Introduction
Machine learning algorithms are the foundation of modern artificial intelligence systems. Some algorithms are designed to recognize images, others analyze text, and some predict future outcomes based on patterns in data.
One of the most powerful traditional machine learning algorithms is the Support Vector Machine (SVM).
Even though newer deep learning models often receive more attention today, Support Vector Machines remain extremely important because they can deliver highly accurate results, especially when working with smaller or medium-sized datasets.
In this beginner-friendly guide, you’ll learn:
- What Support Vector Machines are
- How SVMs work step-by-step
- Important concepts beginners should understand
- Different types of SVMs
- Real-world applications
- Advantages and limitations
- How SVMs compare to other machine learning models
- The future of Support Vector Machines in AI
If you’re new to machine learning, you may also want to read:
- Artificial Intelligence Explained
- Machine Learning Explained
- Supervised Learning Explained
- Neural Networks Explained
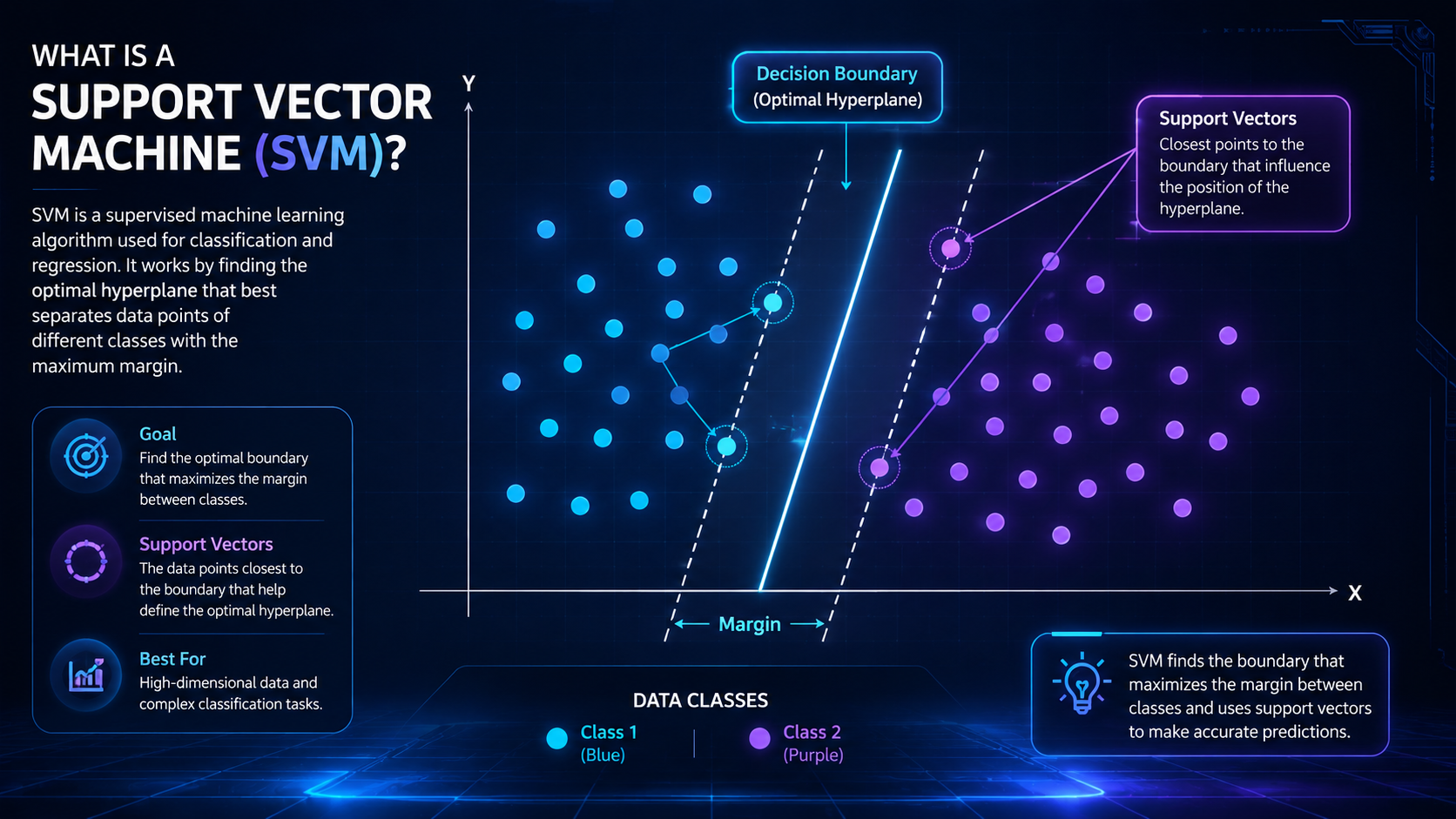
What Are Support Vector Machines?
