Introduction
Every day, AI systems organize millions of users, products, songs, images, and documents into meaningful groups — often without humans manually labeling the data.
Streaming platforms group viewers with similar tastes. Online stores organize shoppers with similar buying habits. Music apps group songs by listening behavior. Behind many of these systems is a powerful machine learning technique called Hierarchical Clustering.
Hierarchical clustering helps AI systems discover patterns automatically by organizing data into connected groups based on similarity. Unlike many machine learning algorithms, it also shows relationships between groups using a visual tree structure called a dendrogram.
In this beginner-friendly guide, you’ll learn:
- What hierarchical clustering is
- How hierarchical clustering works step-by-step
- The two main types of hierarchical clustering
- Important clustering concepts beginners should know
- Real-world AI applications
- Advantages and limitations
- Hierarchical Clustering vs K-Means Clustering
- The future of clustering in AI systems
If you’re currently learning about Machine Learning Explained or Unsupervised Learning Explained, hierarchical clustering is one of the most important algorithms to understand.
Why Hierarchical Clustering Matters in AI
Modern AI systems process enormous amounts of data every second. Much of this data is unlabeled, meaning humans have not manually categorized it.
Hierarchical clustering helps AI systems:
- Discover hidden patterns
- Group similar users or products
- Organize complex datasets
- Improve recommendations
- Detect unusual behavior
- Understand relationships between data points
For example:
- Netflix groups viewers with similar interests
- Banks detect unusual spending behavior
- Search engines organize similar documents
- Healthcare systems group patients with related symptoms
Because of this, hierarchical clustering plays a major role in modern artificial intelligence and machine learning systems.
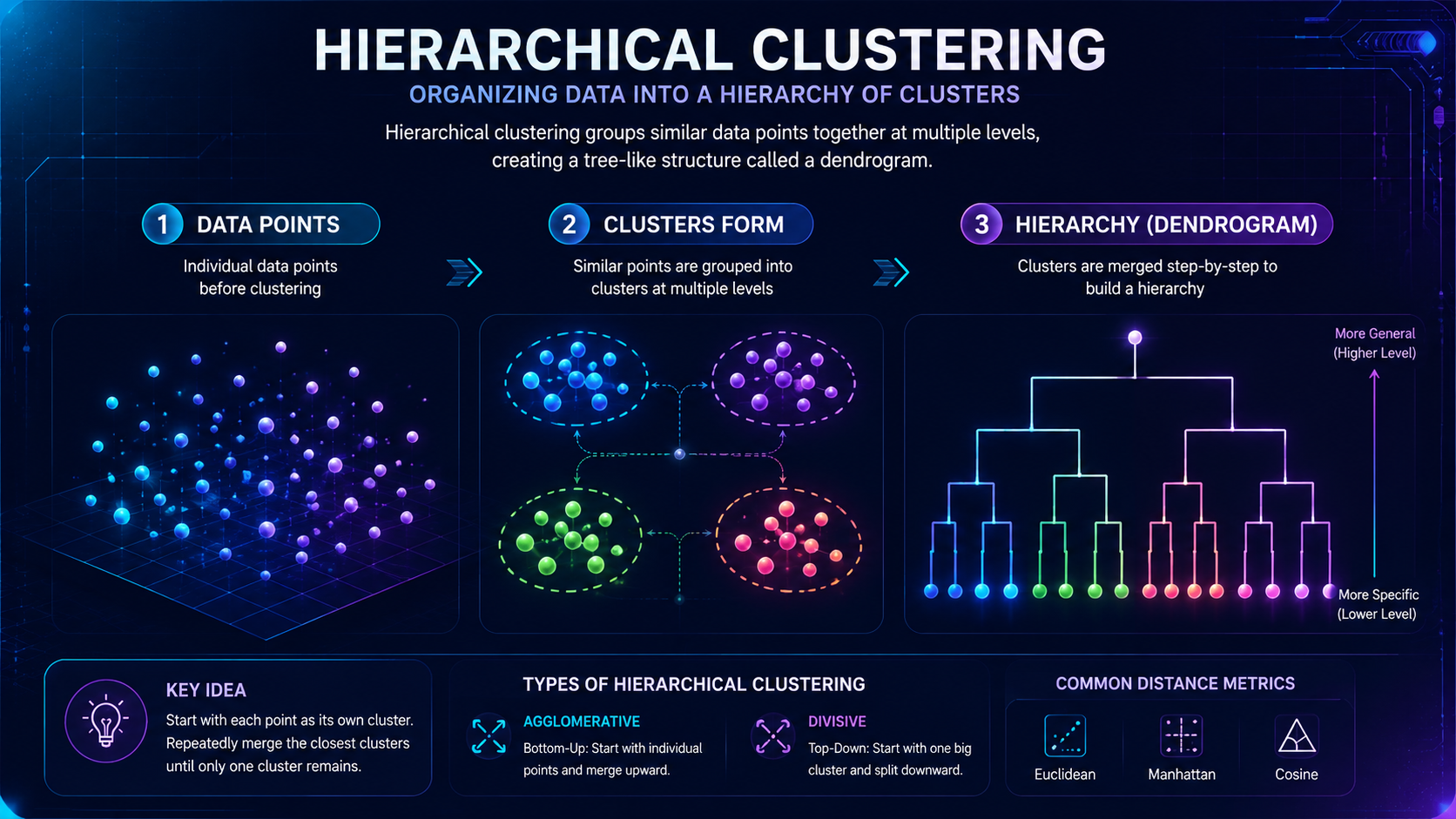
What Is Hierarchical Clustering?
