Introduction
Machine learning models are designed to learn patterns from data and make predictions. Some models are highly complex, while others are surprisingly simple but still powerful. Naive Bayes belongs to the second category.
Despite its simplicity, Naive Bayes remains one of the most popular machine learning algorithms for classification tasks. Companies use it in email filtering, document categorization, customer support systems, and even medical diagnosis tools.
If you have ever wondered how Gmail identifies spam emails or how online reviews are automatically labeled as positive or negative, there is a good chance a Naive Bayes model is involved.
In this beginner-friendly guide, you will learn:
- What Naive Bayes is
- How it works step-by-step
- The main types of Naive Bayes algorithms
- Real-world applications
- Advantages and limitations
- How it compares to other machine learning methods
If you are new to AI, this topic also connects naturally with articles like Machine Learning Explained, Supervised Learning Explained, and Artificial Intelligence Explained.
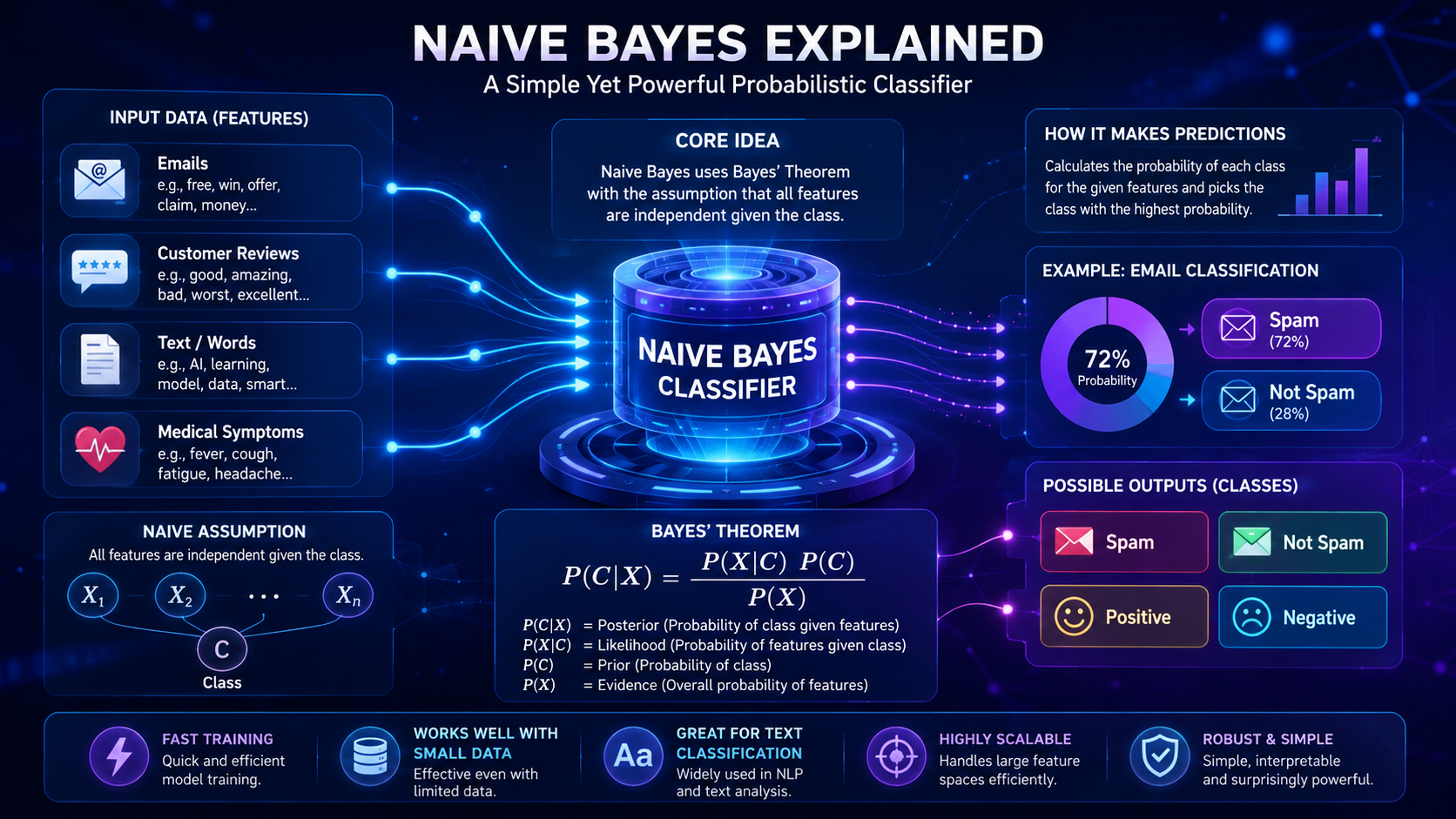
What Is Naive Bayes?
