Introduction
Machine learning models help computers recognize patterns, make predictions, and improve decision-making using data. Some algorithms are simple and easy to understand, while others combine multiple models together to achieve better results.
Random Forest is one of the most powerful and widely used machine learning algorithms because it balances accuracy, flexibility, and reliability. It is used in industries like healthcare, finance, cybersecurity, e-commerce, and marketing to solve real-world problems.
If you have already explored topics like Machine Learning Explained, Supervised Learning Explained, or Decision Trees Explained, Random Forest is the perfect next step because it builds directly on decision trees while solving many of their weaknesses.
In this beginner-friendly guide, you will learn:
- What Random Forest is
- Why it is called Random Forest
- How it works step by step
- Important beginner concepts
- Real-world applications
- Advantages and limitations
- How it compares to related algorithms
- The future of Random Forest in AI
What Is Random Forest?
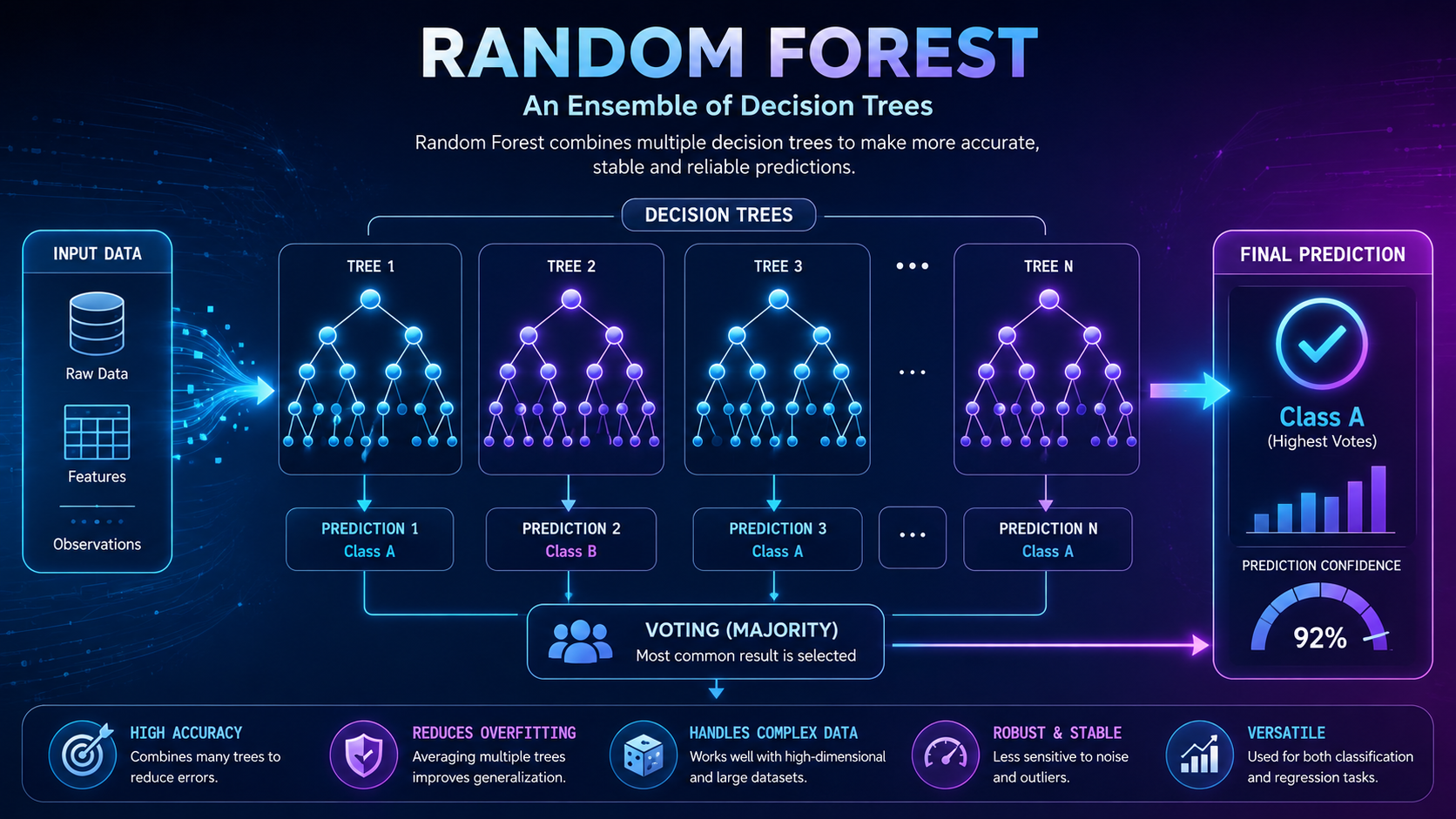
Random Forest is a machine learning algorithm that combines many decision trees to make more accurate and reliable predictions. Instead of relying on one tree, Random Forest uses multiple trees together and combines their results to reduce errors and improve performance.
