Introduction
One of the biggest goals in artificial intelligence and machine learning is helping computers identify patterns inside massive amounts of data. Sometimes AI systems learn using labeled examples, but in many real-world situations, there are no labels available.
This is where K-Means Clustering becomes extremely useful.
K-Means Clustering is one of the most widely used algorithms in Unsupervised Learning Explained because it helps machines organize data into groups based on similarity. Businesses, researchers, and AI systems use it to discover hidden structures, customer behaviors, trends, and relationships inside datasets.
For beginners learning about Machine Learning Explained, K-Means Clustering is one of the easiest and most practical algorithms to understand because the concept is highly visual and intuitive.
In this guide, you will learn:
- What K-Means Clustering is
- How it works step-by-step
- Important concepts beginners should understand
- Why clustering matters in AI
- Real-world applications
- Advantages and limitations
- Common beginner mistakes
- How it compares to related machine learning concepts
- The future of clustering in AI
What Is K-Means Clustering?
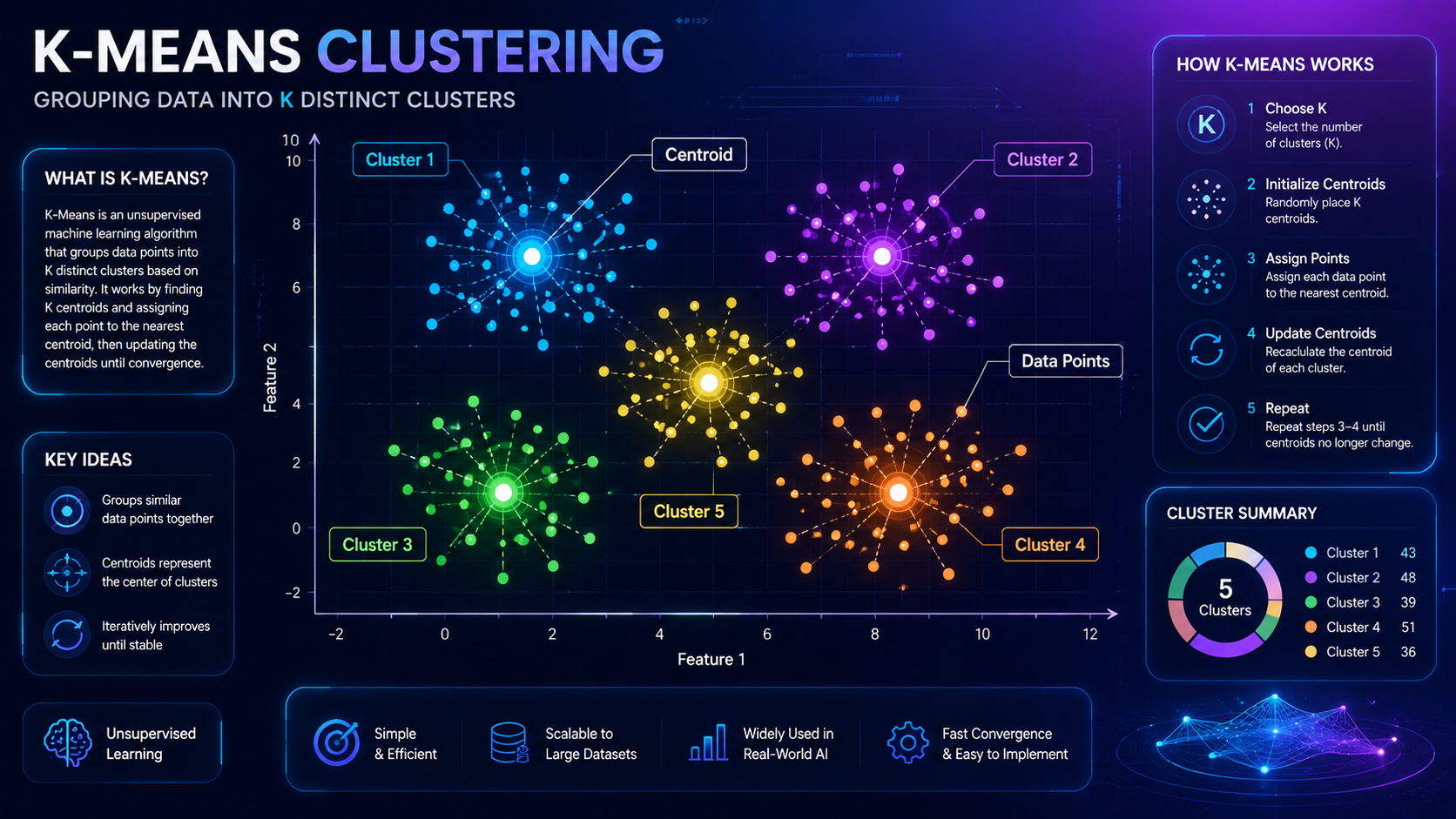
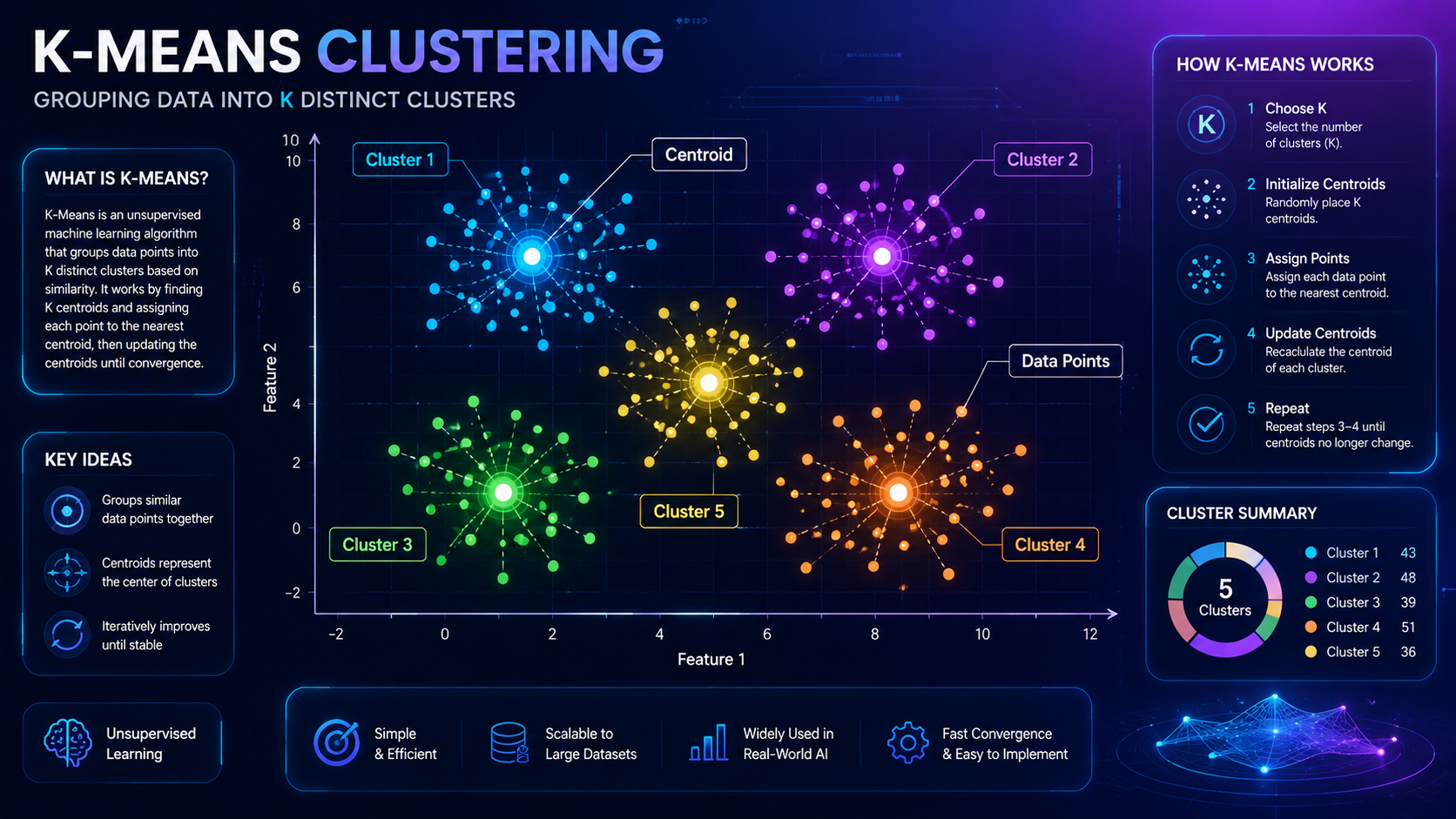
K-Means Clustering is a popular unsupervised machine learning algorithm that groups similar data points into clusters. It helps AI systems discover hidden patterns in data without needing labeled examples.
K-Means Clustering is widely used in customer segmentation, recommendation systems, fraud detection, image processing, and many other real-world AI applications because it organizes data into meaningful groups automatically.
A “cluster” is simply a collection of items that are similar to one another.
For example, imagine an online store analyzing customer behavior. Some customers buy luxury products, some purchase discounted items, and others shop frequently. K-Means Clustering can automatically group these customers based on their shopping patterns.
Unlike Supervised Learning Explained, K-Means does not require labeled training data. Instead, the algorithm discovers patterns on its own.
That is why K-Means belongs to the category of unsupervised learning.
