Introduction: Why Model Evaluation Matters
Imagine building an AI model that claims 95% accuracy… but still fails when it matters most.
For example:
- A fraud detection system that misses fraudulent transactions
- A medical model that overlooks serious diseases
This is why model evaluation metrics are essential.
They help you go beyond simple accuracy and truly understand:
- How your model behaves
- Where it makes mistakes
- Whether it’s safe to use in real-world situations
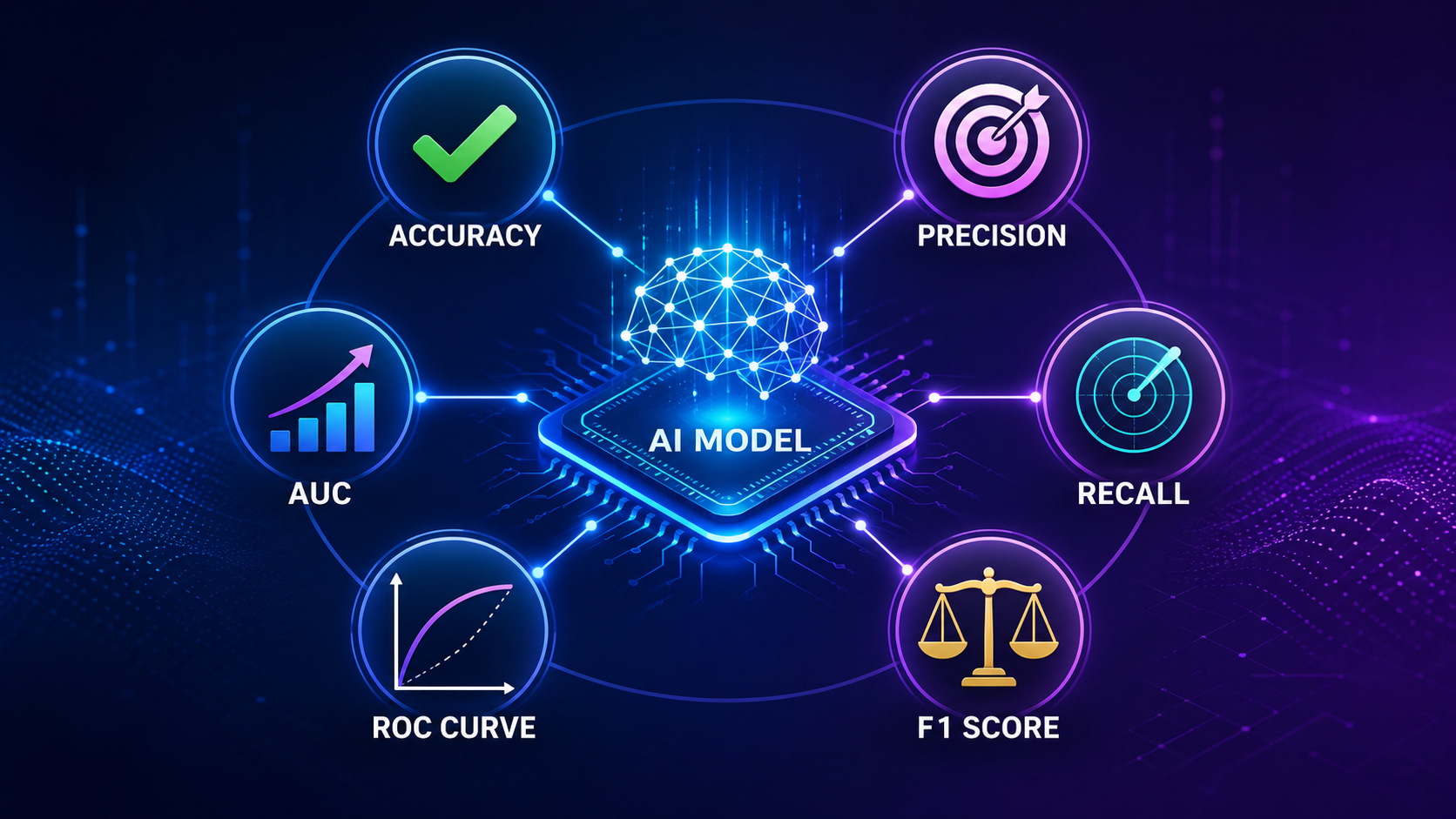
What Are Model Evaluation Metrics?