Hierarchical Clustering is an unsupervised machine learning algorithm that groups similar data points into clusters by building a tree-like structure called a dendrogram. Instead of requiring a fixed number of clusters from the beginning, hierarchical clustering gradually combines or separates data based on similarity.
This clustering technique is widely used in machine learning, recommendation systems, customer segmentation, biology, and AI data analysis because it helps reveal hidden patterns inside complex datasets.
Unlike supervised learning algorithms, hierarchical clustering does not need labeled training data. This makes it part of Unsupervised Learning Explained.
The algorithm creates clusters that can be visualized like a family tree.
For example:
- Similar customers are grouped together
- Similar products are grouped together
- Similar documents are grouped together
The relationships between clusters are displayed using a diagram called a dendrogram.
A Simple Analogy
Imagine organizing a library.
First, books are grouped into broad categories:
- Science
- History
- Technology
Then each category is divided further:
- AI books
- Physics books
- Biology books
Then even further:
- Machine learning books
- Deep learning books
- Neural network books
Hierarchical clustering works similarly by building layers of related groups.
How Hierarchical Clustering Works
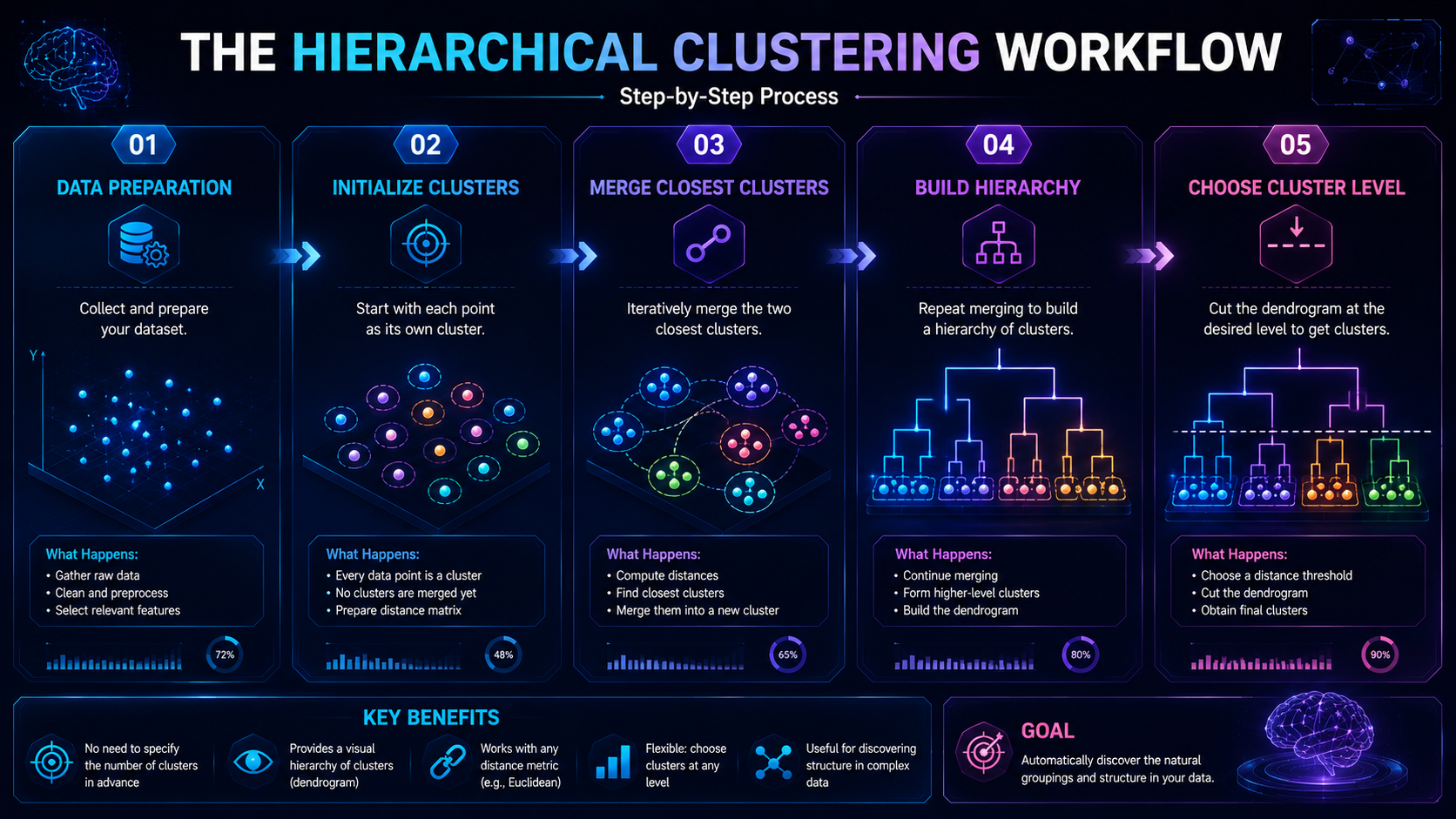
To understand hierarchical clustering, let’s follow a real-world example.
Imagine Spotify wants to group music listeners based on their listening habits.
The platform analyzes:
- Favorite genres
- Listening time
- Artists played
- Song preferences
The algorithm then organizes similar listeners into clusters.