It is one of the most popular supervised learning algorithms because it works well for classification and prediction tasks, handles large datasets efficiently, and reduces overfitting better than a single decision tree.
Instead of depending on one decision tree, Random Forest creates an entire “forest” of trees and combines their predictions to produce a more accurate final answer.
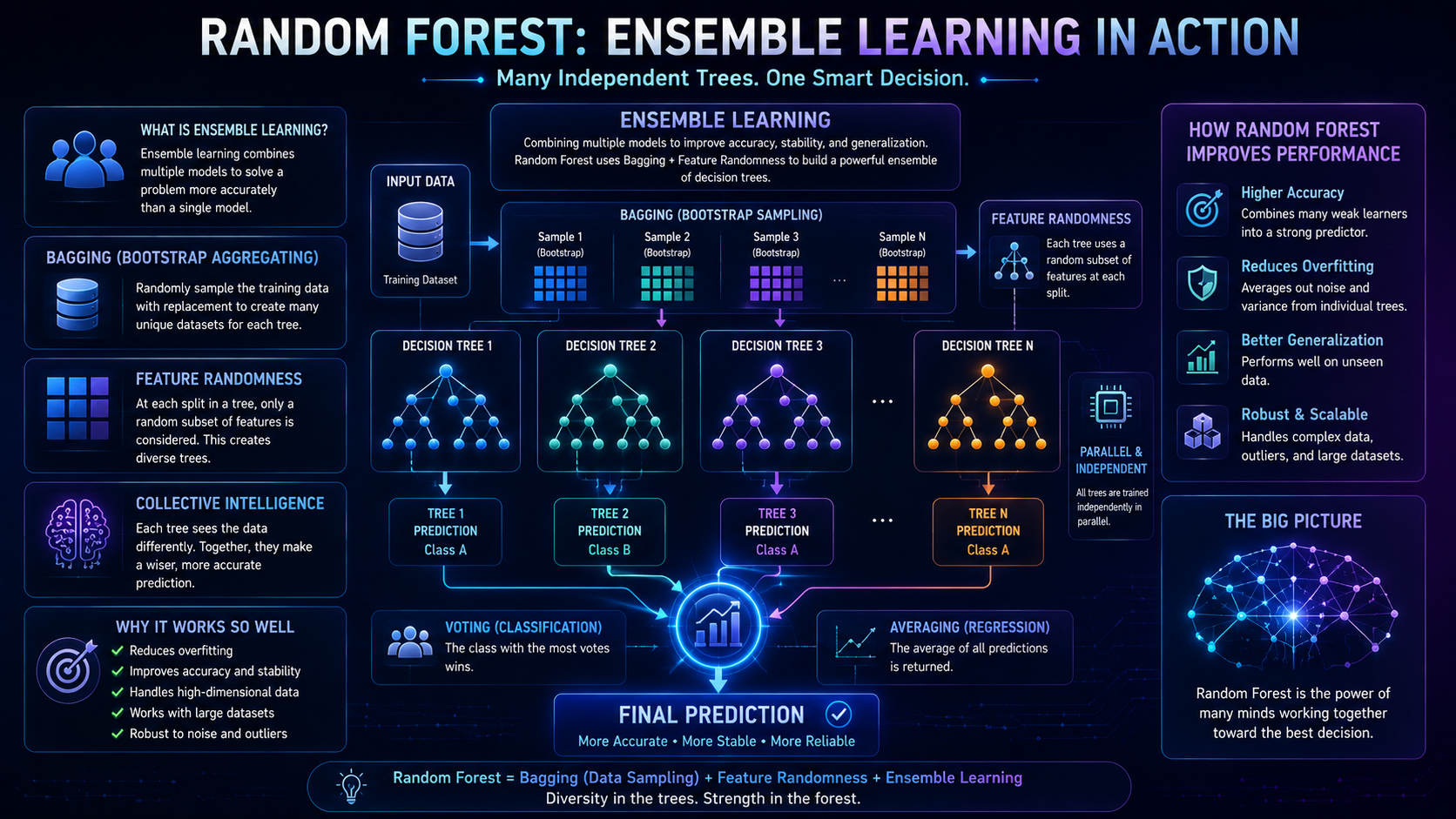
This technique is called ensemble learning, which means combining several machine learning models to improve overall performance.