Support Vector Machines (SVMs) are supervised machine learning algorithms used for classification and prediction tasks. They work by finding the best boundary, called a hyperplane, that separates different groups of data as clearly as possible.
Support Vector Machines are widely used in artificial intelligence for tasks like image recognition, spam detection, handwriting analysis, and medical diagnosis because they are highly effective at handling complex datasets.
Support Vector Machines are supervised learning algorithms mainly used for:
- Classification
- Pattern recognition
- Data separation
- Regression tasks in some cases
The main goal of an SVM is to separate data into categories by drawing the best possible boundary between them.
Imagine you have a dataset containing two groups:
- Cats
- Dogs
An SVM tries to find the cleanest dividing line that separates cat images from dog images.
Unlike simpler algorithms, SVMs do not just draw any line. They search for the boundary with the largest possible margin, meaning the widest distance between categories.
This helps improve prediction accuracy and reduces mistakes when classifying new data.
Support Vector Machines are supervised machine learning algorithms designed to classify data by finding the optimal boundary between categories.
Like other classification algorithms, Support Vector Machines are often evaluated using metrics such as accuracy, precision, recall, F1 score, and confusion matrices.
Support Vector Machines Analogy for Beginners
SVM as a Road Between Two Groups
Imagine two groups of people standing on opposite sides of a field.
A Support Vector Machine tries to build the widest possible road between the two groups without touching either side.
The people closest to the road determine where the road can be placed. These closest people are called:
- Support vectors
The wider the road becomes, the easier it is to clearly separate the two groups.
This is exactly how SVMs work in machine learning.
The algorithm searches for the safest and widest separation between categories so it can make more accurate predictions.
How Support Vector Machines Work
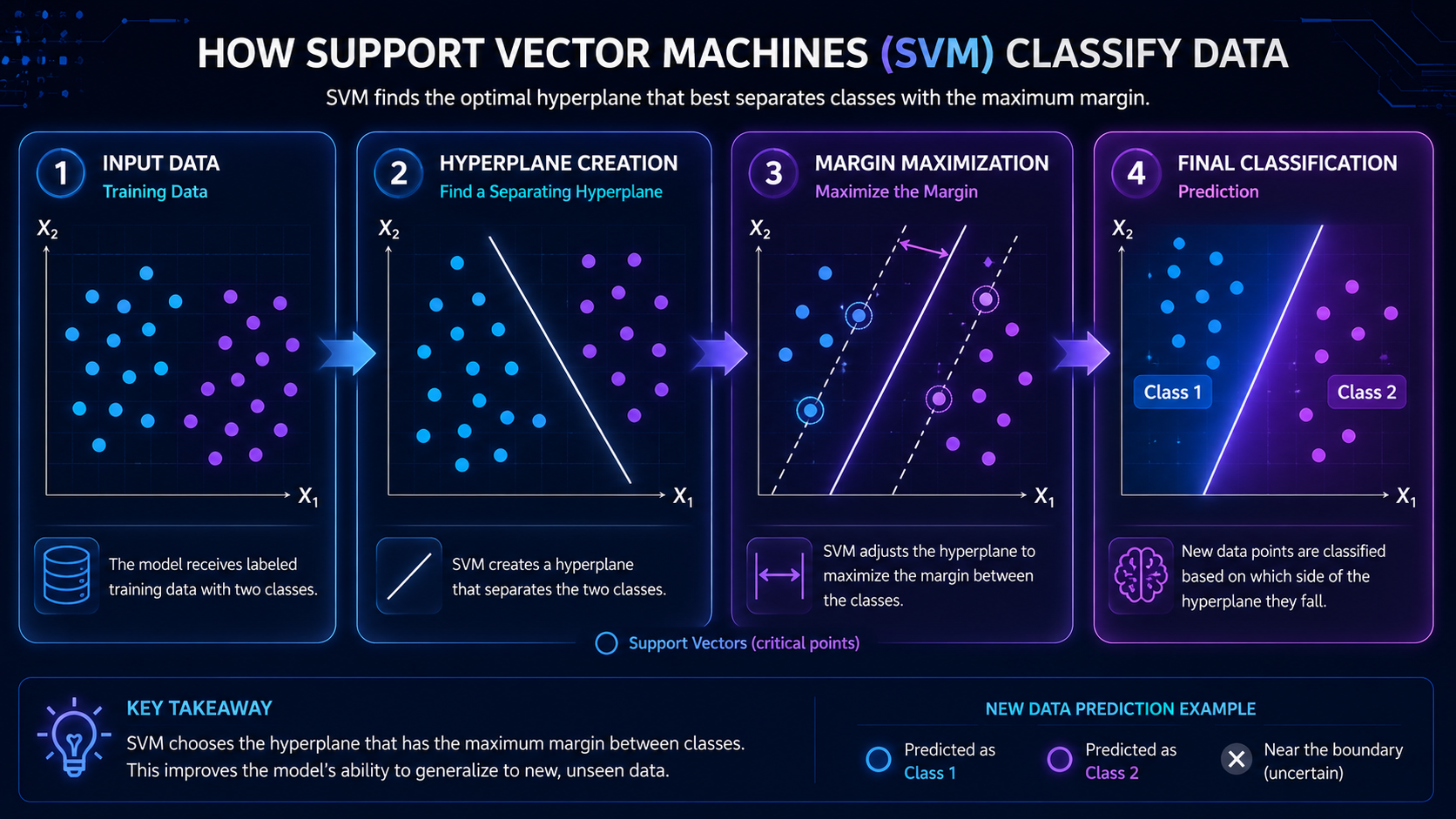
Step 1: Data Is Collected
First, the system receives labeled training data.