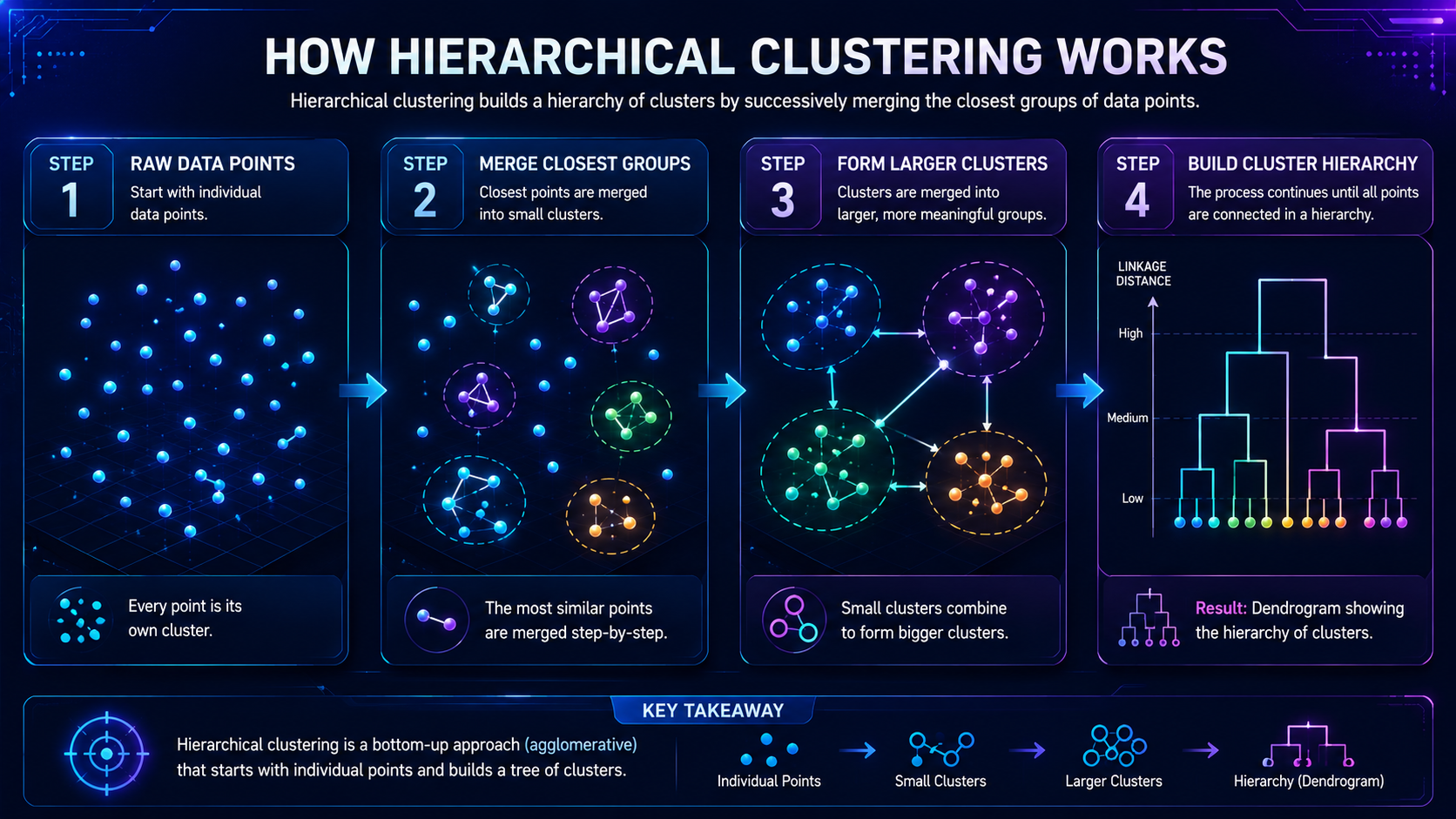
Step 1: Start With Individual Data Points
Initially, every listener is treated as its own cluster.
For example:
- Listener A
- Listener B
- Listener C
- Listener D
At the start, none of the listeners are connected.
Step 2: Measure Similarity Between Data Points
The algorithm calculates how similar listeners are.
For example:
- Two listeners who enjoy hip-hop and rap may be highly similar
- Another listener who mainly plays classical music may be very different
Machine learning systems often calculate similarity using distance measurements such as:
| Distance Metric | Purpose |
| Euclidean Distance | Straight-line distance between points |
| Manhattan Distance | Distance across grid-like paths |
| Cosine Similarity | Measures similarity in direction |
Smaller distances mean the data points are more similar.
Step 3: Merge the Closest Clusters
The algorithm finds the most similar clusters and merges them together.
For example:
- Listener A and Listener B may merge first
- Then Listener C joins the cluster
- Listener D may remain separate longer
This process repeats continuously.
Step 4: Build a Dendrogram
As clusters merge, the algorithm builds a dendrogram.
A dendrogram is a tree-like diagram used to visualize the results of Hierarchical Clustering.
The diagram shows how data points are grouped together and how clusters merge as the algorithm progresses.
By examining a dendrogram, analysts can:
- Identify natural groupings in data
- Determine possible numbers of clusters
- Explore relationships between observations
Dendrograms are one of the main reasons Hierarchical Clustering is valued for exploratory data analysis.
Step 5: Select Final Clusters
Finally, users decide where to “cut” the dendrogram.
This determines the final number of clusters.
For example:
- A high cut creates fewer broad clusters
- A low cut creates many detailed clusters
This flexibility is one reason hierarchical clustering is so useful.