Think of it like asking one doctor for a diagnosis versus asking 100 doctors and taking the majority opinion. The larger group is usually more reliable because individual mistakes are balanced out by the collective decision.
Random Forest works the same way.
Each decision tree analyzes data independently, and the forest combines all predictions to create the final result.
Random Forest can be used for:
- Classification tasks (Example: spam vs non-spam emails)
- Regression tasks (Example: predicting house prices)
Because it performs well in many different situations, Random Forest is considered one of the most practical and beginner-friendly machine learning algorithms.
Random Forest is one of the most widely used supervised machine learning algorithms because it delivers strong predictive performance while reducing overfitting.
Why Is It Called Random Forest?
The name “Random Forest” comes from two important ideas behind the algorithm.
“Forest” Refers to Multiple Trees
A Random Forest contains many decision trees working together.
Instead of using one tree, the algorithm builds an entire collection — or forest — of trees.
“Random” Refers to Random Sampling
The algorithm introduces randomness in two major ways:
- Each tree trains on a random sample of the dataset
- Each tree only considers random subsets of features during training
This randomness helps create diverse trees that make different decisions, which improves the overall accuracy of the model.
How Random Forest Works

Random Forest may sound complicated at first, but the process is actually straightforward when broken into steps.
Step 1: Collect Training Data
The algorithm starts with a dataset containing input features and known outputs.
Example:
| Age | Income | Bought Product |
| 25 | 40k | Yes |
| 45 | 90k | No |
| 30 | 60k | Yes |
The goal is to learn patterns from this data.
Step 2: Create Random Data Samples
Random Forest does not train every tree on the exact same dataset.
Instead, it creates random subsets of the training data using a method called bootstrap sampling.
Imagine 100 analysts studying slightly different versions of the same report. Each analyst notices different patterns and reaches slightly different conclusions.
This diversity helps the forest make stronger predictions overall.
Step 3: Build Decision Trees
Each random dataset is used to train a separate decision tree.
The tree asks questions about the data, such as:
- Is income above 50K?
- Is age above 35?
Each answer creates branches that eventually lead to a prediction.
Every tree learns slightly different patterns because each one sees different data.
Step 4: Random Feature Selection
Random Forest adds another layer of randomness.
When making splits, each tree only considers a random subset of features instead of all available features.
For example, a tree may only evaluate:
- Age
- Income
while ignoring:
- Location
- Gender
- Purchase history
This prevents all trees from becoming too similar and helps reduce overfitting.
Step 5: Combine Predictions
After all trees make predictions:
- Classification tasks use majority voting
- Regression tasks use averaging
Example:
| Tree | Prediction |
| Tree 1 | Spam |
| Tree 2 | Spam |
| Tree 3 | Not Spam |
| Tree 4 | Spam |
Final prediction:
✅ Spam
The forest selects the most common prediction.
How Random Forest Identifies Important Features
One valuable capability of Random Forest is its ability to measure feature importance. Feature importance helps identify which variables have the greatest impact on a model’s predictions.
For example, when predicting house prices, a Random Forest model may determine that location, square footage, and number of bedrooms are the most influential factors.
This ability helps businesses and researchers better understand their data while also improving model performance.
To learn more about working with features, see Feature Engineering Explained and Feature Selection vs Feature Extraction.
Example of Random Forest in Real Life
Predicting Loan Approval
Imagine a bank wants to decide whether to approve a loan application.
The dataset may include:
- Income
- Credit score
- Employment history
- Debt level
- Age
Each decision tree studies different parts of the data and identifies different patterns.
One tree may focus heavily on income.
Another may focus more on credit score.
Another may detect patterns related to debt.
After all trees analyze the application, the forest combines their predictions and votes on whether the loan should be approved.
This approach is often more accurate and stable than relying on a single decision tree.
Key Concepts Beginners Must Understand
Decision Trees
Random Forest is built from decision trees.
A decision tree is a flowchart-like model that asks questions about data to make predictions.
If you are new to this concept, reading Decision Trees Explained first can make Random Forest much easier to understand.
Ensemble Learning
Random Forest is an example of ensemble learning.
Instead of using one machine learning model, ensemble learning combines multiple models together to improve results.
This often leads to:
- Better accuracy
- More stability
- Lower risk of errors
Overfitting
A single decision tree can memorize training data too closely. This problem is called overfitting.
An overfitted model performs well on training data but poorly on new data.
Random Forest reduces overfitting because:
- Multiple trees are used
- Trees see different data
- Predictions are combined together
This creates a more generalized and reliable model.
You can learn more in Overfitting vs Underfitting Explained.