For example:
| Animal | Weight | Tail Length | Label |
| Cat | Small | Long | Cat |
| Dog | Large | Short | Dog |
The algorithm studies the patterns in the dataset.
Step 2: Data Is Plotted in Space
Each data point is placed into a mathematical space based on its features.
Examples of features include:
- Weight
- Size
- Shape
- Color
- Length
Each feature acts like a coordinate.
The algorithm visualizes the dataset as points in space.
Step 3: The Algorithm Finds a Boundary
The SVM searches for the best possible dividing line between categories.
This dividing boundary is called a:
Hyperplane
A hyperplane is simply the separator between groups.
In simple 2D examples, it looks like a straight line.
In more complex datasets, it becomes a multi-dimensional boundary.
Step 4: Support Vectors Are Identified
The most important data points are called:
Support Vectors
These are the points closest to the dividing boundary.
They help determine the exact position of the hyperplane.
Think of them as the “critical examples” the model uses to make decisions.
Step 5: Margin Maximization
The SVM chooses the boundary with the widest margin between groups.
A larger margin usually improves prediction accuracy on new data.
This is one reason Support Vector Machines are considered powerful classifiers.
Why Are Support Vector Machines Effective?
Support Vector Machines focus on finding the optimal boundary that separates different groups of data. Instead of simply drawing any dividing line, an SVM attempts to maximize the distance between categories.
This larger separation often helps the model make more reliable predictions when it encounters new data.
Because of this approach, SVMs have historically performed well in classification tasks involving text analysis, image recognition, and pattern detection.
What Are Kernels in Support Vector Machines?
Not all datasets can be separated using a simple straight boundary. Kernels allow Support Vector Machines to transform data into higher-dimensional spaces where categories become easier to separate.
Common kernel types include:
- Linear Kernel
- Polynomial Kernel
- Radial Basis Function (RBF) Kernel
- Sigmoid Kernel
Kernels make SVMs flexible enough to solve many real-world classification problems that would otherwise be difficult to separate.
Key Concepts Beginners Must Understand
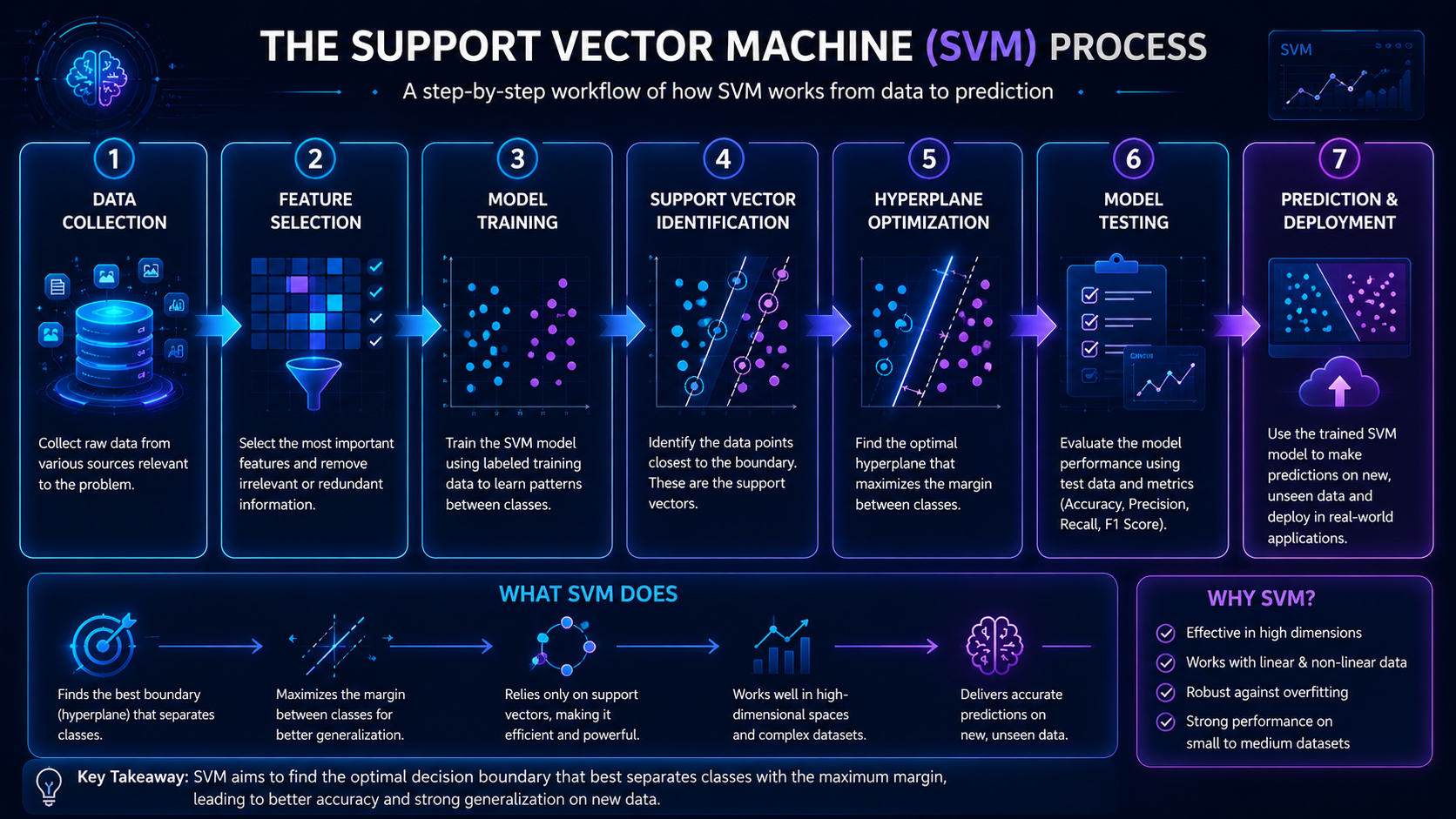
Hyperplane
A hyperplane is the decision boundary that separates categories.
Examples include:
- Spam vs non-spam emails
- Fraudulent vs legitimate transactions
- Healthy vs diseased patients
The hyperplane helps the model classify new data correctly.
Margin
The margin is the distance between the hyperplane and the nearest data points.
Support Vector Machines try to maximize this margin.
Why?
Because larger margins often improve generalization and reduce overfitting.
Support Vectors
Support vectors are the most important training examples.
These points directly influence where the hyperplane is placed.
Without support vectors, the algorithm could not determine the optimal boundary.
Kernel Functions
Sometimes data cannot be separated using a straight line.
This is where kernels become useful.
A kernel transforms data into a higher-dimensional space where separation becomes easier.
You can think of kernels like changing your viewing angle to make messy data easier to organize.
Even if the data looks impossible to separate in one dimension, kernels help reveal hidden structure.
The important beginner takeaway is:
- Kernels help Support Vector Machines solve more complex classification problems.
Types of Support Vector Machines
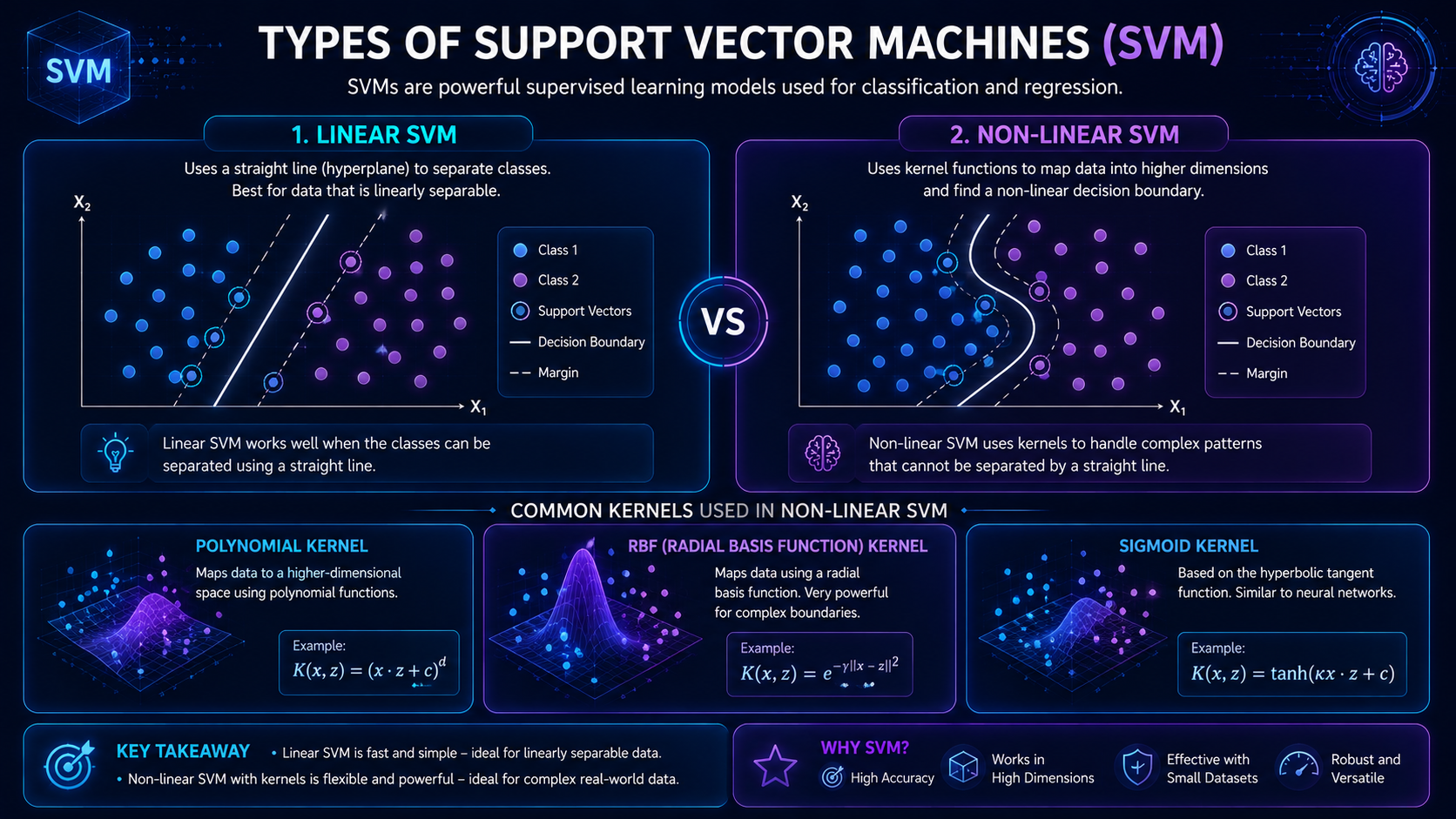
Linear SVM
Linear SVMs are used when data can be separated with a straight line.
They work well for simpler datasets.
Example
Separating:
- Spam emails
- Non-spam emails
based on simple word patterns.
Non-Linear SVM
Non-linear SVMs are used when the data is more complicated.
They use kernels to create flexible boundaries.
Example
Image recognition tasks where categories overlap heavily.
Support Vector Regression (SVR)
Although SVMs are mainly used for classification, they can also perform regression tasks.