Naive Bayes is a machine learning algorithm that uses probability to predict outcomes based on patterns in data. It is called “naive” because it assumes that all input features are independent of each other, even though this is rarely true in real-world situations.
Naive Bayes is widely used for tasks like spam email detection, sentiment analysis, recommendation systems, and text classification because it is fast, simple, and effective for many AI applications.
A classification model predicts categories or labels. For example:
- Spam or not spam
- Positive or negative review
- Fraudulent or legitimate transaction
- News category prediction
Naive Bayes works by calculating probabilities and selecting the most likely outcome.
The algorithm is based on Bayes’ Theorem, a mathematical formula used to calculate conditional probability. However, beginners do not need to understand advanced math to understand the core idea.
The main concept is simple:
Naive Bayes predicts outcomes by looking at past data and calculating which category is most likely.
For example, imagine an email containing words like:
- “Win”
- “Prize”
- “Free”
- “Click now”
A Naive Bayes model may calculate that the probability of the email being spam is extremely high.
Naive Bayes is a supervised machine learning algorithm that uses probability to classify data and make predictions.
Why Is It Called “Naive”?
The term “naive” comes from the algorithm’s assumption that all features are independent of one another.
For example, when classifying an email, Naive Bayes assumes that each word contributes independently to the prediction. In reality, words often influence each other, so this assumption is not always true.
Despite this simplification, Naive Bayes often performs surprisingly well in many real-world applications.
For example, if an email contains the words:
- “Free”
- “Prize”
- “Winner”
Naive Bayes assumes these words are unrelated to each other.
In reality, they are often connected.
Even though this assumption is unrealistic, the algorithm still performs surprisingly well in many situations.
Think of it like a detective making a quick decision based on clues without fully understanding how the clues connect together. The approach may not be perfect, but it can still be highly effective.
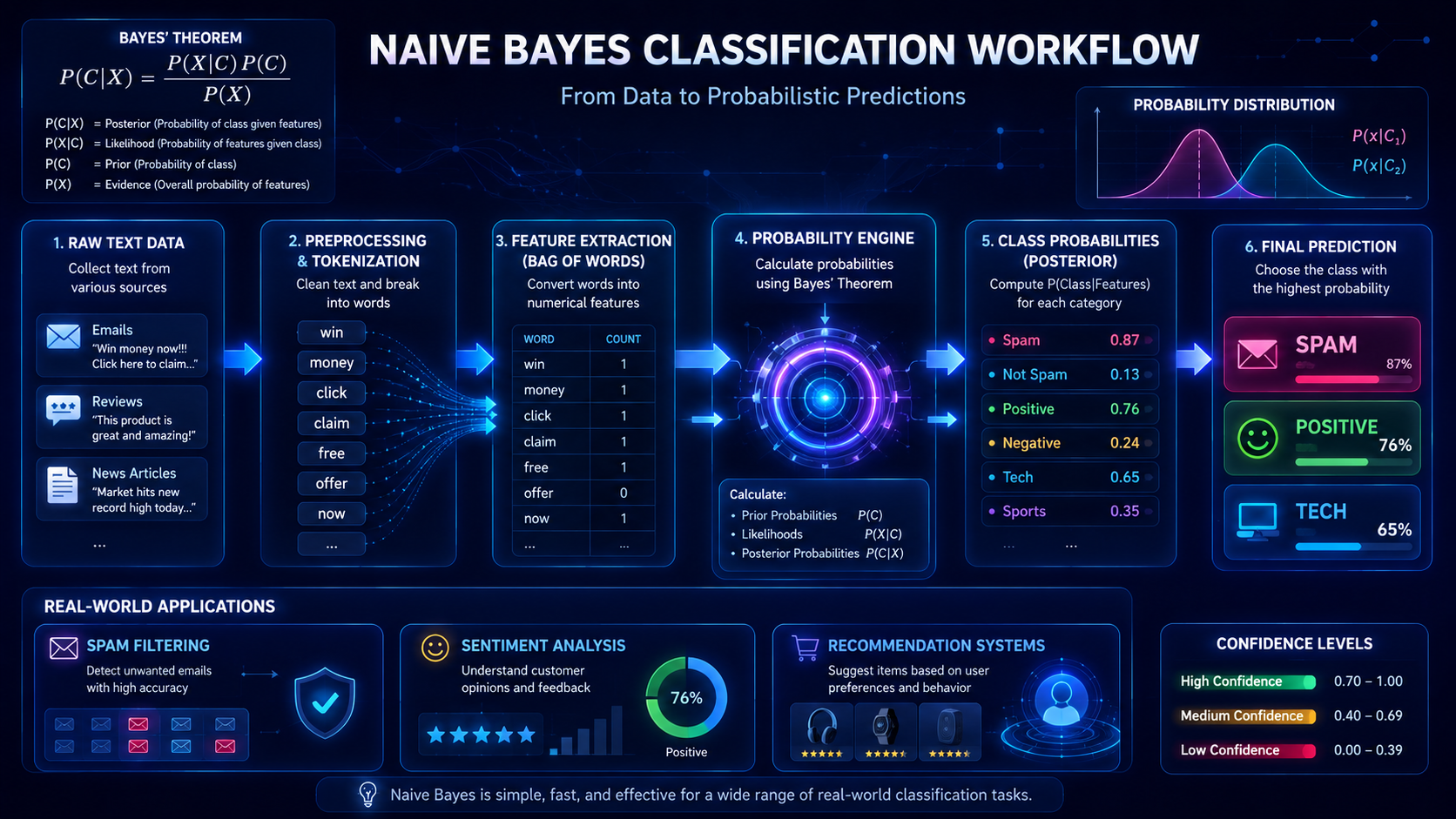
How Naive Bayes Works
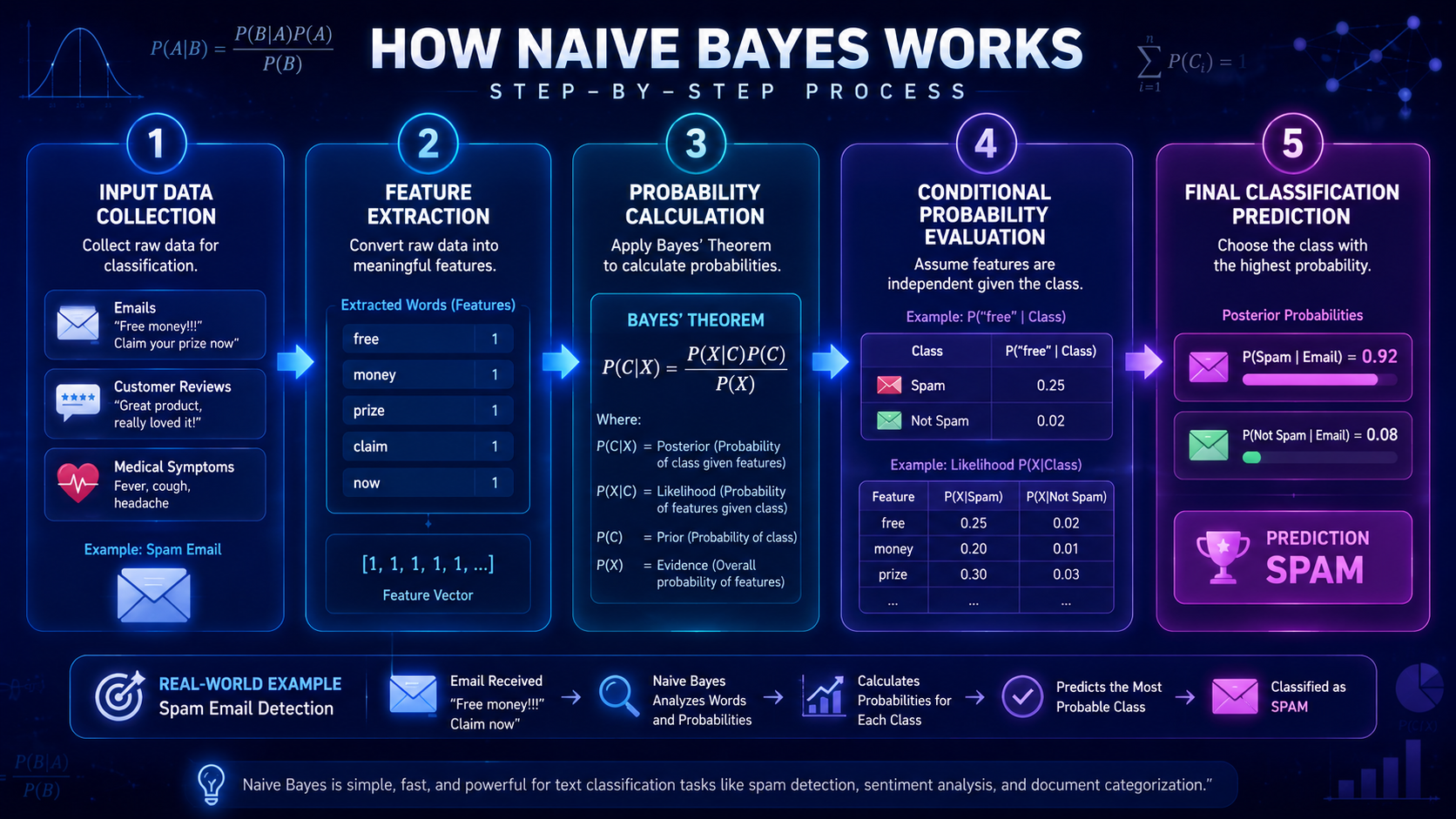
Naive Bayes follows a simple process to make predictions.