K-Means is considered one of the most important beginner-friendly clustering algorithms because it is:
- Simple to understand
- Fast to process
- Easy to visualize
- Widely used in real-world AI systems
K-Means Clustering is one of the most widely used unsupervised machine learning algorithms for grouping similar data points into clusters.
Why K-Means Clustering Matters in AI
Modern AI systems generate enormous amounts of data every day. Much of this data is unlabeled, meaning humans have not categorized or organized it yet.
K-Means Clustering helps AI systems automatically identify hidden structures inside that data.
This is important because clustering can help:
- Organize customer behaviors
- Improve recommendation systems
- Detect unusual activity
- Analyze images
- Group similar documents
- Discover patterns humans may miss
Many advanced AI systems combine clustering with technologies like Deep Learning Explained and Neural Networks Explained to improve performance and automate decision-making.
Even though K-Means is one of the oldest machine learning algorithms, it remains highly important in modern artificial intelligence.
How K-Means Clustering Works
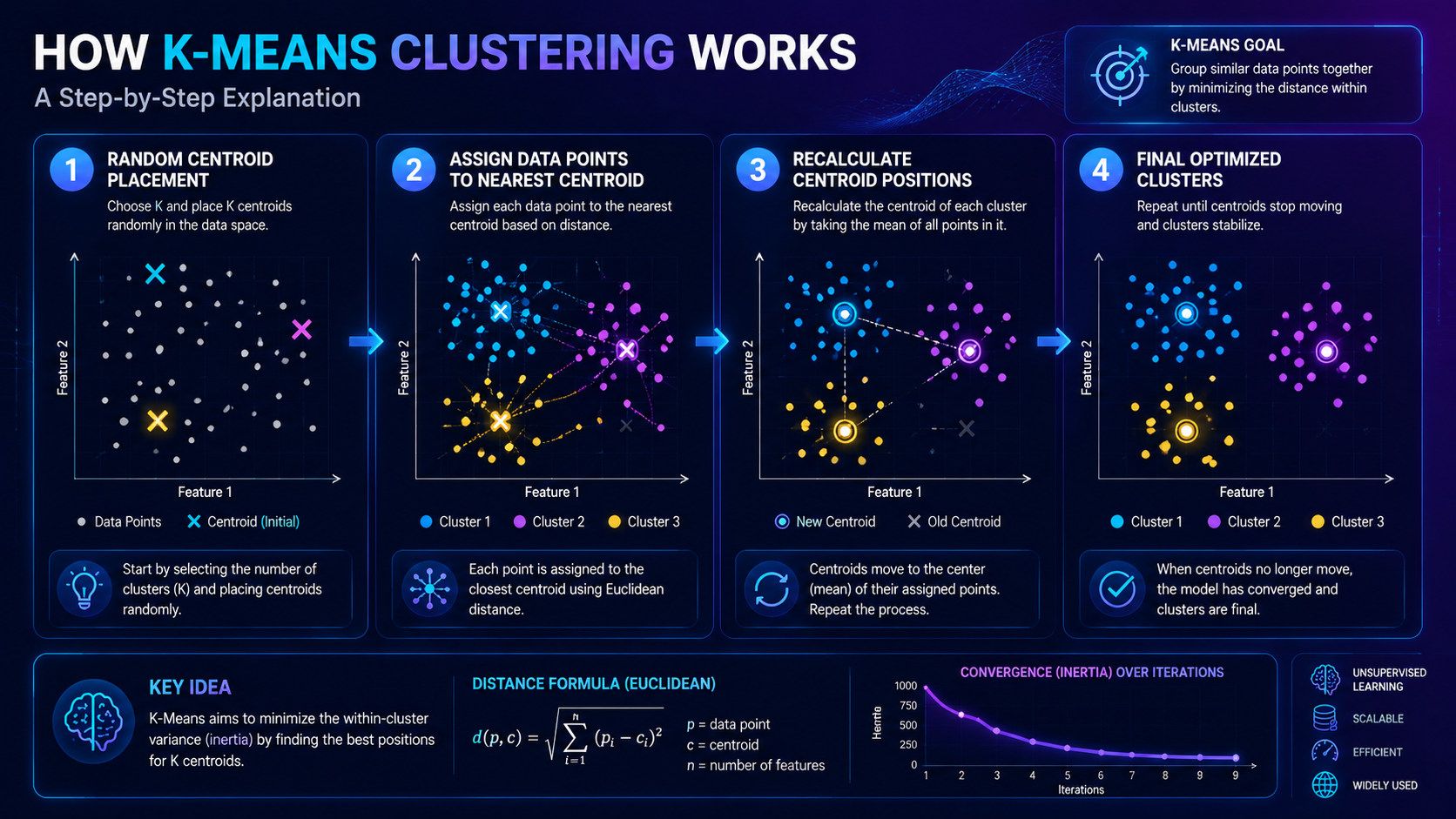
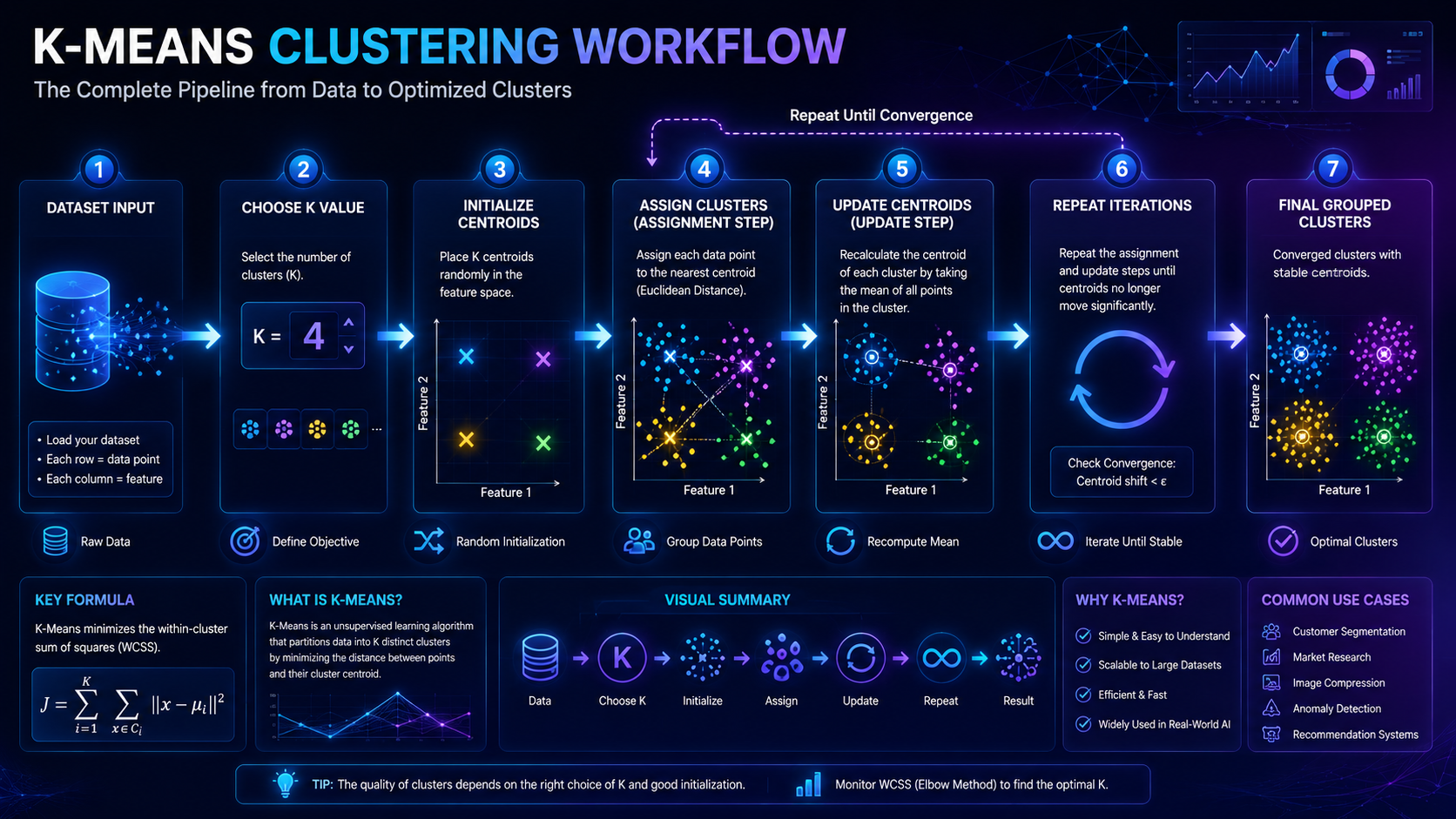
K-Means Clustering works by repeatedly organizing data points into groups until the clusters become stable.
Step 1: Choose the Number of Clusters (K)
Step 1: Choose the Number of Clusters (K)
The “K” in K-Means represents the number of clusters the algorithm should create.
For example:
- K = 2 creates two groups
- K = 3 creates three groups
- K = 5 creates five groups
Choosing the correct K value is one of the most important parts of clustering.
Step 2: Place Initial Centroids
The algorithm randomly places points called centroids.
A centroid represents the center of a cluster.
You can think of a centroid as the “middle point” of a group.
Step 3: Assign Data Points to the Closest Centroid
Each data point is assigned to the nearest centroid based on similarity or distance.
For example:
- Similar customers move into the same group
- Similar products become clustered together
- Similar images form categories
The closer two data points are, the more similar the algorithm assumes they are.
Step 4: Update the Centroids
After assigning data points to clusters, the algorithm recalculates the center of each group.