Feature Importance
One of Random Forest’s biggest advantages is its ability to measure feature importance.
This means the model can identify which variables matter most.
For example, when predicting loan approvals:
- Credit score may be highly important
- Income may matter slightly less
- Hair color may have no importance at all
Businesses use this information to better understand customer behavior, financial risk, and important decision-making factors.
Types of Random Forest Tasks
Classification Random Forest
Classification predicts categories or labels.
Examples include:
- Spam or not spam
- Fraud or not fraud
- Disease or healthy
The output is a category rather than a number.
Regression Random Forest
Regression predicts continuous numerical values.
Examples include:
- House prices
- Weather forecasts
- Product demand
The output is a number instead of a category.
Real-World Applications of Random Forest

Healthcare
Random Forest helps doctors and hospitals analyze medical data and predict diseases.
Examples include:
- Cancer detection
- Heart disease prediction
- Medical image analysis
Because it handles complex datasets well, it is widely used in healthcare AI systems.
Finance
Banks and financial institutions use Random Forest for:
- Fraud detection
- Credit scoring
- Risk analysis
The model can quickly identify suspicious patterns and unusual financial behavior.
E-Commerce
Online stores use Random Forest to:
- Recommend products
- Predict customer behavior
- Forecast sales demand
This improves personalization and customer experience.
Cybersecurity
Cybersecurity systems use Random Forest to detect:
- Malware
- Phishing attacks
- Intrusion attempts
Its pattern-recognition abilities make it valuable for security monitoring.
Marketing
Marketing teams use Random Forest to predict:
- Customer churn
- Advertising success
- Buying behavior
This helps businesses make smarter marketing decisions.
When Should You Use Random Forest?
Random Forest is often a great choice when you need accurate predictions without requiring extensive model tuning. Because it combines the results of multiple decision trees, it is generally more reliable and less prone to overfitting than a single Decision Tree.
Random Forest is commonly used for:
- Fraud detection
- Customer behavior prediction
- Medical diagnosis support
- Financial forecasting
- Product recommendation systems
- Risk assessment
It is especially useful when working with large datasets that contain many variables and complex relationships.
For simpler and more interpretable models, see Decision Trees Explained. For broader ensemble techniques, see Ensemble Learning Explained.
Advantages of Random Forest
| Advantage | Explanation |
| High Accuracy | Multiple trees improve prediction quality |
| Reduces Overfitting | More reliable than a single decision tree |
| Handles Large Datasets | Works well with many records and features |
| Flexible | Supports both classification and regression |
| Feature Importance | Identifies which variables matter most |
| Handles Missing Data | Performs reasonably well with incomplete information |
Random Forest is often considered one of the safest machine learning algorithms because it performs well in many situations without requiring extremely advanced tuning.
Limitations of Random Forest
| Limitation | Explanation |
| Slower Training | Many trees require more computing power |
| Harder to Interpret | More difficult to visualize than one decision tree |
| Larger Models | Forests can consume more memory |
| Increased Complexity | Large forests can become difficult to manage |
Although Random Forest is powerful, simpler models may sometimes be preferred when explainability is more important than prediction accuracy.
Why Does Random Forest Reduce Overfitting?
A single Decision Tree can sometimes memorize training data too closely, leading to overfitting. Random Forest helps solve this problem by combining predictions from many different trees.
Because each tree learns from slightly different data and makes independent predictions, the final result is usually more balanced and generalizable.
This is one reason Random Forest is often considered one of the most reliable machine learning algorithms for beginners and professionals alike.
To learn more, see Overfitting vs Underfitting Explained.
Random Forest vs Related Algorithms

Random Forest vs Decision Trees
| Feature | Decision Tree | Random Forest |
| Number of Trees | One | Many |
| Accuracy | Moderate | Higher |
| Overfitting Risk | High | Lower |
| Stability | Less stable | More stable |
| Speed | Faster | Slower |
Random Forest improves many weaknesses found in individual decision trees.
Random Forest vs Neural Networks
| Feature | Random Forest | Neural Networks |
| Best For | Structured data | Complex unstructured data |
| Training Complexity | Easier | More difficult |
| Data Requirements | Moderate | Often very large |
| Interpretability | Better | Usually harder to explain |
Neural networks are heavily used in Deep Learning Explained and advanced AI systems like image recognition and large language models.
Random Forest vs Gradient Boosting
Both algorithms use multiple decision trees, but they work differently.
- Random Forest builds trees independently
- Gradient Boosting builds trees sequentially to correct previous mistakes
Gradient Boosting can sometimes achieve higher accuracy, but it usually requires more tuning and careful optimization.