Step 1: Collect Training Data
The model first learns from labeled examples.
For example:
| Email Text | Label |
| “Claim your free prize” | Spam |
| “Meeting scheduled for tomorrow” | Not Spam |
| “You won a gift card” | Spam |
This training data helps the algorithm understand patterns.
Step 2: Break Data Into Features
Features are the pieces of information the model uses to make predictions.
In text classification, features are often individual words.
Example features:
- Free
- Prize
- Discount
- Meeting
- Invoice
The algorithm checks how often these words appear in different categories.
Step 3: Calculate Probabilities
Naive Bayes calculates probabilities for each category.
For example:
- Probability that an email is spam
- Probability that an email is not spam
Then it calculates how likely specific words appear in each category.
Example:
| Word | Spam Probability |
| Free | High |
| Prize | High |
| Meeting | Low |
The model combines these probabilities to predict the final category.
Step 4: Make a Prediction
When new data arrives, the model compares probabilities.
Imagine a new email says:
- “Congratulations! Claim your free reward now!”
The model notices words like:
- Congratulations
- Free
- Reward
These words commonly appear in spam emails, so the probability of the email being spam becomes very high.
If the spam probability is higher than the non-spam probability, the email is classified as spam.
This process happens extremely quickly, making Naive Bayes useful for real-time systems.
Why Is Naive Bayes So Fast?
Naive Bayes makes predictions by calculating probabilities rather than building complex decision structures. Because it assumes that features are independent of one another, the calculations become much simpler.
This simplified approach allows Naive Bayes to train quickly and make predictions efficiently, even when working with large datasets.
As a result, Naive Bayes remains a popular choice for real-time classification tasks such as spam filtering and sentiment analysis.
Key Concepts Beginners Should Understand
Probability
Probability measures how likely something is to happen.
Naive Bayes uses probability to predict categories.
Example:
- 90% chance an email is spam
- 10% chance it is legitimate
Classification
Naive Bayes is mainly used for classification tasks.
Classification means assigning data to categories.
Examples include:
- Spam detection
- Language detection
- Sentiment analysis
- Fraud detection
This topic connects closely with Supervised Learning Explained.
Features
Features are the inputs used to make predictions.
Examples:
- Words in an email
- Customer purchase history
- Product ratings
- Medical symptoms
Good features improve model performance.
Training Data
The algorithm learns from examples called training data.
High-quality training data helps the model make better predictions.
You can learn more in Training vs Testing Data.
Conditional Probability
Conditional probability measures the likelihood of something happening based on another event.
Example:
- Probability an email is spam given the word “free”
This idea is the foundation of Bayes’ Theorem.
Types of Naive Bayes Algorithms

Different versions of Naive Bayes are designed for different types of data.
Gaussian Naive Bayes
Gaussian Naive Bayes works with continuous numerical data.
Examples:
- Temperature
- Height
- Age
- Salary
It assumes the data follows a normal distribution.
Multinomial Naive Bayes
This is one of the most common versions.
It works well for text classification problems where word frequencies matter.
Examples:
- Spam detection
- News categorization
- Sentiment analysis
Bernoulli Naive Bayes
Bernoulli Naive Bayes focuses on binary features.
The model checks whether a feature exists or not.
Example:
- Word appears = Yes
- Word appears = No
This version is useful for simple text classification tasks.