Model evaluation metrics are essential in machine learning and artificial intelligence because they help measure prediction accuracy, improve model performance, and identify potential errors.
Model evaluation metrics are tools used to measure the performance of machine learning models.
They act like a scorecard, helping you determine how well your model is doing.
Simple Analogy
Think of a student taking a test:
- The model = the student
- The test data = the exam
- The metrics = the score
Without metrics, you wouldn’t know if the student actually learned anything.
How Model Evaluation Metrics Work (Step-by-Step)
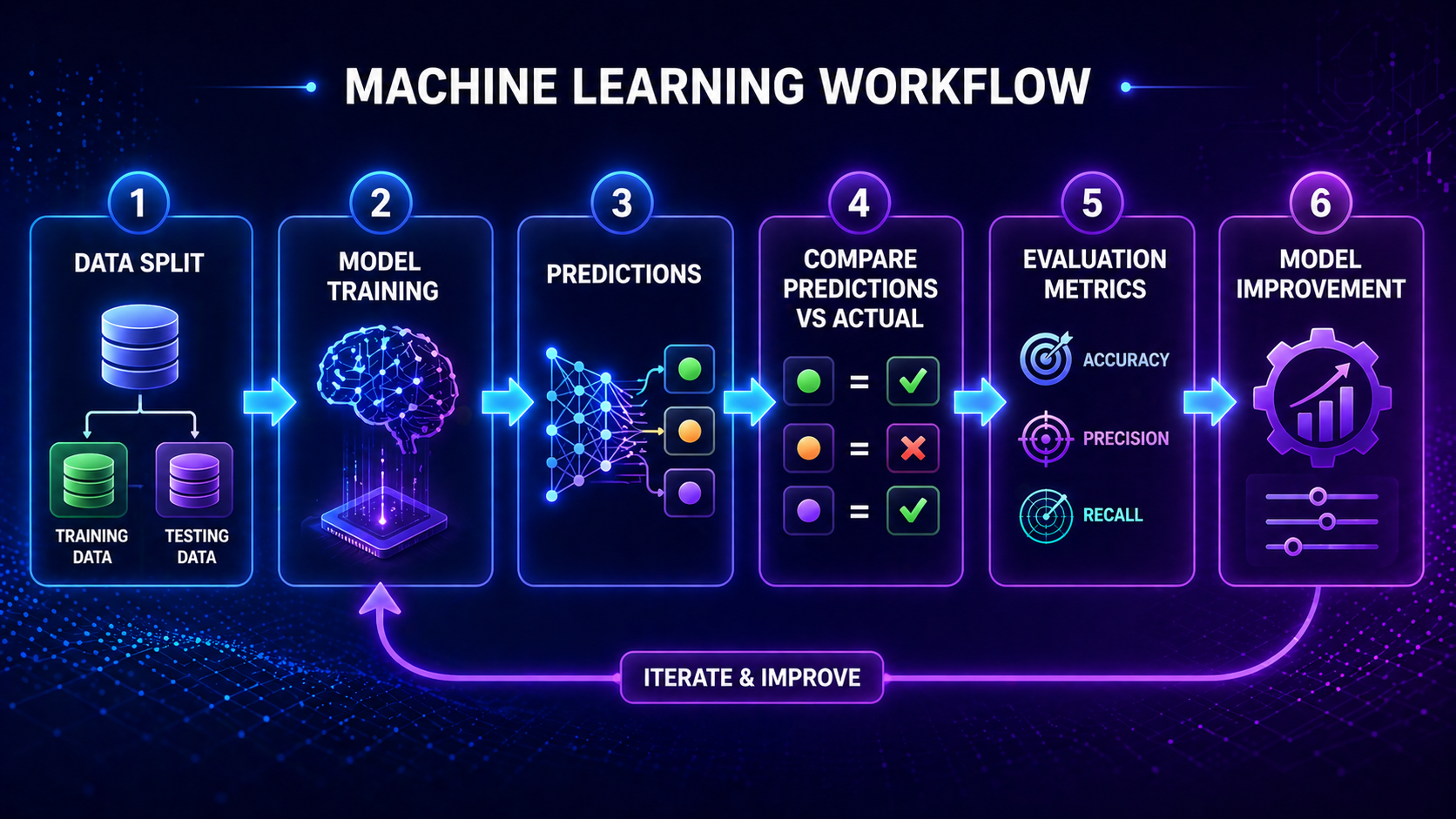
Step 1: Train the Model
The model learns patterns from training data.