The centroid moves to the new average position of all points inside the cluster.
Step 5: Repeat Until Stable
The algorithm repeats the grouping and updating process multiple times until the clusters stop changing significantly.
At this point, the model has found stable patterns in the data.
Why Is the Value of K Important?
The value of K determines how many clusters the algorithm will create.
For example:
- K = 2 creates two clusters.
- K = 5 creates five clusters.
- K = 10 creates ten clusters.
Choosing too few clusters may oversimplify the data, while choosing too many clusters can create unnecessary complexity.
Selecting the right value of K is one of the most important steps when using K-Means Clustering.
What Is the Elbow Method?
The Elbow Method is a technique used to help determine the optimal number of clusters for a K-Means model.
The process involves running the algorithm multiple times using different values of K and measuring how well the clusters fit the data.
When plotted on a graph, the results often form an “elbow” shape. The point where improvements begin to slow significantly is typically chosen as the ideal value of K.
The Elbow Method is one of the most widely used approaches for selecting the number of clusters in K-Means Clustering.
Clustering vs Classification
Clustering and classification are both ways of organizing data, but they serve different purposes.
- Classification predicts predefined categories using labeled data.
- Clustering discovers hidden groups without predefined labels.
Algorithms such as Logistic Regression, Decision Trees, and Random Forest are classification algorithms, while K-Means is a clustering algorithm.
This distinction is one of the key differences between supervised and unsupervised learning.
Example Cluster Visualization
Imagine plotting customer shopping behavior on a graph.
K-Means Clustering might organize customers into groups such as:
- Budget shoppers
- Luxury shoppers
- Frequent buyers
The algorithm automatically places centroids near the center of each group and continuously adjusts them until the customer clusters become organized.
This visual grouping process is one reason K-Means is often one of the first algorithms taught in beginner machine learning courses.
Key Concepts Beginners Must Understand
Centroids
A centroid is the center point of a cluster.
The algorithm constantly updates centroids to improve grouping accuracy.
Distance Measurement
K-Means uses distance calculations to determine similarity between data points.
Points located closer together are considered more similar.
Beginners do not need to focus heavily on the math. The important idea is that K-Means groups nearby items together.
Iteration
K-Means works iteratively, meaning it repeats the same steps multiple times until the results improve and stabilize.
Many AI systems use iterative learning processes.
Cluster Quality
Good clustering means:
- Similar items stay together
- Different groups remain separated
Poor clustering creates overlapping or confusing groups.
Choosing the Right K Value
One challenge in K-Means is selecting the correct number of clusters.
Too few clusters may combine unrelated data.
Too many clusters may split useful groups unnecessarily.
A common technique called the Elbow Method helps estimate a good K value by testing multiple cluster counts.
Important Parts of K-Means Clustering
Data Preprocessing
Clean data improves clustering performance.
This often includes:
- Removing missing values
- Scaling numerical data
- Reducing noise
- Standardizing features
This connects closely with Data Preprocessing Explained and Feature Engineering Explained.
Feature Selection
The features chosen for clustering strongly affect the final results.
Examples include:
- Customer age
- Purchase history
- Website activity
- Product preferences
Choosing useful features helps the algorithm identify meaningful patterns.
Initialization Methods
Different starting centroid locations can produce different results.
Modern AI systems often use improved initialization methods such as K-Means++ to increase stability and accuracy.
Real-World Applications of K-Means Clustering

K-Means Clustering is used across many industries and AI systems.
| Industry | Example Application |
| E-commerce | Customer segmentation |
| Streaming Services | Movie and music recommendations |
| Banking | Fraud detection |
| Healthcare | Patient grouping and diagnosis support |
| Marketing | Audience targeting |
| Cybersecurity | Detecting unusual activity |
| Social Media | Topic and trend analysis |
| Image Processing | Color grouping and compression |
Customer Segmentation
Businesses use clustering to organize customers based on:
- Spending habits
- Shopping behavior
- Interests
- Demographics
This helps companies improve marketing and personalization.
Recommendation Systems
Platforms like Netflix, YouTube, and Amazon use clustering to recommend products or content to similar users.
Fraud Detection
Banks use clustering to identify transactions that behave differently from normal patterns.
Healthcare Applications
Hospitals use clustering to group patients with similar symptoms or medical histories to improve diagnosis and treatment planning.
When Should You Use K-Means Clustering?
K-Means Clustering is useful when you want to discover hidden groups or patterns within data without providing predefined labels.
Unlike supervised learning algorithms, K-Means does not require labeled training data. Instead, it automatically identifies similarities between data points and groups them into clusters.
Common use cases include:
- Customer segmentation
- Market research
- Recommendation systems
- Fraud detection
- Image compression
- Social network analysis
K-Means is often chosen because it is relatively simple, fast, and effective for discovering structure within large datasets.
For other unsupervised learning techniques, see Hierarchical Clustering Explained and Unsupervised Learning Explained.