Real-World Applications of Naive Bayes
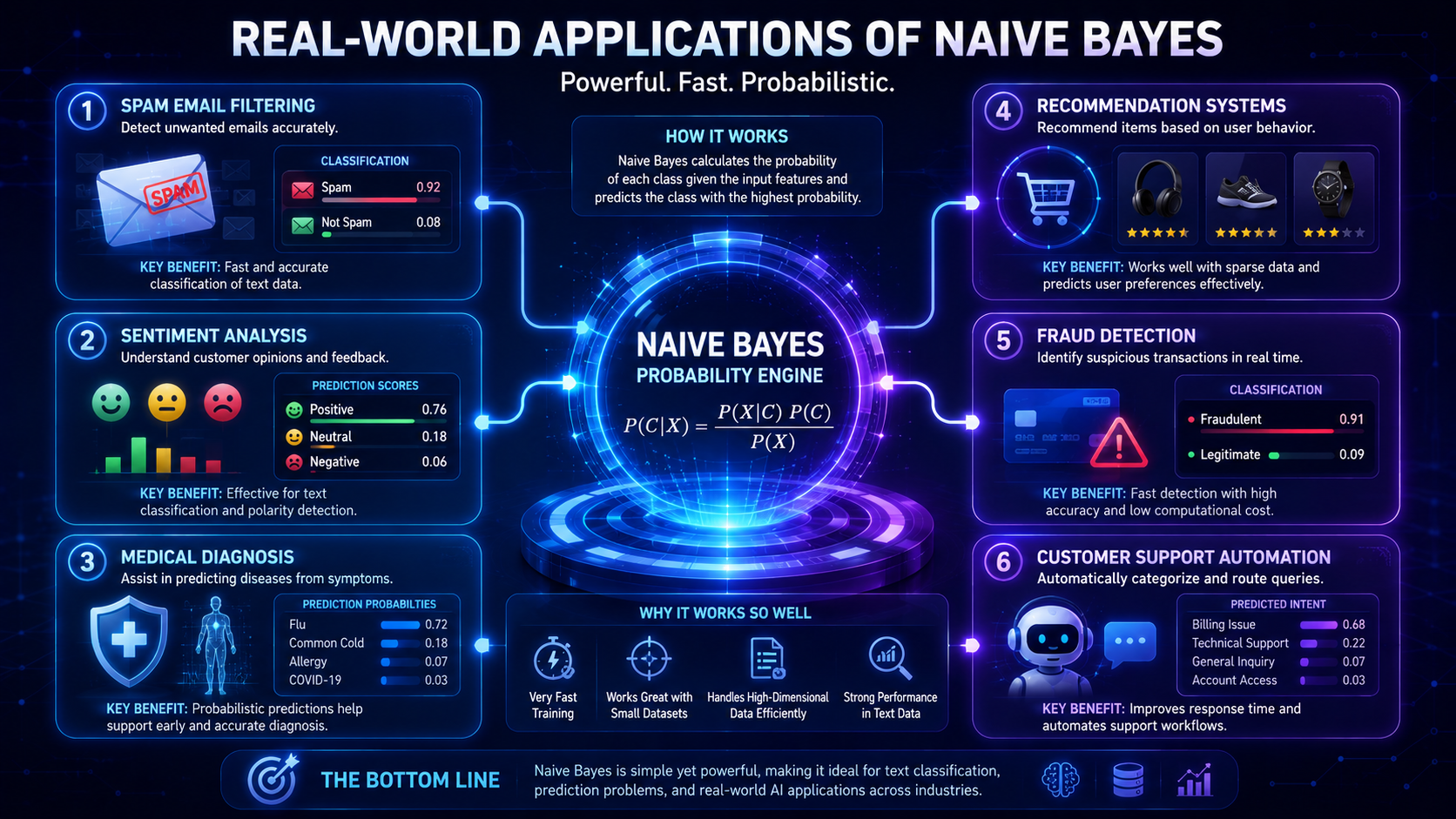
Spam Email Detection
One of the most famous uses of Naive Bayes is spam filtering.
The model analyzes words and phrases commonly found in spam emails. Emails with suspicious patterns are automatically filtered before they reach your inbox.
Sentiment Analysis
Companies use Naive Bayes to analyze customer opinions.
Example classifications include:
- Positive review
- Negative review
- Neutral review
Streaming platforms, online stores, and social media companies use this heavily.
News Classification
News websites automatically categorize articles into topics such as:
- Sports
- Technology
- Politics
- Entertainment
Naive Bayes can perform this quickly and efficiently.
Medical Diagnosis
Healthcare systems sometimes use Naive Bayes to help predict diseases based on symptoms and patient data.
It can support doctors by identifying likely conditions more quickly.
Recommendation Systems
Naive Bayes can help recommend products, movies, or music based on user behavior.
This is common in e-commerce and streaming services.
When Should You Use Naive Bayes?
Naive Bayes is often used when the goal is to classify information quickly and efficiently. It performs particularly well when working with large amounts of text data and probability-based predictions.
Naive Bayes has historically been one of the most widely used algorithms in Natural Language Processing tasks such as spam filtering, sentiment analysis, and text classification.
Common use cases include:
- Spam email filtering
- Sentiment analysis
- Text classification
- News article categorization
- Recommendation systems
- Customer feedback analysis
Because it is fast, scalable, and easy to implement, Naive Bayes is often used as a baseline classification model before testing more advanced algorithms.
For other classification approaches, see Logistic Regression Explained, Support Vector Machines Explained, and Random Forest Explained.
Why Naive Bayes Still Matters Today
Many beginners assume older machine learning algorithms are outdated because modern AI often focuses on deep learning and neural networks.