Agglomerative vs Divisive Hierarchical Clustering
There are two primary approaches to Hierarchical Clustering:
| Method | How It Works |
| Agglomerative Clustering | Starts with individual data points and gradually merges them into larger clusters |
| Divisive Clustering | Starts with one large cluster and repeatedly splits it into smaller clusters |
Agglomerative Clustering is the most commonly used approach because it is simpler to implement and works well for many real-world applications.
Why Is Clustering Important in Machine Learning
Clustering is one of the most important techniques in machine learning because it helps uncover hidden patterns and relationships within data. Unlike supervised learning algorithms, clustering does not require labeled examples. Instead, it automatically groups similar data points based on their characteristics.
These groups can reveal insights that may not be obvious through manual analysis.
Clustering is commonly used to:
- Segment customers into meaningful groups
- Identify unusual behavior or anomalies
- Organize large datasets
- Improve recommendation systems
- Discover hidden trends in business and scientific data
Algorithms such as K-Means Clustering and Hierarchical Clustering are widely used because they help transform large amounts of raw data into actionable insights.
Understanding clustering is also important because it highlights one of the key differences between supervised learning and unsupervised learning. While supervised algorithms learn from labeled data, clustering algorithms discover patterns without predefined categories.
For a broader understanding, see Unsupervised Learning Explained, K-Means Clustering Explained, and Machine Learning Explained.
Key Concepts Beginners Must Understand
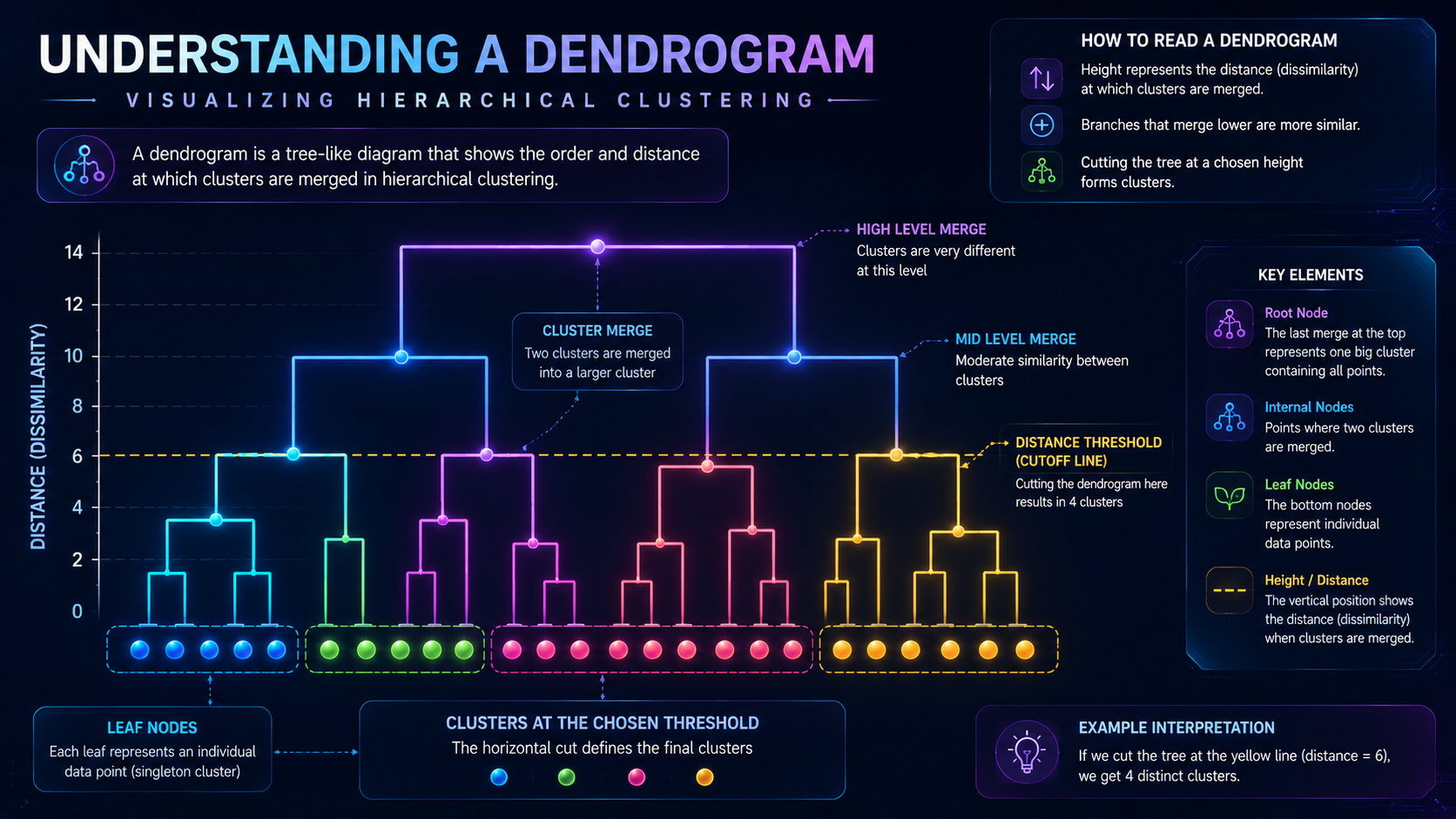
Dendrogram
A dendrogram is the visual representation of hierarchical clustering.
It helps users understand:
- Cluster relationships
- Similarity levels
- Cluster structure
Dendrograms are one of the biggest advantages of hierarchical clustering because they make complex relationships easier to visualize.