Advantages of K-Means Clustering
| Advantage | Explanation |
| Beginner-Friendly | Easy to understand and visualize |
| Fast Processing | Works efficiently on large datasets |
| Scalable | Can handle large amounts of data |
| Useful for Pattern Discovery | Identifies hidden structures in data |
| Widely Used | Common across many industries |
Limitations of K-Means Clustering
| Limitation | Explanation |
| Requires Choosing K | Users must decide the number of clusters beforehand |
| Sensitive to Initialization | Different starting centroids can affect results |
| Sensitive to Outliers | Extreme values may distort cluster centers |
| Struggles With Complex Shapes | Works best with round-shaped clusters |
| Assumes Similar Cluster Sizes | Uneven groups can reduce accuracy |
Why Is Data Preprocessing Important for K-Means?
K-Means relies on distance calculations to determine which data points belong to each cluster.
If some features have much larger numerical values than others, they can dominate the clustering process and produce misleading results.
Techniques such as normalization and standardization help ensure that all features contribute fairly when clusters are created.
To learn more, see Data Preprocessing Explained and Feature Engineering Explained.
Common Beginner Mistakes With K-Means
Choosing the Wrong K Value
Using too many or too few clusters can produce misleading results.
Ignoring Data Scaling
Large numerical values can distort clustering behavior if the data is not standardized properly.
Expecting Perfect Clusters
Real-world data is often messy, overlapping, and imperfect.
K-Means works best when the data naturally forms clear groups.
Using Poor Features
If the selected data features are not useful, the clusters may not represent meaningful patterns.
K-Means Clustering vs Related Concepts
K-Means vs Supervised Learning
| K-Means Clustering | Supervised Learning |
| Uses unlabeled data | Uses labeled data |
| Finds hidden patterns | Predicts known outputs |
| Groups similar items | Learns from examples |
| Part of unsupervised learning | Part of supervised learning |
K-Means is commonly introduced after learning about Supervised Learning Explained and Unsupervised Learning Explained.
K-Means vs Hierarchical Clustering
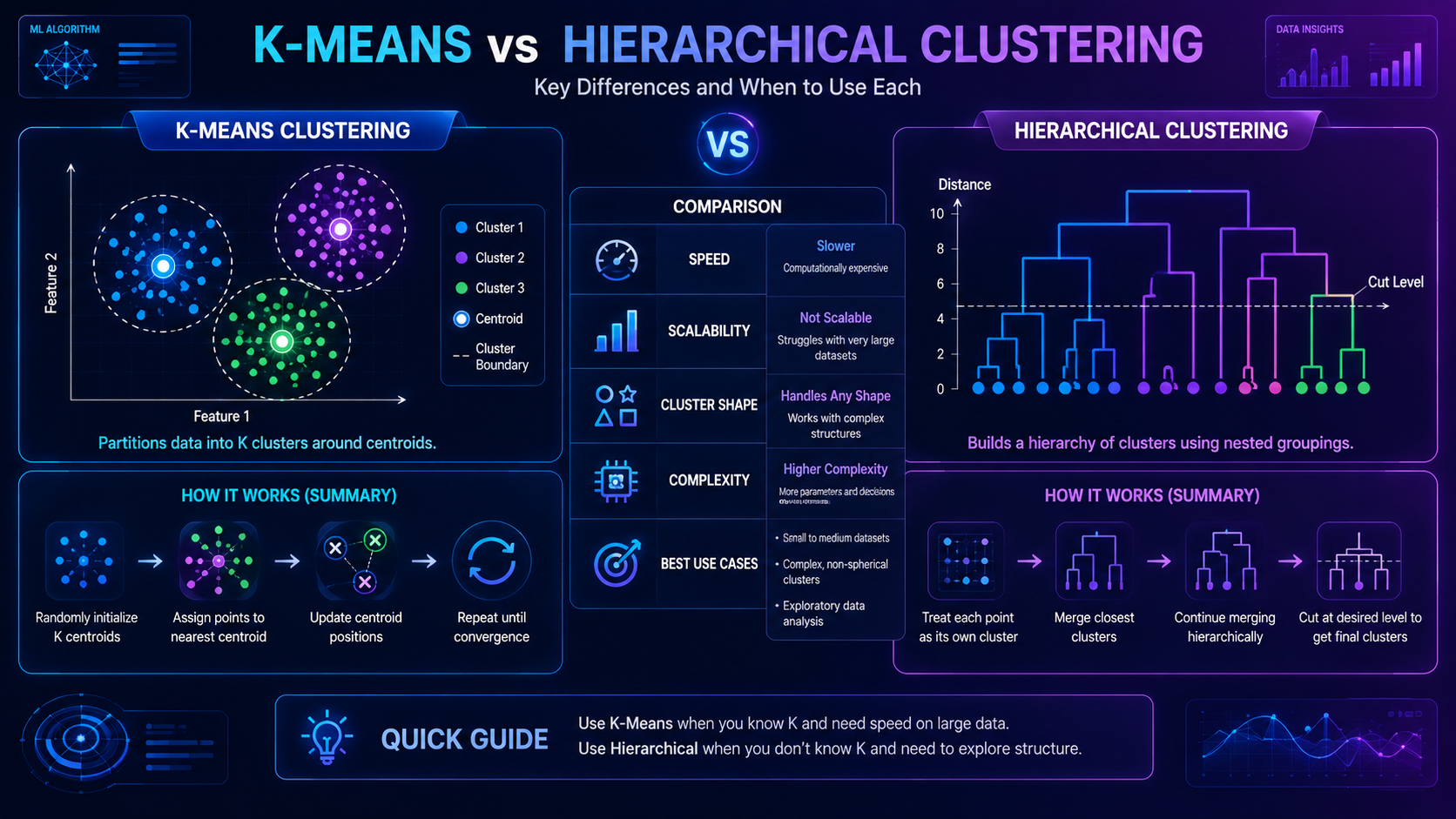
| K-Means | Hierarchical Clustering |
| Faster on large datasets | Slower but more detailed |
| Requires choosing K first | Builds cluster trees automatically |
| Simple and scalable | More flexible for smaller datasets |
For deeper learning, readers can continue with Hierarchical Clustering Explained.