However, Naive Bayes still matters because it offers several practical advantages:
- It is fast to train
- It requires less computing power
- It performs well on text-based tasks
- It works effectively with smaller datasets
- It is easier to deploy and maintain
Large companies still use Naive Bayes in lightweight AI systems where speed and efficiency are more important than maximum accuracy.
For example:
- Email spam filtering must happen instantly
- Customer support systems need fast text classification
- Edge devices may not have enough power for deep learning models
This is why simple machine learning algorithms remain important in modern AI.
Advantages of Naive Bayes
Simple to Understand
Naive Bayes is beginner-friendly and easier to implement than many advanced models.
Fast Training Speed
The algorithm trains quickly, even with large datasets.
This makes it useful for real-time applications.
Works Well With Text Data
Naive Bayes performs especially well for text classification tasks.
This is why it is popular in NLP systems.
Requires Less Training Data
Compared to some complex algorithms, Naive Bayes can perform reasonably well with smaller datasets.
Scalable
The model handles large datasets efficiently.
Limitations of Naive Bayes
Assumes Feature Independence
The biggest limitation is the “naive” assumption that features are unrelated.
Real-world data often contains relationships between features.
Lower Accuracy for Complex Problems
Advanced algorithms like deep neural networks may achieve better accuracy for highly complex tasks.
Sensitive to Data Quality
Poor training data can reduce performance.
Missing or biased data may create inaccurate predictions.
Struggles With Context
Naive Bayes may fail to fully understand meaning and context in language.
Modern AI systems like transformers are better at understanding context.
You can learn more in Deep Learning Explained and Neural Networks Explained.
Naive Bayes vs Other Machine Learning Algorithms
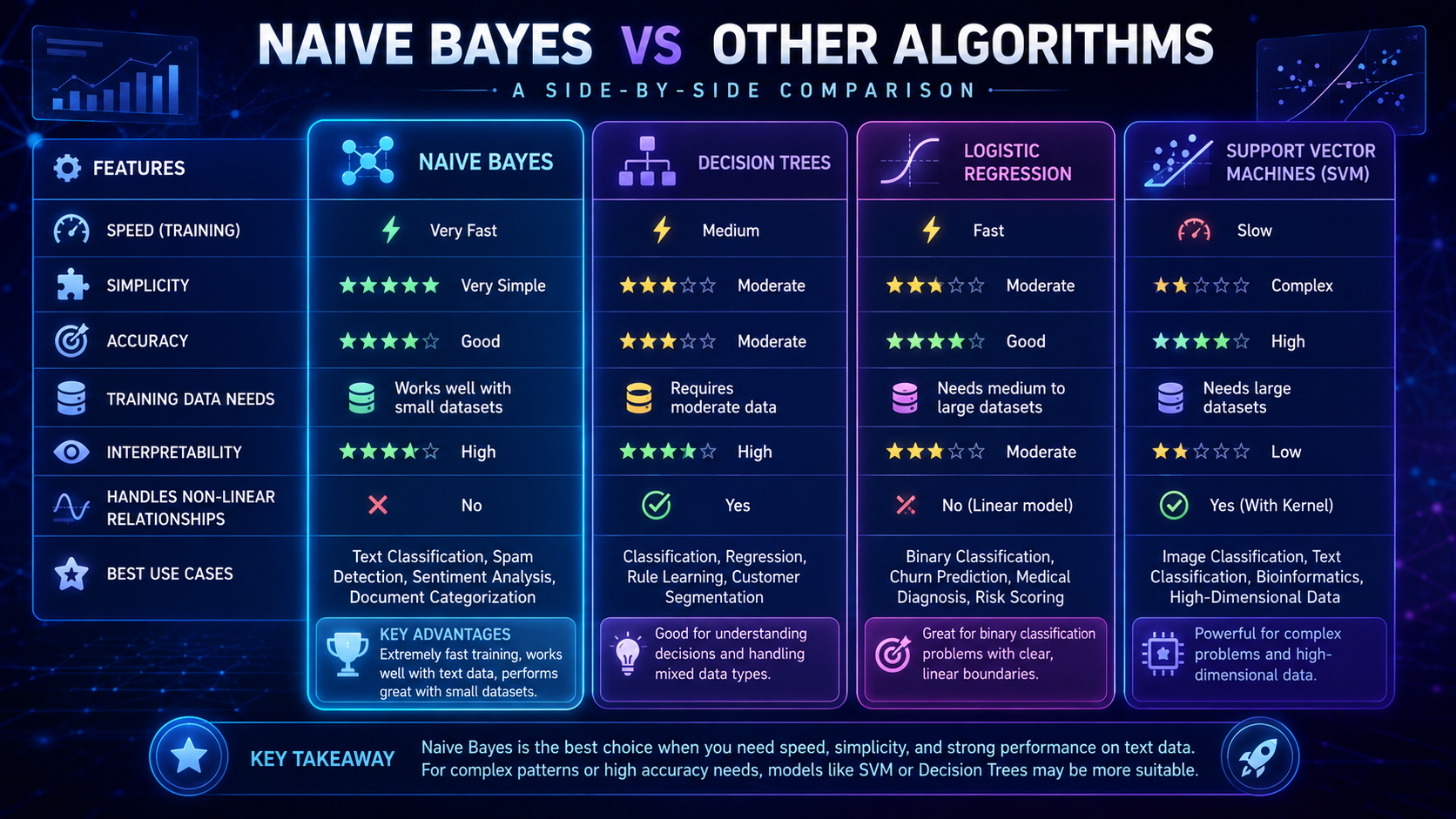
| Algorithm | Main Use | Strength | Weakness |
| Naive Bayes | Classification | Fast and simple | Assumes independence |
| Decision Trees | Classification & Regression | Easy to interpret | Can overfit |
| Logistic Regression | Classification | Good accuracy | Less effective for complex text |
| Neural Networks | Complex AI tasks | High performance | Requires more data and computing power |
| K-Nearest Neighbors | Pattern matching | Simple concept | Slow with large datasets |
