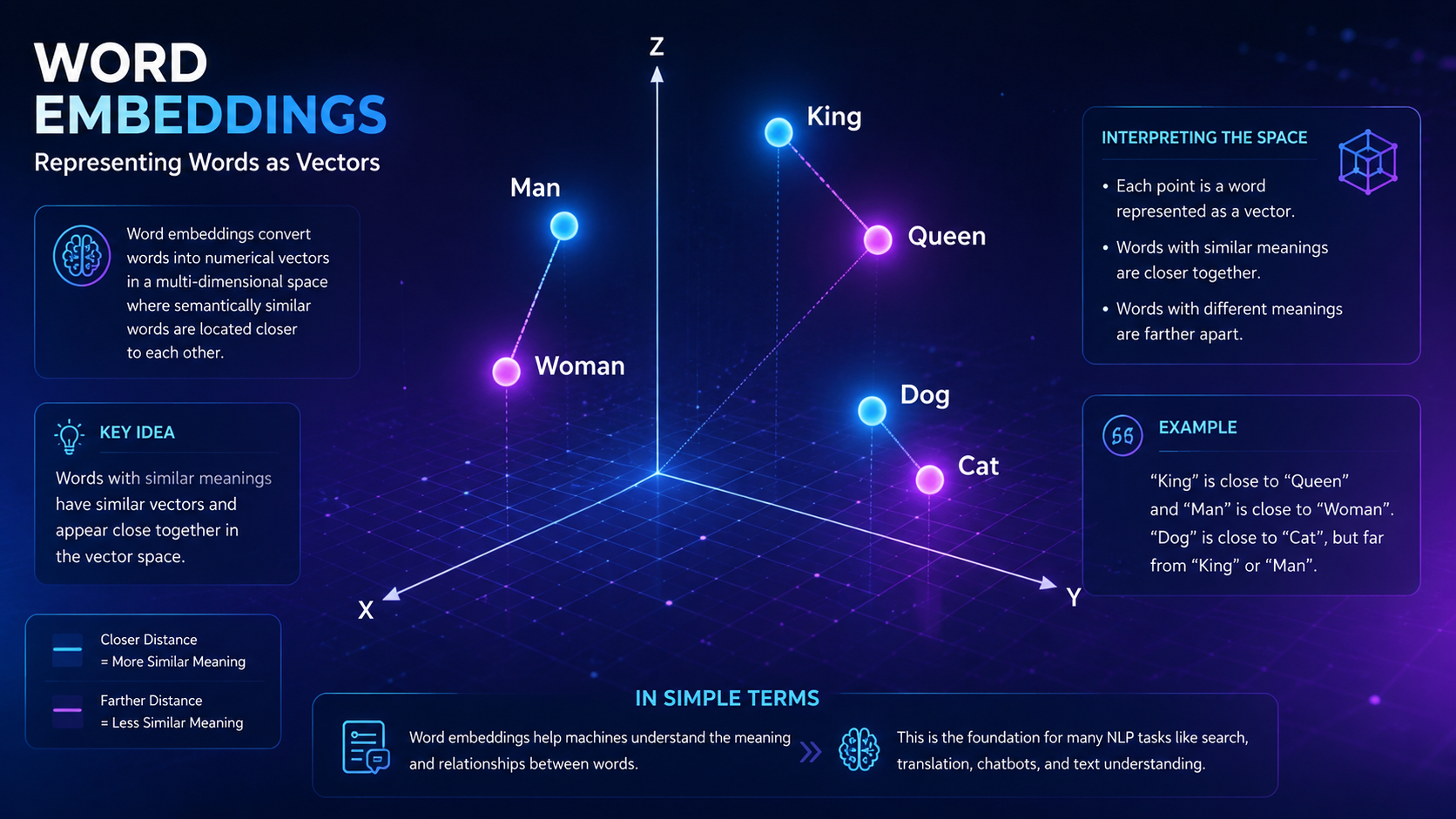
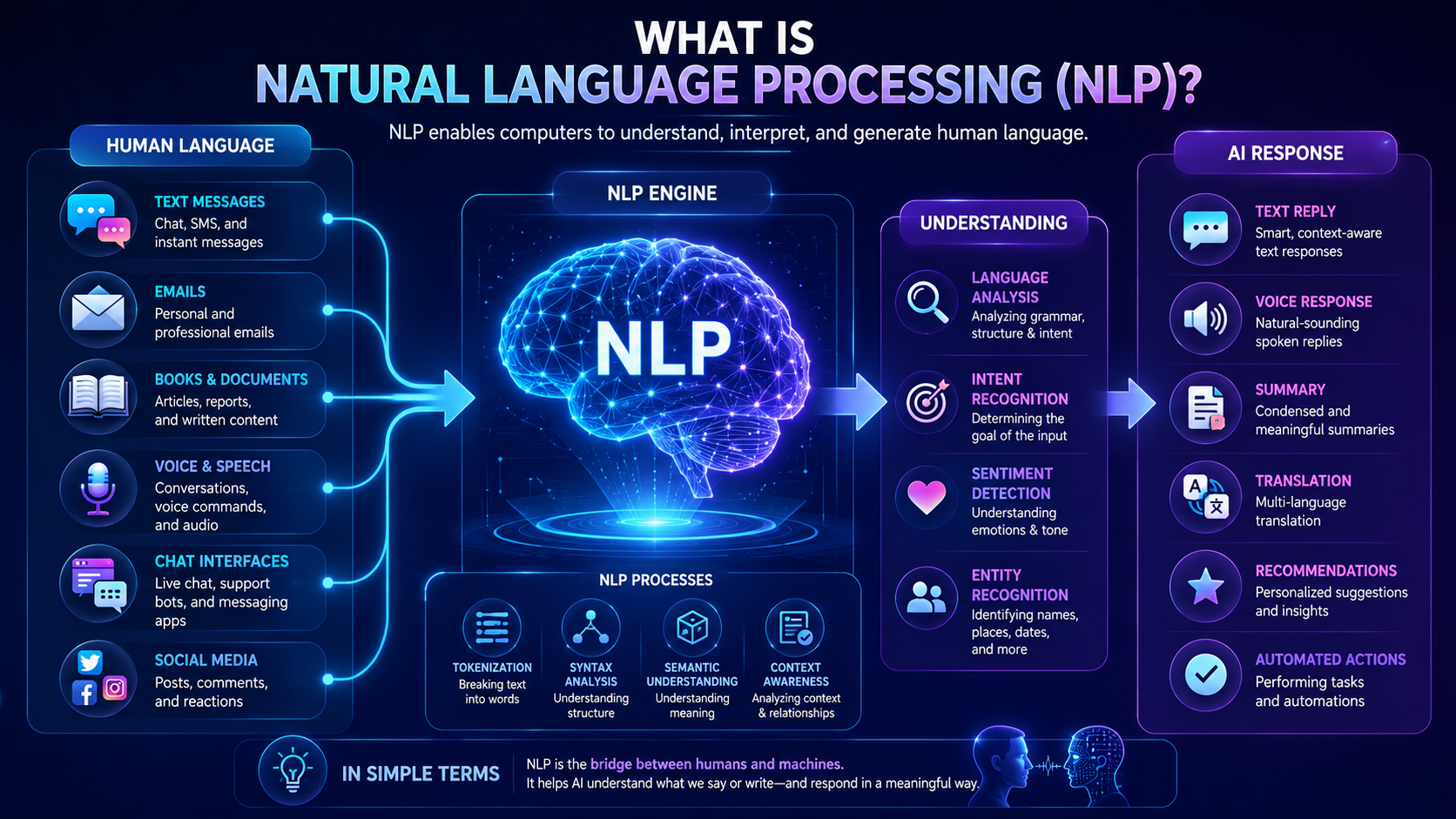
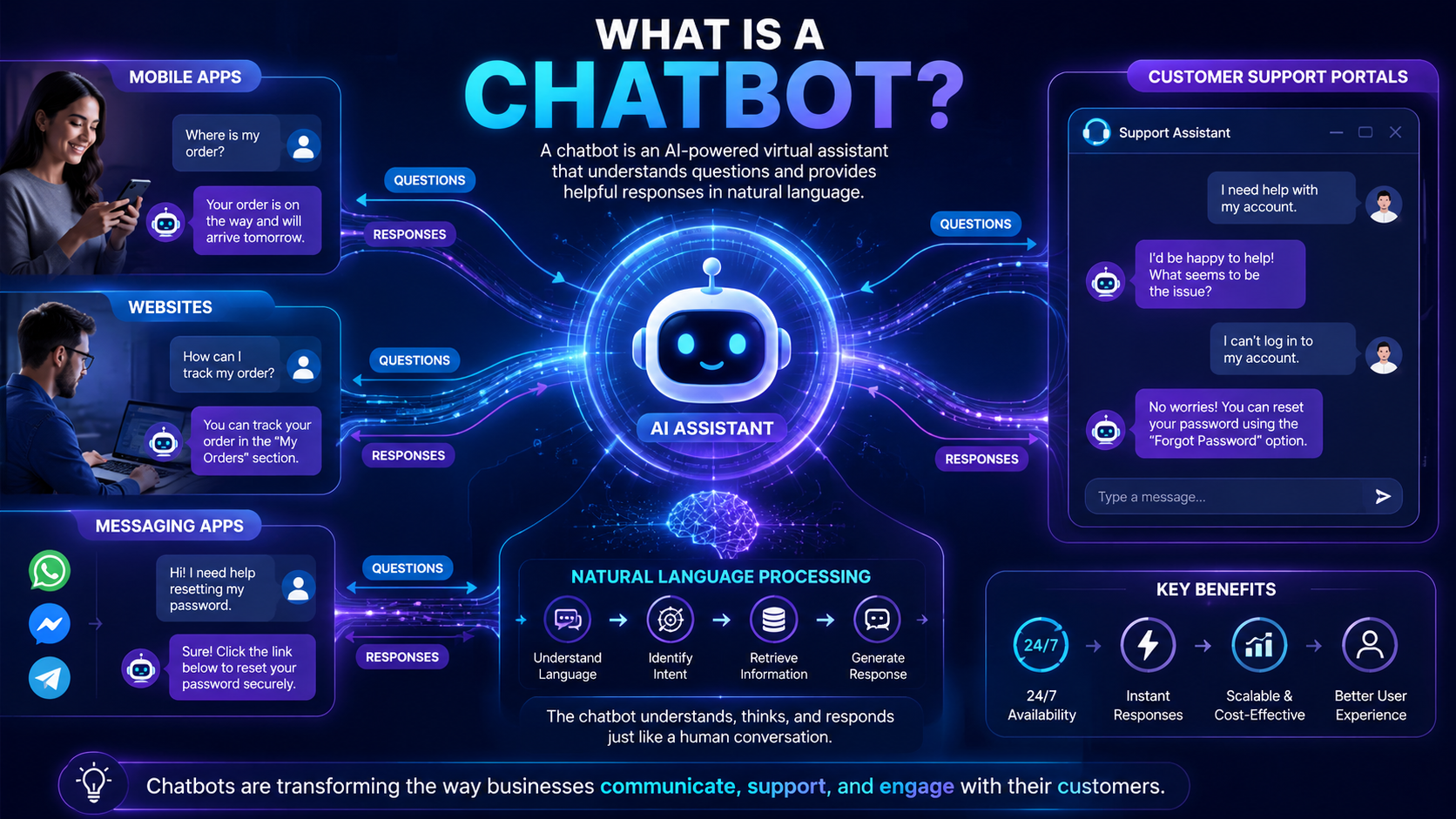
Featured Snippet Definition Chatbots are software applications that simulate human conversations through text or voice interactions. Modern chatbots use Natural Language Processing (NLP), machine learning, and artificial intelligence to understand user questions, provide helpful responses, and perform tasks automatically. Chatbots are widely used in customer support, virtual assistants, e-commerce, healthcare, education, and many other industries […]
Chatbots Explained: A Beginner’s Guide to AI-Powered Conversations Read More »