Distance Metrics
Distance metrics determine how similarity is calculated.
Different metrics can produce different clustering results.
For example:
- Euclidean distance works well for geometric spacing
- Cosine similarity is often used in text analysis and NLP systems
Choosing the right distance metric is important for clustering quality.
Linkage Methods
Linkage methods determine how distances between clusters are measured.
Single Linkage
Uses the shortest distance between clusters.
Complete Linkage
Uses the farthest distance between clusters.
Average Linkage
Uses the average distance between all data points.
Ward Linkage
Minimizes variation inside clusters.
Ward linkage is commonly used because it often creates balanced groups.
Types of Hierarchical Clustering
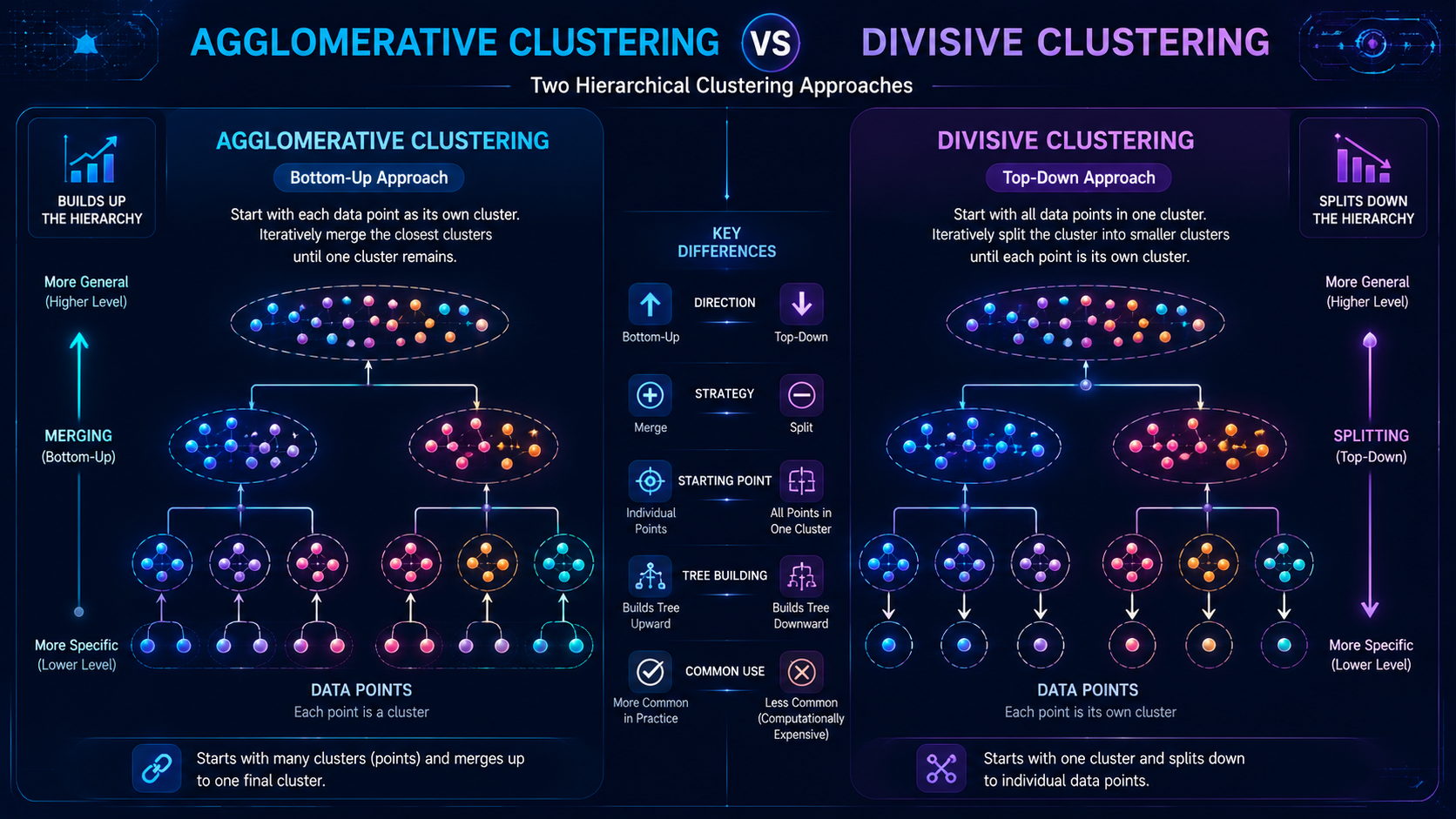
There are two main types of hierarchical clustering.
Agglomerative Hierarchical Clustering
Agglomerative clustering is the most common method.
It follows a bottom-up approach:
- Start with individual data points
- Merge the closest clusters
- Continue merging until one large cluster remains
Example
Imagine organizing students into study groups:
- Pair students with similar grades
- Merge groups with similar interests
- Build larger academic categories
Agglomerative clustering gradually builds larger clusters over time.
Divisive Hierarchical Clustering
Divisive clustering works in the opposite direction.
It follows a top-down approach:
- Start with one large cluster
- Split it into smaller groups
- Continue dividing into more detailed clusters
Example
Imagine organizing animals:
- Start with all animals
- Separate mammals from reptiles
- Separate cats from dogs
- Continue dividing into smaller groups
Divisive clustering is less commonly used because it requires more computing power.