Naive Bayes is often preferred when working with text-heavy datasets because it can process large amounts of information quickly while maintaining good classification performance.
Naive Bayes and Artificial Intelligence
Naive Bayes plays an important role in the broader AI ecosystem.
It is commonly taught early in machine learning education because it introduces important concepts like:
- Probability
- Classification
- Training data
- Feature selection
Understanding Naive Bayes helps build a foundation for learning more advanced AI systems.
It also connects naturally to topics like:
- Artificial Intelligence Explained
- Machine Learning Explained
- Deep Learning Explained
- Supervised Learning Explained
- Unsupervised Learning Explained
- Reinforcement Learning Explained
Future Outlook of Naive Bayes
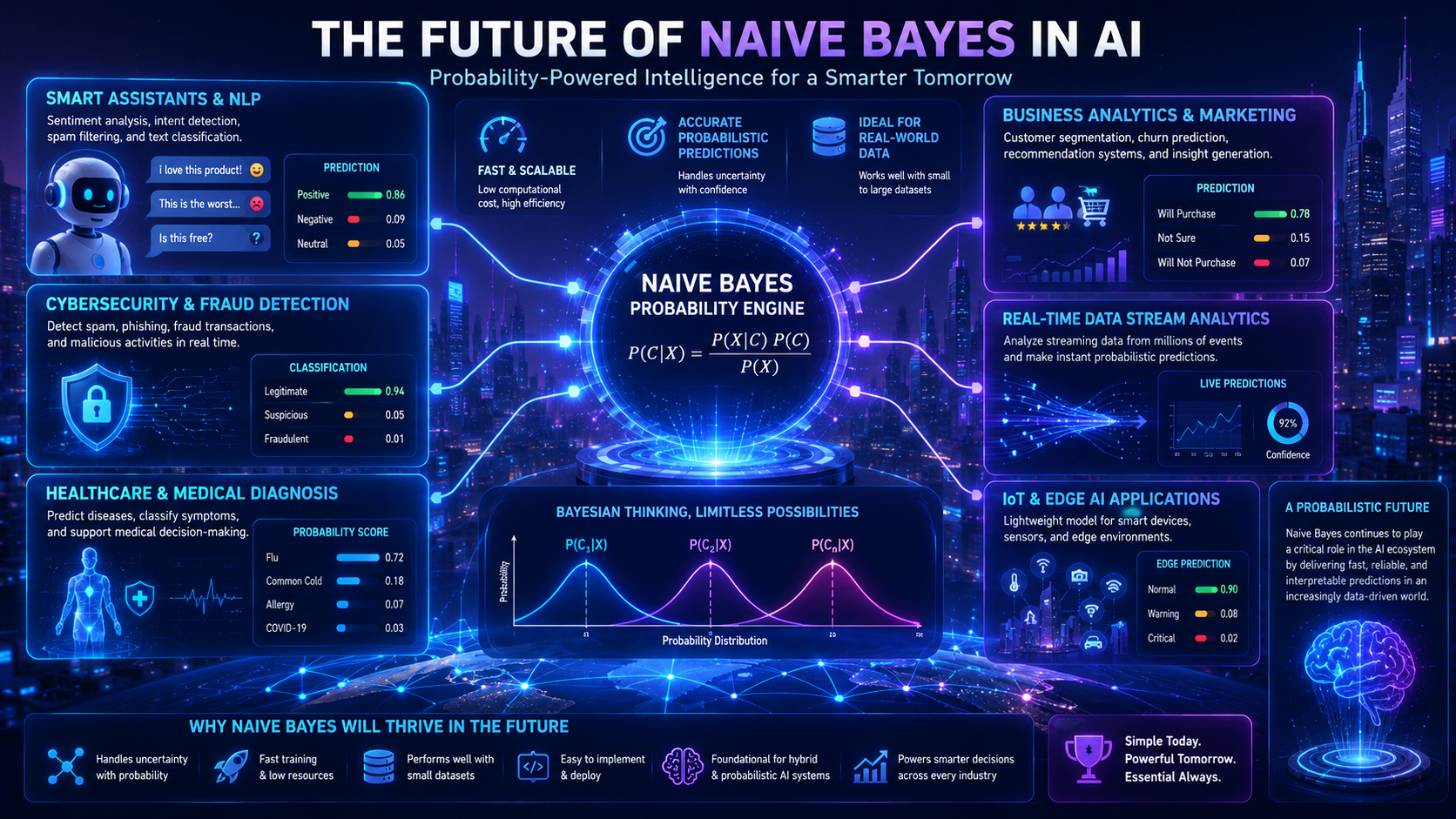
Although modern AI systems increasingly use Deep Learning and Transformer-based models, Naive Bayes continues to be valuable because of its speed, simplicity, and efficiency. It remains widely used in text classification, spam detection, sentiment analysis, and other applications where fast predictions are important.
As organizations continue to process large amounts of text data, Naive Bayes is likely to remain a useful machine learning tool for many years.
Modern AI systems often combine multiple algorithms together, and Naive Bayes continues to be valuable because it is:
- Fast
- Lightweight
- Reliable for simple classification tasks
- Easy to deploy
As AI expands into edge devices and low-power systems, lightweight algorithms like Naive Bayes may become even more important.
Naive Bayes also supports the growing demand for explainable AI because its decision-making process is easier to understand than many deep learning models.
While neural networks dominate advanced AI applications, Naive Bayes will likely continue to play an important role in:
- educational AI systems
- lightweight applications
- text classification
- edge AI devices
- hybrid AI systems
It remains one of the best algorithms for beginners learning how machine learning models make predictions.
External Resources for Learning More
To explore Naive Bayes further, these high-authority resources are excellent starting points:
- Learn more from IBM’s guide to machine learning
- Explore Google’s Machine Learning Crash Course
These resources provide beginner-friendly explanations and practical examples.
FAQ: Naive Bayes Explained
What is Naive Bayes in simple terms?