K-Means vs Neural Networks
K-Means Clustering is much simpler than Neural Networks Explained and Deep Learning Explained.
Neural networks learn highly complex patterns through multiple layers, while K-Means mainly focuses on grouping similar data points.
However, clustering still plays an important role in modern AI pipelines because it helps organize and preprocess data before advanced learning models are trained.
K-Means Clustering Compared to Other Algorithms
| Algorithm | Learning Type | Primary Purpose |
| K-Means Clustering | Unsupervised | Group similar data points |
| Hierarchical Clustering | Unsupervised | Build cluster hierarchies |
| K-Nearest Neighbors | Supervised | Classify data using neighbors |
| Logistic Regression | Supervised | Predict categories |
| Random Forest | Supervised | Predict outcomes and classifications |
K-Means is designed for discovering hidden structures in data, while many other machine learning algorithms focus on prediction and classification tasks.
Future Outlook of K-Means Clustering
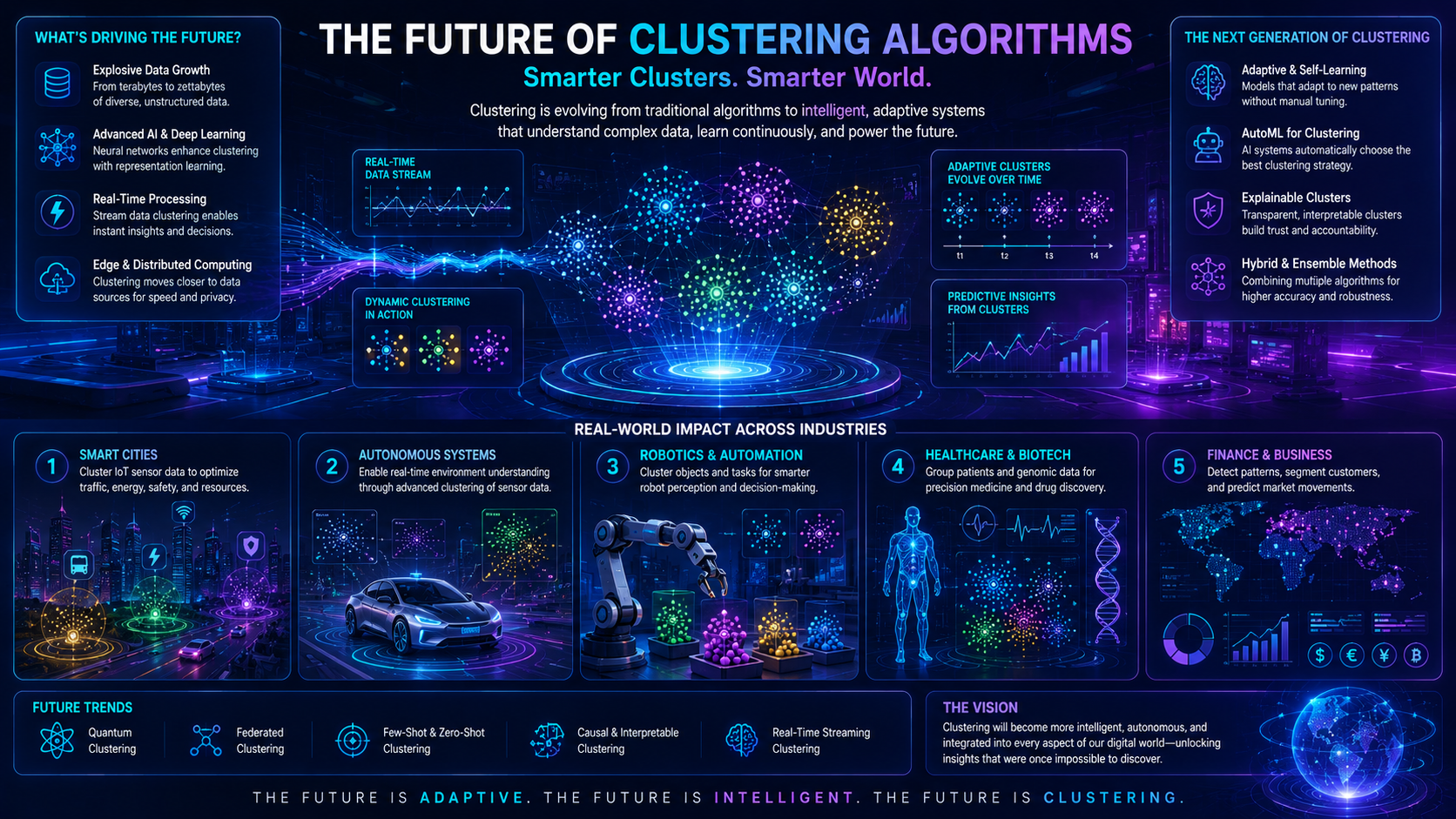
Although K-Means is one of the oldest machine learning algorithms, it remains highly important in modern AI systems.
As datasets continue growing larger, clustering algorithms are becoming:
- Faster
- More scalable
- Better at handling complex data
- More integrated with deep learning systems
Future improvements may include:
- Automatic cluster selection
- Real-time clustering
- Better handling of noisy datasets
- Improved AI automation
- Integration with generative AI systems
As organizations continue to collect larger volumes of data, clustering algorithms such as K-Means will remain valuable for discovering patterns, customer segments, and hidden relationships.
Although newer machine learning techniques continue to emerge, K-Means remains one of the most widely used unsupervised learning algorithms because of its simplicity, speed, and effectiveness.
Its role in data analysis, recommendation systems, marketing, and business intelligence is expected to remain significant in the future.
External Learning Resources
To learn more about clustering and machine learning, explore these trusted resources:
- Learn more from IBM’s guide to machine learning
- Explore Google’s Machine Learning Crash Course for beginner-friendly AI lessons
FAQ: K-Means Clustering Explained
What is K-Means Clustering in simple terms?
K-Means Clustering is a machine learning algorithm that groups similar data points into clusters automatically.
Why is K-Means Clustering important?