This variation is called:
- Support Vector Regression (SVR)
SVR predicts continuous numerical values rather than categories.
Example
Predicting:
- House prices
- Stock trends
- Temperature forecasts
When Should You Use Support Vector Machines?
Support Vector Machines work best when:
- Datasets are small or medium-sized
- Accuracy is more important than speed
- Data has clear categories
- Features are well-structured
- The problem involves classification tasks
SVMs are less ideal when:
- Datasets are extremely large
- Training speed is critical
- Deep learning models are more suitable
- Massive image datasets are involved
This is why SVMs are often used alongside other machine learning approaches depending on the project.
Real-World Applications of Support Vector Machines

Healthcare and Medical Diagnosis
Support Vector Machines help detect diseases from medical data.
Examples include:
- Cancer detection
- Tumor classification
- Medical image analysis
AI-powered healthcare systems often rely on highly accurate classifiers like SVMs.
Email Spam Detection
Email services use SVMs to classify messages as:
- Spam
- Safe emails
The algorithm analyzes text patterns and sender behavior.
Facial Recognition
SVMs can identify facial patterns in images.
Applications include:
- Smartphone face unlock
- Security systems
- Identity verification
This connects closely with:
- Computer Vision Explained
- Image Classification Explained
Financial Fraud Detection
Banks use Support Vector Machines to detect suspicious transaction behavior.
The system learns patterns associated with fraudulent activity.
Handwriting Recognition
SVMs are widely used in optical character recognition (OCR).
Examples include:
- Reading handwritten forms
- Postal mail sorting
- Digit recognition systems
Cybersecurity and Anomaly Detection
Modern cybersecurity systems use SVMs to identify unusual activity patterns.
Examples include:
- Network intrusion detection
- Malware identification
- Suspicious login behavior
When Should You Use Support Vector Machines?