Random Forest Compared to Other Machine Learning Algorithms
| Algorithm | Main Purpose | Key Strength |
| Decision Trees | Classification and regression | Easy to understand |
| Random Forest | Ensemble prediction | Higher accuracy and reduced overfitting |
| Logistic Regression | Classification | Simple and interpretable |
| Support Vector Machines | Classification | Strong performance on complex boundaries |
| Neural Networks | Pattern recognition | Handles highly complex data |
Random Forest is often viewed as an improvement over Decision Trees because it combines the predictions of many trees rather than relying on a single model.
Random Forest in the Bigger AI Landscape
Random Forest belongs to the broader field of Machine Learning Explained, which itself is part of Artificial Intelligence Explained.
It is most closely connected to:
- Supervised Learning Explained
- Decision Trees Explained
- Model Evaluation Metrics Explained
- Feature Engineering Explained
Unlike Unsupervised Learning Explained, Random Forest requires labeled training data.
It also differs from Reinforcement Learning Explained, where AI learns through rewards and trial-and-error interactions.
Although Random Forest is not part of deep learning, understanding it provides an excellent foundation before exploring Neural Networks Explained and Deep Learning Explained.
Future Outlook of Random Forest

Even with the rapid growth of deep learning, Random Forest remains highly valuable because many business problems involve structured data like spreadsheets, databases, and financial records.
In many situations, Random Forest still performs extremely well while being easier to train than deep neural networks.
Future developments may include:
- Faster automated training systems
- Better explainable AI tools
- Hybrid AI systems combining forests and deep learning
- Improved AutoML integration
- Better feature selection methods
Although Deep Learning and Neural Networks receive significant attention in modern AI, Random Forest remains one of the most trusted machine learning algorithms for structured data problems. Its balance of accuracy, interpretability, and reliability continues to make it a popular choice in healthcare, finance, cybersecurity, and business analytics.
As organizations increasingly rely on data-driven decision-making, Random Forest is expected to remain a valuable tool for predictive modeling and machine learning applications.
As AI continues evolving, Random Forest will likely remain one of the most practical machine learning algorithms for businesses, researchers, and beginner data scientists.
Recommended External Resources
To continue learning about Random Forest and machine learning, explore these trusted educational resources:
These sources provide beginner-friendly explanations and practical examples.
FAQ About Random Forest
What is Random Forest in simple terms?
Random Forest is a machine learning algorithm that combines many decision trees to make more accurate predictions.
Why is Random Forest important?
It improves prediction accuracy while reducing overfitting compared to individual decision trees.
Is Random Forest supervised or unsupervised learning?
Random Forest is a supervised learning algorithm because it trains on labeled data.
What is Random Forest used for?
It is used for fraud detection, medical diagnosis, recommendation systems, cybersecurity, and customer behavior prediction.
Why is Random Forest better than a single Decision Tree?
Random Forest often produces more accurate predictions because it combines the results of many decision trees. This reduces overfitting and improves overall model reliability.
Can Random Forest handle large datasets?
Yes, Random Forest works very well with large datasets and many features.
Is Random Forest part of deep learning?
No, Random Forest is a traditional machine learning algorithm, not a deep learning model.
Does Random Forest reduce overfitting?
Yes, the randomness and averaging process help reduce overfitting significantly.
Can Random Forest predict numbers?
Yes, Random Forest supports regression tasks that predict numerical values such as prices and temperatures.
Is Random Forest difficult to learn?
No, Random Forest is considered one of the more beginner-friendly machine learning algorithms.
Conclusion
Random Forest is one of the most powerful and beginner-friendly machine learning algorithms available today. By combining many decision trees together, it improves prediction accuracy, reduces overfitting, and performs well across a wide range of real-world applications.
Its flexibility and reliability make it valuable in industries like healthcare, finance, cybersecurity, marketing, and e-commerce.
Most importantly, Random Forest introduces important machine learning concepts such as ensemble learning, feature importance, and predictive modeling in a way that is easier for beginners to understand.
As you continue exploring AI and machine learning, Random Forest is an essential algorithm that builds a strong foundation for understanding more advanced systems.
Recommended Next Topics
Continue learning with these related AllForTheAI.com articles:
- Artificial Intelligence Explained
- Machine Learning Explained
- Decision Trees Explained
- Supervised Learning Explained
- Overfitting vs Underfitting Explained
- Neural Networks Explained
- Deep Learning Explained
- Model Evaluation Metrics Explained
- Machine Learning Algorithms Overview
- Ensemble Learning Explained
- Feature Engineering Explained
- Accuracy vs Precision vs Recall