Hierarchical Clustering vs K-Means Clustering
Hierarchical Clustering and K-Means Clustering are two of the most popular clustering algorithms, but they work differently.
| Feature | Hierarchical Clustering | K-Means Clustering |
| Requires choosing K beforehand | No | Yes |
| Produces a dendrogram | Yes | No |
| Computational complexity | Higher | Lower |
| Scalability | Better for smaller datasets | Better for large datasets |
| Cluster structure | Hierarchical | Flat clusters |
Real-World Applications of Hierarchical Clustering
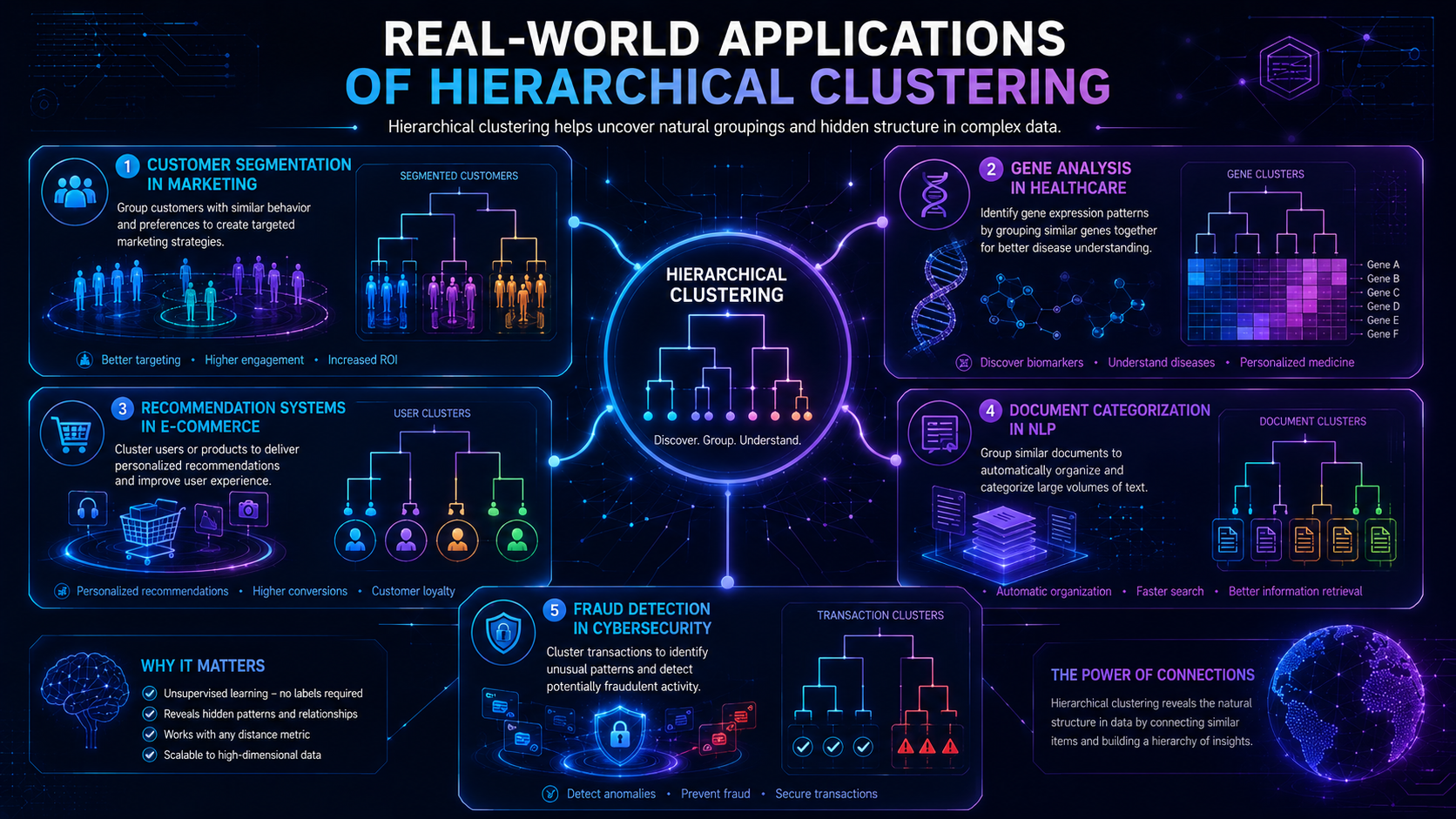
Hierarchical clustering is widely used across AI and machine learning systems.
Customer Segmentation
Businesses group customers based on:
- Purchase history
- Spending habits
- Interests
- Browsing behavior
This helps improve marketing and recommendations.
Streaming Recommendations
Platforms like Netflix and Spotify use clustering to organize users with similar preferences.
This improves personalized recommendations.
Example: How Netflix Could Use Hierarchical Clustering
Netflix may analyze users based on:
- Genres watched
- Viewing habits
- Watch time
- Ratings
The algorithm could group:
- Action movie fans
- Documentary viewers
- Anime watchers
- Comedy lovers
These clusters help Netflix recommend more relevant content.
Biology and Genetics
Scientists use hierarchical clustering to analyze:
- DNA sequences
- Gene expression
- Protein similarities
This helps researchers discover biological relationships.
Document Organization
Search engines and AI systems organize documents with related topics.
This improves:
- Search quality
- Content recommendations
- Information retrieval
This concept is also connected to Natural Language Processing Explained and modern AI search systems.
Image Recognition
Hierarchical clustering helps organize similar visual patterns in computer vision systems.