Support Vector Machines are often used when the goal is to classify data into different categories with high accuracy. They work especially well when datasets contain clear boundaries between groups.
SVMs are commonly used for:
- Spam email detection
- Image classification
- Facial recognition systems
- Medical diagnosis support
- Text classification
- Fraud detection
Support Vector Machines are particularly useful when working with smaller or medium-sized datasets where accurate classification is important.
For simpler classification models, see Logistic Regression Explained. For ensemble-based approaches, see Random Forest Explained.
Advantages of Support Vector Machines
| Advantage | Explanation |
| High accuracy | SVMs often perform very well on classification tasks |
| Effective in complex datasets | Kernels allow flexible separation |
| Works with smaller datasets | Unlike deep learning, SVMs do not always require huge datasets |
| Strong generalization | Margin maximization helps reduce overfitting |
| Versatile | Can perform classification and regression |
Limitations of Support Vector Machines
| Limitation | Explanation |
| Slower on large datasets | Training can become computationally expensive |
| Harder to interpret | Decision boundaries can be difficult to visualize |
| Kernel selection can be challenging | Choosing the wrong kernel reduces performance |
| Not ideal for massive image datasets | Deep learning often performs better |
| Requires feature scaling | Data preprocessing is important |
To better understand model performance, explore:
Support Vector Machines vs Related Concepts
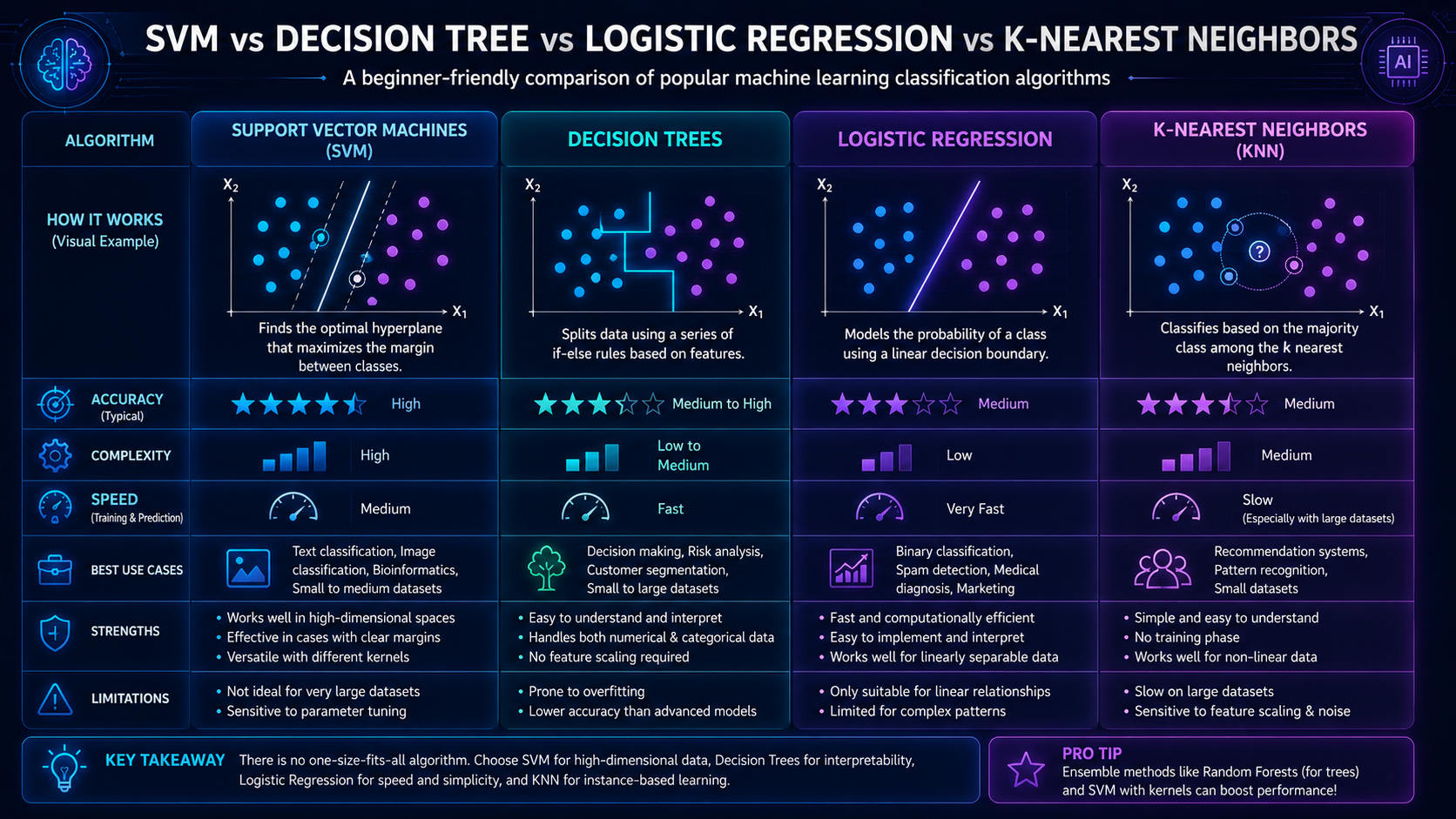
Support Vector Machines vs Neural Networks
| Feature | SVM | Neural Networks |
| Best for | Smaller structured datasets | Large complex datasets |
| Training complexity | Moderate | High |
| Data requirements | Lower | Higher |
| Interpretability | Moderate | Lower |
| Common use | Classification | Deep learning tasks |
SVMs are traditional machine learning algorithms, while neural networks power modern deep learning systems.