👉 Related: Training vs Testing Data
Step 2: Test on New Data
The model is evaluated on unseen data to simulate real-world performance.
Step 3: Compare Predictions to Actual Values
You compare what the model predicted vs what actually happened.
Step 4: Calculate Metrics
Metrics are calculated based on:
- Correct predictions
- Incorrect predictions
- Types of errors
Step 5: Interpret the Results
You decide:
- Is the model reliable?
- Does it need improvement?
- Is it ready for deployment?
Key Concepts Beginners Must Understand
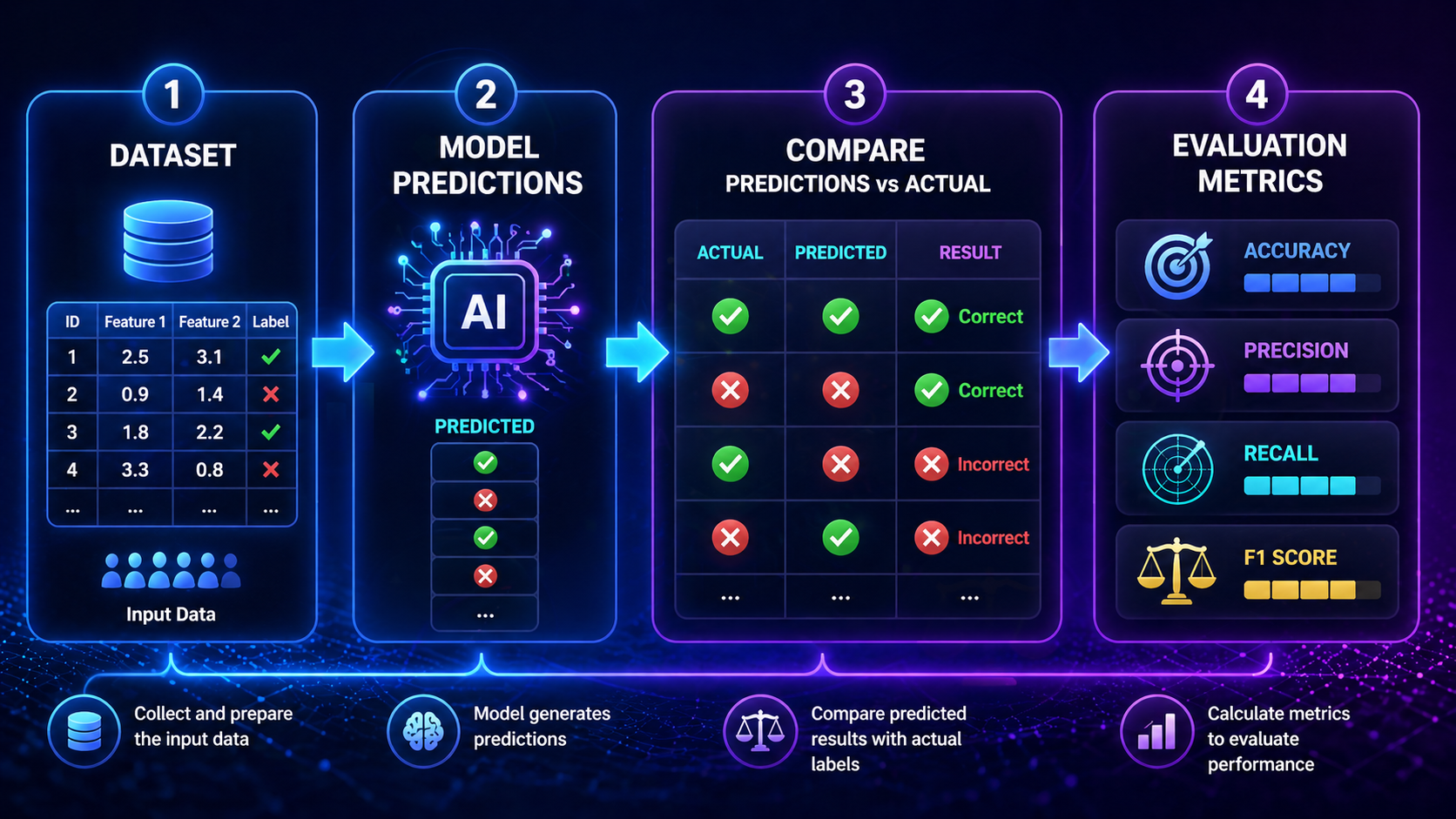
Predictions vs Actual Values
- Prediction = model output
- Actual = real answer
Not All Errors Are Equal
This is one of the most important ideas in machine learning.
Example:
- Spam email marked as important → minor issue
- Cancer diagnosis missed → critical issue
👉 Metrics help you prioritize the right kind of accuracy.
Trade-Offs Between Metrics
Improving one metric can worsen another.
Example:
- Increasing precision may reduce recall
👉 This is called the precision-recall tradeoff.
No Single Best Metric
The “best” metric depends entirely on:
- Your problem
- Your data
- The cost of mistakes
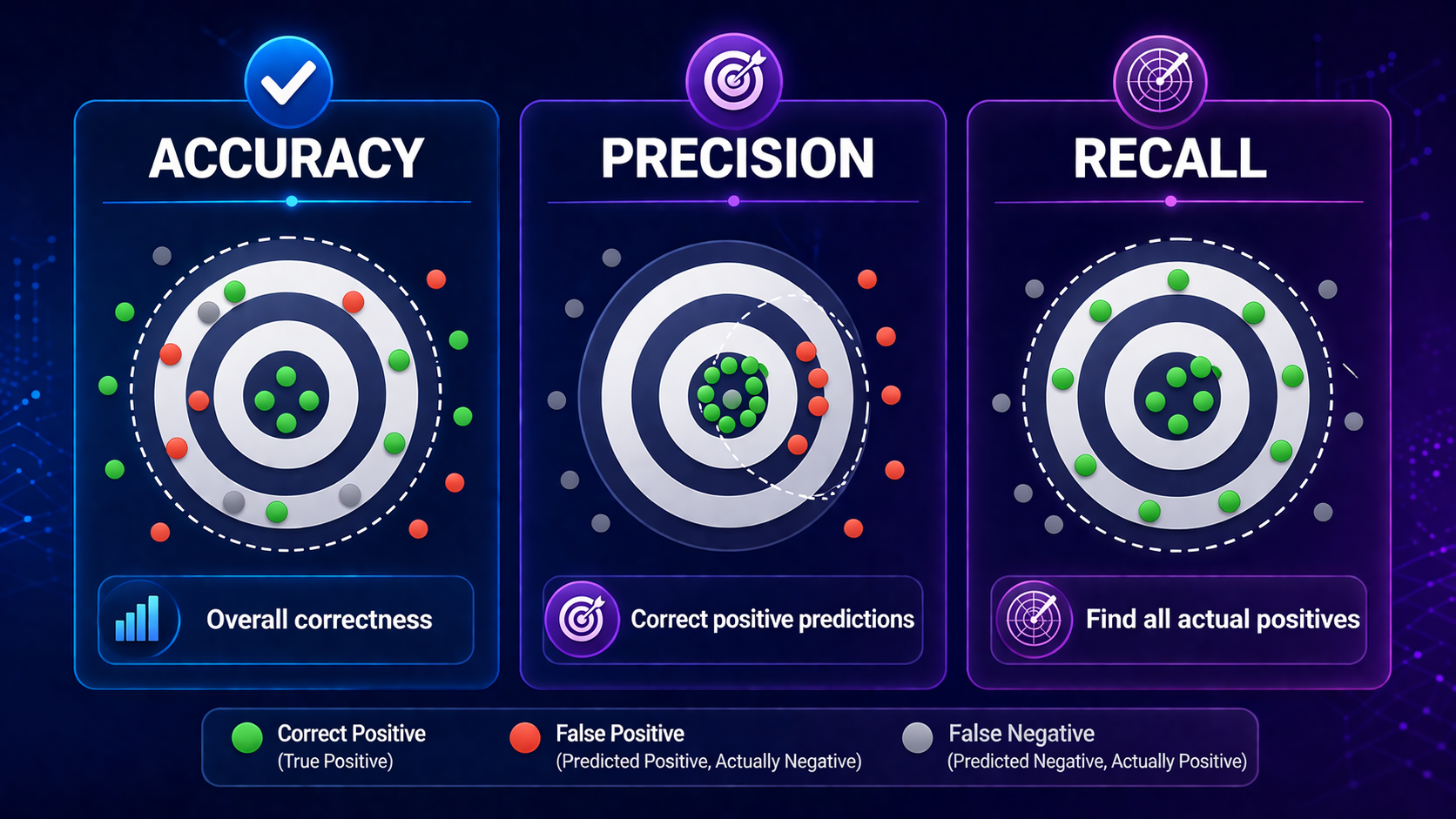
Types of Model Evaluation Metrics