Applications include:
- Facial recognition
- Medical imaging
- Object detection
This often works alongside Deep Learning Explained and Neural Networks Explained.
Fraud Detection
Banks and cybersecurity systems use clustering to detect unusual behavior patterns.
Examples include:
- Credit card fraud
- Suspicious login activity
- Cybersecurity monitoring
When Should You Use Hierarchical Clustering?
Hierarchical Clustering is useful when you want to explore relationships between data points and understand how groups are connected at different levels.
Unlike K-Means Clustering, which requires you to choose the number of clusters in advance, Hierarchical Clustering builds a complete cluster hierarchy that can be analyzed visually.
Hierarchical Clustering is commonly used for:
- Customer segmentation
- Market research
- Biological classification
- Document organization
- Social network analysis
- Pattern discovery
It is particularly valuable when the structure of the data is unknown and researchers want flexibility when exploring potential clusters.
For another popular clustering method, see K-Means Clustering Explained.
Advantages of Hierarchical Clustering
No Need to Choose Cluster Count First
Unlike K-Means clustering, hierarchical clustering does not require selecting the number of clusters in advance.
Excellent Visualization
Dendrograms make it easier to understand relationships between groups.
Flexible Structure
Users can analyze clusters at multiple levels of detail.
Useful for Smaller Datasets
Hierarchical clustering performs well when datasets are smaller and relationships matter more.
Limitations of Hierarchical Clustering
Computationally Expensive
The algorithm can become slow when working with large datasets.
Sensitive to Noise and Outliers
Incorrect or unusual data points may reduce clustering quality.
Difficult to Reverse Decisions
Once clusters merge in agglomerative clustering, the algorithm cannot undo those decisions later.
Scaling Challenges
Modern AI systems often process enormous datasets that may require faster clustering methods like K-Means.
Hierarchical Clustering vs K-Means Clustering
Both algorithms are popular in unsupervised learning, but they solve problems differently.
| Feature | Hierarchical Clustering | K-Means Clustering |
| Cluster Count Needed | No | Yes |
| Structure | Tree hierarchy | Flat clusters |
| Visualization | Dendrogram | Cluster centers |
| Speed | Slower | Faster |
| Best For | Small to medium datasets | Large datasets |
| Flexibility | High | Moderate |
When to Use Hierarchical Clustering
Use hierarchical clustering when:
- You want to explore relationships in data
- Visualization is important
- The dataset is smaller
- The number of clusters is unknown
When to Use K-Means
Use K-Means when:
- Speed matters
- Working with large datasets
- The approximate number of clusters is already known
If you’re learning clustering algorithms, also explore:
Hierarchical Clustering Compared to Other Algorithms
| Algorithm | Learning Type | Primary Purpose |
| Hierarchical Clustering | Unsupervised | Build cluster hierarchies |
| K-Means Clustering | Unsupervised | Create predefined clusters |
| K-Nearest Neighbors | Supervised | Classify data using neighbors |
| Logistic Regression | Supervised | Predict categories |
| Random Forest | Supervised | Predict outcomes and classifications |
Hierarchical Clustering focuses on discovering relationships between groups of data, while many other machine learning algorithms focus on making predictions.
Hierarchical Clustering in Modern AI Systems
Although modern AI systems often rely on deep learning, clustering still plays a major role in AI workflows.
Hierarchical clustering helps:
- Organize unlabeled data
- Improve recommendation systems
- Analyze user behavior
- Support semantic search
- Group related documents
- Structure vector databases
Many modern AI systems combine clustering with:
- Neural networks
- Recommendation engines
- Natural language processing
- Computer vision systems
- Large language models (LLMs)
This makes clustering an important foundation for understanding modern AI.