Related topics:
Support Vector Machines vs Decision Trees
| Feature | SVM | Decision Tree |
| Boundary type | Mathematical hyperplane | Rule-based splits |
| Accuracy | Often higher | Easier to interpret |
| Flexibility | Strong with kernels | Strong for simple logic |
| Complexity | More mathematical | More visual |
Support Vector Machines vs Logistic Regression
| Feature | SVM | Logistic Regression |
| Main goal | Maximize margin | Estimate probabilities |
| Handles complex boundaries | Better | More limited |
| Computational cost | Higher | Lower |
| Simplicity | More advanced | Easier to understand |
You may also enjoy reading:
- Logistic Regression Explained
- Decision Trees Explained
- K-Nearest Neighbors Explained
- Machine Learning Algorithms Overview
Support Vector Machines Compared to Other Algorithms
| Algorithm | Primary Use | Key Strength |
| Logistic Regression | Classification | Simplicity and interpretability |
| Decision Trees | Classification and regression | Easy-to-understand decision making |
| Random Forest | Ensemble prediction | Strong accuracy and stability |
| Support Vector Machines | Classification | Effective decision boundaries |
| Neural Networks | Pattern recognition | Complex data relationships |
Support Vector Machines are often chosen when classification accuracy is a priority and the data contains clear patterns that can be separated by decision boundaries.
Future Outlook of Support Vector Machines
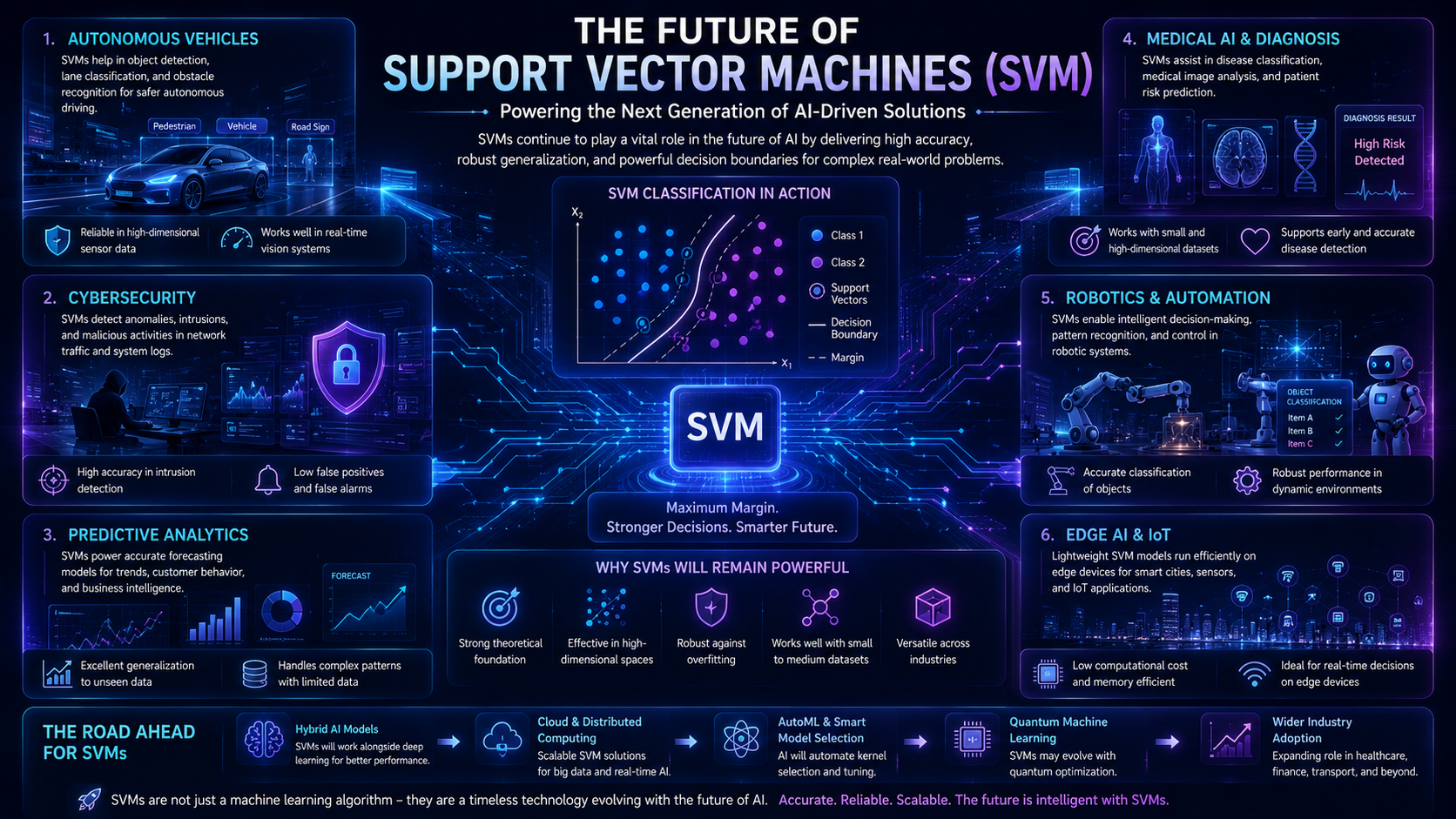
Support Vector Machines may not dominate headlines like deep learning models, but they still remain highly valuable.
In the future, SVMs will likely continue being used for:
- Medical diagnostics
- Cybersecurity systems
- Fraud detection
- Edge AI devices
- Lightweight AI applications
As AI becomes more efficient, smaller algorithms like SVMs may become increasingly useful for systems with limited computing power.
While deep learning models handle huge datasets better, Support Vector Machines still offer excellent accuracy for many practical business and scientific applications.
Although Deep Learning and Neural Networks dominate many modern AI applications, Support Vector Machines continue to be valuable for classification tasks involving smaller datasets and well-defined patterns. Their strong mathematical foundation and reliable performance ensure they remain an important tool in machine learning.
SVMs are still widely used in fields such as healthcare, cybersecurity, image analysis, and text classification where accurate decision boundaries are critical.
FAQ About Support Vector Machines
What is a Support Vector Machine in simple terms?
A Support Vector Machine is a machine learning algorithm that separates data into categories using the best possible boundary.