Metrics like accuracy, precision, recall, and confusion matrices help reduce overfitting and improve the reliability of machine learning systems.
1. Classification Metrics (Categories)
Used when predicting categories like:
- Spam vs not spam
- Fraud vs normal
Common Metrics
| Metric | What It Means | Example Insight |
| Accuracy | Overall correctness | Good for balanced datasets |
| Precision | Correct positive predictions | Avoid false alarms |
| Recall | Finds all actual positives | Avoid missing critical cases |
| F1 Score | Balance of precision & recall | Useful for uneven data |
👉 Related:
- Accuracy vs Precision vs Recall
- F1 Score Explained
- Confusion Matrix Explained
2. Regression Metrics (Numbers)
Used when predicting values like:
- House prices
- Stock trends
| Metric | What It Means | Why It Matters |
| MAE | Average error | Easy to understand |
| MSE | Penalizes big errors | Highlights large mistakes |
| RMSE | Square root of MSE | Same units as output |
The Confusion Matrix (Core Concept)

A confusion matrix is a table that shows how your model performs in detail.
It includes:
- True Positives
- True Negatives
- False Positives
- False Negatives
Why It Matters
Most evaluation metrics are derived from this matrix.
Choosing the Right Metric (Most Important Section)
Choosing the right metric is critical.
Here’s a practical decision guide:
| Scenario | Best Metric | Why |
| Balanced dataset | Accuracy | All errors are equally important |
| Fraud detection | Recall | Missing fraud is costly |
| Spam detection | Precision | Avoid false positives |
| Medical diagnosis | Recall + F1 | Missing cases is dangerous |
| Imbalanced dataset | F1 Score | Balances performance |
Real-World Scenario
Fraud Detection System:
- False Negative = missed fraud (very bad)
- False Positive = flagged normal transaction (less bad)
👉 You prioritize recall over accuracy
Real-World Applications of Model Evaluation Metrics
Healthcare
- Disease detection
- Diagnosis accuracy
Finance
- Fraud detection
- Risk assessment
E-commerce
- Recommendation systems
- Customer behavior prediction
Self-Driving Cars
- Object detection accuracy
- Safety-critical decisions
AI Systems & Chatbots
- Response relevance
- User satisfaction
👉 Related:
- Artificial Intelligence Explained
- Machine Learning Explained
- Deep Learning Explained
- Neural Networks Explained
Advantages of Model Evaluation Metrics
Clear Performance Measurement
Metrics give objective results.