Naive Bayes is a machine learning algorithm that uses probability to predict categories or outcomes.
Why is Naive Bayes called “naive”?
It is called naive because it assumes all features are independent from each other.
Is Naive Bayes supervised or unsupervised learning?
Naive Bayes is a supervised learning algorithm because it learns from labeled training data to classify new information.
What is Naive Bayes mainly used for?
It is mainly used for classification tasks such as spam detection and sentiment analysis.
Is Naive Bayes good for text classification?
Yes, Naive Bayes is widely used for text classification because it works efficiently with word-based data.
What are the advantages of Naive Bayes?
Its main advantages are speed, simplicity, scalability, and effectiveness with text data.
What are the limitations of Naive Bayes?
The biggest limitation is its assumption that features are independent.
What is the difference between Naive Bayes and neural networks?
Naive Bayes is simpler and faster, while neural networks are more powerful for complex AI tasks.
Can Naive Bayes work with small datasets?
Yes, it often performs reasonably well even with smaller datasets.
Is Naive Bayes still used today?
Yes, Naive Bayes is still widely used in spam filtering, NLP systems, recommendation engines, and educational AI projects.
Conclusion
Naive Bayes is one of the simplest yet most important machine learning algorithms beginners can learn.
It uses probability to classify data and make predictions, making it highly useful for tasks like spam detection, sentiment analysis, and document classification.
Even though it makes unrealistic assumptions about feature independence, Naive Bayes often performs surprisingly well in real-world applications.
For beginners entering AI and machine learning, understanding Naive Bayes builds a strong foundation for more advanced topics like deep learning, neural networks, and modern AI systems.
Recommended Next Topics
To continue learning, explore these related guides:
- K-Nearest Neighbors Explained
- Machine Learning Explained
- Machine Learning Algorithms Overview
- Supervised Learning Explained
- Deep Learning Explained
- Neural Networks Explained
- Decision Trees Explained
- Logistic Regression Explained
- Support Vector Machines Explained
- Random Forest Explained
- Natural Language Processing (NLP)
- Sentiment Analysis Explained
- Model Evaluation Metrics Explained
- Chatbots Explained
- Text Classification Explained
- Word Embeddings Explained