It helps AI systems discover hidden patterns in unlabeled data.
Is K-Means supervised or unsupervised learning?
K-Means Clustering is an unsupervised learning algorithm because it identifies patterns and groups within data without using labeled training examples.
What does the “K” mean in K-Means?
The “K” represents the number of clusters the algorithm should create.
What is a centroid in K-Means?
A centroid is the center point of a cluster used to organize similar data points.
What are some real-world examples of K-Means Clustering?
Customer segmentation, recommendation systems, fraud detection, and image compression are common examples.
What is the difference between K-Means and Hierarchical Clustering?
K-Means creates a fixed number of clusters, while Hierarchical Clustering builds layered cluster structures automatically
How do you choose the best K in K-Means
Techniques like the Elbow Method help estimate the ideal number of clusters.
Is K-Means Clustering still used today?
Yes, K-Means remains widely used in modern AI, analytics, recommendation systems, and business intelligence.
Can K-Means Clustering be used in deep learning?
Yes, clustering is often combined with deep learning systems for organizing and preprocessing data.
Conclusion
K-Means Clustering is one of the most important beginner-friendly algorithms in machine learning because it helps AI systems organize data into meaningful groups automatically.
Its simplicity, speed, and practical usefulness make it one of the most widely used clustering algorithms across industries like healthcare, finance, cybersecurity, e-commerce, and recommendation systems.
For beginners learning about artificial intelligence, understanding K-Means provides a strong foundation for more advanced topics in machine learning and data science.
As AI systems continue growing more advanced, clustering algorithms like K-Means will remain valuable tools for discovering hidden patterns inside large datasets.
Recommended Next Topics
To continue learning, explore these related articles:
- Artificial Intelligence Explained
- Machine Learning Explained
- Machine Learning Algorithms Overview
- Deep Learning Explained
- Neural Networks Explained
- Supervised Learning Explained
- Unsupervised Learning Explained
- Reinforcement Learning Explained
- Hierarchical Clustering Explained
- Feature Engineering Explained
- Data Preprocessing Explained
- K-Nearest Neighbors Explained
- Model Evaluation Metrics Explained
- Structured vs Unstructured Data
- Imbalanced Datasets Explained