Future Outlook of Hierarchical Clustering
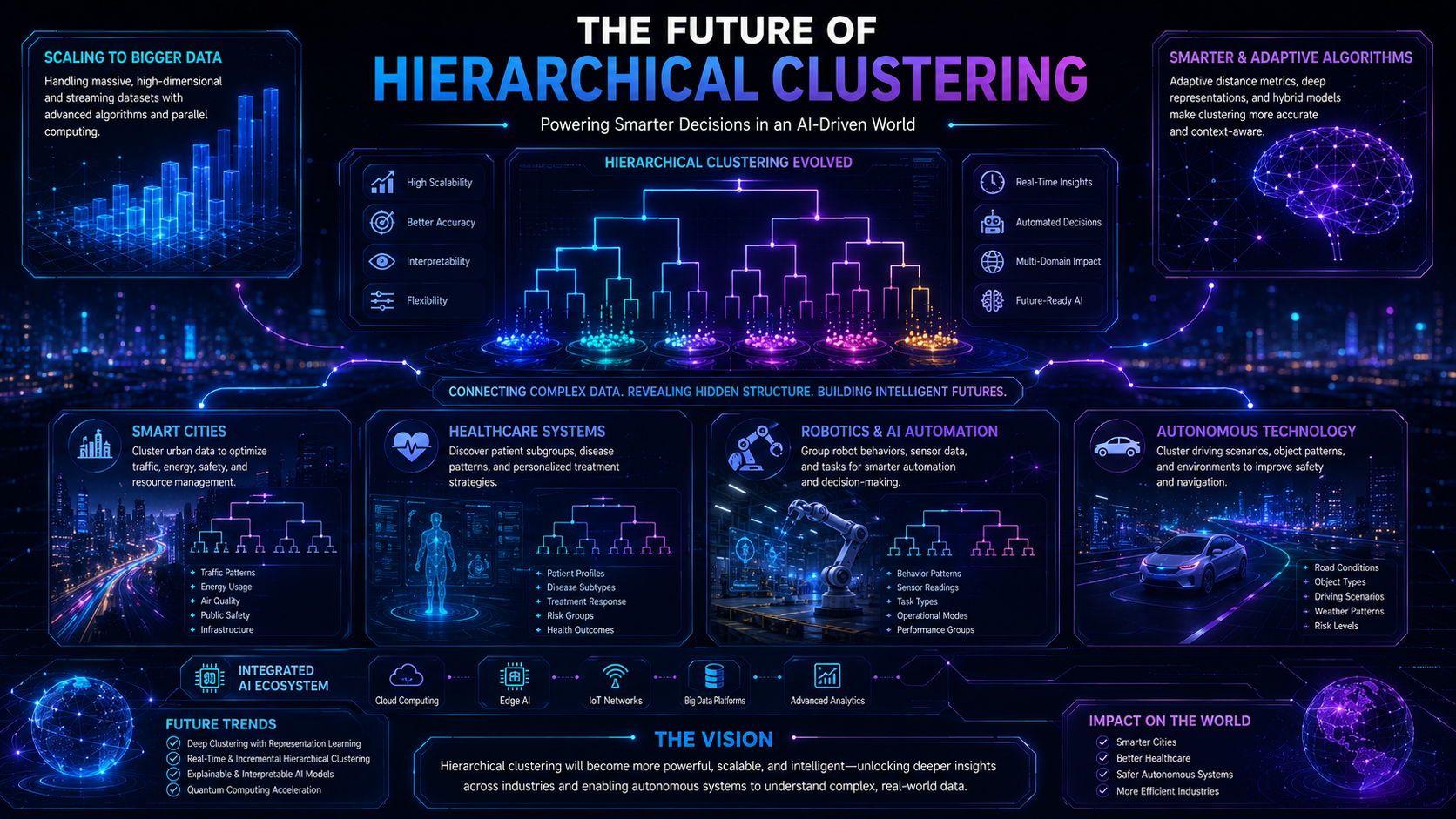
Hierarchical clustering continues evolving as AI systems become more advanced.
Future improvements may include:
- Faster clustering for massive datasets
- Real-time clustering for streaming AI systems
- Hybrid clustering combined with deep learning
- Better semantic clustering for LLMs
- Improved vector database organization
- AI agents that automatically organize information
As organizations continue to generate larger and more complex datasets, clustering algorithms will remain important tools for uncovering hidden patterns and relationships.
While K-Means Clustering is often preferred for large-scale applications, Hierarchical Clustering remains valuable for exploratory analysis, biological research, customer segmentation, and other areas where understanding relationships between groups is important.
Its ability to create interpretable cluster structures ensures it will continue to play a role in machine learning and data science.
FAQ: Hierarchical Clustering Explained
What is hierarchical clustering in simple terms?
Hierarchical clustering is a machine learning method that groups similar data into connected clusters using a tree-like structure.
Is Hierarchical Clustering supervised or unsupervised learning?
Hierarchical Clustering is an unsupervised learning algorithm because it groups data based on similarities without requiring labeled training examples.
What is a dendrogram?
A dendrogram is a visual diagram that shows how clusters are connected in hierarchical clustering.
What is the difference between hierarchical clustering and K-Means?
Hierarchical clustering builds a hierarchy of clusters, while K-Means creates a fixed number of flat clusters.
Why is hierarchical clustering important?
It helps AI systems discover hidden patterns and organize unlabeled data automatically.
What are the two types of hierarchical clustering?
The two main types are agglomerative clustering and divisive clustering.
What industries use hierarchical clustering?
Healthcare, finance, cybersecurity, biology, e-commerce, and recommendation systems commonly use hierarchical clustering.
What are the limitations of hierarchical clustering?
It can become slow on very large datasets and may be sensitive to noisy data.
Is hierarchical clustering used in deep learning?
Yes. Hierarchical clustering is often combined with deep learning systems for data organization and analysis.
What is an example of hierarchical clustering in real life?
Streaming platforms use hierarchical clustering to group users with similar viewing or listening preferences.
Conclusion
Hierarchical Clustering is one of the most important unsupervised machine learning algorithms for discovering hidden patterns inside data.
By building a hierarchy of relationships between data points, it helps AI systems organize information in a meaningful and visually understandable way.
Hierarchical clustering is widely used in:
- Customer segmentation
- Recommendation systems
- Biology and genetics
- Search engines
- Fraud detection
- AI data analysis
Although newer AI systems often rely heavily on deep learning, clustering remains a critical foundation of machine learning and artificial intelligence.
For beginners, understanding hierarchical clustering provides a strong introduction to how AI systems discover structure and meaning inside large datasets.
Recommended Next Topics
Continue learning with these related beginner-friendly AI guides:
- Artificial Intelligence Explained
- Machine Learning Explained
- Unsupervised Learning Explained
- Supervised Learning Explained
- Reinforcement Learning Explained
- Deep Learning Explained
- Neural Networks Explained
- K-Means Clustering Explained
- Machine Learning Algorithms Overview
- Data Preprocessing Explained
- Feature Engineering Explained
- Model Evaluation Metrics Explained
- Structured vs Unstructured Data
- Imbalanced Datasets Explained
External Resources
- Learn more from IBM’s guide to clustering and machine learning
- Explore Google’s Machine Learning Crash Course for beginner AI education