Why are Support Vector Machines important?
They provide highly accurate classification results and work well on many real-world AI problems.
Are Support Vector Machines supervised learning algorithms?
Yes. SVMs learn from labeled training data, making them supervised learning algorithms.
What are support vectors?
Support vectors are the data points closest to the decision boundary that help define the model.
What is a hyperplane in SVM?
A hyperplane is the boundary that separates different categories of data.
What are kernels in Support Vector Machines?
Kernels help SVMs solve complex problems by transforming data into higher-dimensional space.
Can Support Vector Machines handle non-linear data?
Yes. Non-linear SVMs use kernels to separate more complicated datasets.
Is SVM better than logistic regression?
SVMs often perform better on complex classification tasks, while logistic regression is simpler and easier to interpret.
Are Support Vector Machines still used today?
Yes. They are widely used in healthcare, cybersecurity, finance, and text classification systems.
Can SVMs be used for regression?
Yes. A variation called Support Vector Regression (SVR) is used for prediction tasks.
Are Support Vector Machines supervised or unsupervised learning?
Support Vector Machines are supervised learning algorithms because they learn from labeled training data to classify or predict outcomes.
Conclusion
Support Vector Machines are one of the most important traditional machine learning algorithms in artificial intelligence.
They are designed to separate data using optimal boundaries and are especially powerful for classification problems.
Even in the era of deep learning, SVMs remain highly valuable because they:
- Deliver strong accuracy
- Work well with smaller datasets
- Handle complex patterns using kernels
- Support both classification and regression tasks
Understanding Support Vector Machines gives beginners a strong foundation for learning more advanced machine learning concepts.
Recommended Next Topics
Continue learning with:
- Machine Learning Explained
- Supervised Learning Explained
- Unsupervised Learning Explained
- Reinforcement Learning Explained
- Neural Networks Explained
- Deep Learning Explained
- Model Evaluation Metrics Explained
- Overfitting vs Underfitting
- Machine Learning Algorithms Overview
- Logistic Regression Explained
- Decision Trees Explained
- Random Forest Explained
- Accuracy vs Precision vs Recall
- Confusion Matrix Explained
- Cross-Validation Explained
Suggested External Resources
- Learn more from IBM’s guide to machine learning
- Explore Google’s Machine Learning Crash Course for beginner-friendly AI education