Model Comparison
You can compare multiple models easily.
Error Analysis
They reveal where models fail.
Better Decision-Making
Helps choose the best model for real-world use.
Limitations of Model Evaluation Metrics
Can Be Misleading
High accuracy doesn’t always mean good performance.
Context Matters
Wrong metric = wrong conclusions.
Doesn’t Capture Real-World Impact
Metrics don’t always reflect business consequences.
Trade-Off Complexity
Balancing multiple metrics can be difficult.
Model Evaluation Metrics vs Related Concepts
Metrics vs Loss Functions
- Metrics = evaluation
- Loss functions = training guidance
Metrics vs Validation Techniques
- Metrics measure performance
- Validation improves reliability
👉 Related:
- Cross-Validation Explained
- Hyperparameter Tuning Explained
Metrics vs Overfitting
Metrics help detect overfitting:
- High training score + low test score = overfitting
👉 Related:
Future of Model Evaluation Metrics
The future of evaluation is evolving rapidly.
AI Fairness Metrics
Ensuring models are unbiased and ethical.
Human-Centered Evaluation
Measuring user satisfaction, not just accuracy.
Generative AI Metrics
Evaluating:
- Text quality
- Image realism
- Creativity
LLM Evaluation Challenges
Large language models require:
- Context understanding
- Human feedback loops
External Resources for Deeper Learning
According to IBM’s guide on model evaluation, choosing the right metric depends heavily on your specific use case and data characteristics.
Google AI’s Machine Learning Crash Course also provides an excellent breakdown of classification metrics and their real-world applications.
FAQ: Model Evaluation Metrics Explained
What are model evaluation metrics in simple terms?
Model evaluation metrics are measurements used to assess how well a machine learning model performs on data.
Why are model evaluation metrics important?
They help determine whether a model is accurate, reliable, and ready for real-world use.
What is the most commonly used evaluation metric?
Accuracy is the most commonly used metric, but it can be misleading on imbalanced datasets.
What is the difference between precision and recall?
Precision measures how many predicted positives are correct, while recall measures how many actual positives are correctly identified.
What is a confusion matrix in machine learning?
A confusion matrix is a table that shows correct and incorrect predictions, including true positives, false positives, true negatives, and false negatives.
What is the F1 score and why is it useful?
The F1 score combines precision and recall into a single metric, making it useful for imbalanced datasets.
How do you choose the best evaluation metric?
You choose the best metric based on your problem type and the cost of different errors.
Can one evaluation metric be enough?
No, using multiple metrics gives a more complete understanding of model performance.
What is the best metric for imbalanced datasets?
The F1 score or recall is often best for imbalanced datasets because accuracy can be misleading.
How do evaluation metrics help detect overfitting?
Evaluation metrics reveal overfitting when a model performs well on training data but poorly on test data.
Are evaluation metrics used in deep learning models?
Yes, evaluation metrics are essential for measuring the performance of deep learning and neural network models.
Explore More Model Evaluation Guides
If you want to continue learning about model evaluation, prediction accuracy, and machine learning performance, explore these beginner-friendly guides covering datasets, training systems, neural networks, and optimization techniques.
Artificial Intelligence Foundations
👉 Artificial Intelligence Explained
Data & Training
👉 What Is a Dataset in Machine Learning
👉 Data Preprocessing Explained
👉 Feature Engineering Explained
Model Evaluation & Optimization
👉 Accuracy vs Precision vs Recall
Neural Networks & Deep Learning
👉 Deep Learning vs Machine Learning
These guides will help you build a stronger understanding of machine learning evaluation systems and modern AI technologies.
Conclusion
Model evaluation metrics are the foundation of reliable machine learning systems.
They help you:
- Measure performance
- Detect weaknesses
- Compare models
- Make better decisions
Without proper evaluation, even the most advanced AI systems can fail.
As AI continues to evolve — especially with deep learning and generative models — understanding evaluation metrics will become even more important.