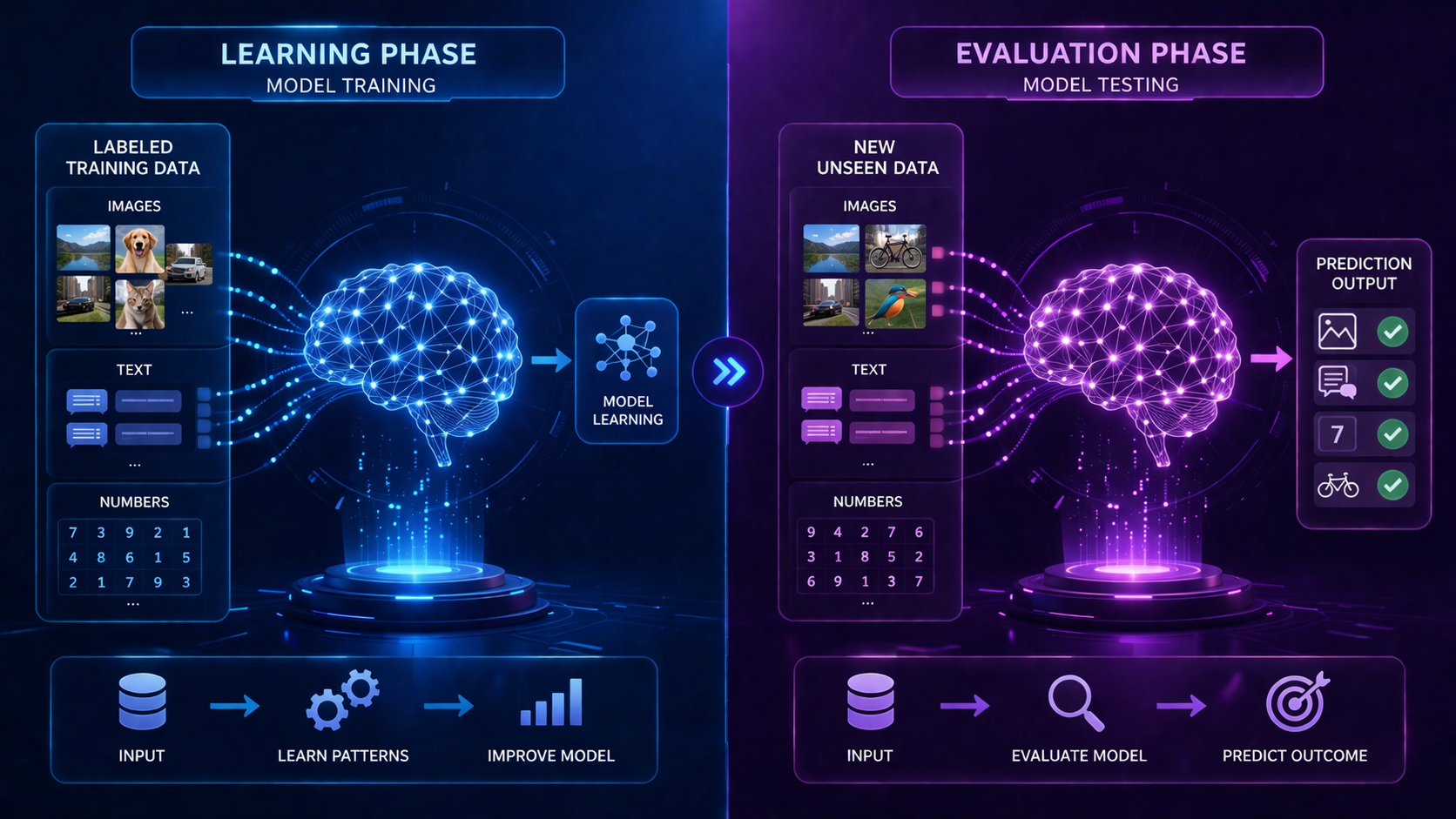
What Is Training vs Testing Data?
Training vs testing data refers to splitting a dataset into two parts: one used to train a machine learning model (training data) and another used to evaluate its performance (testing data). This ensures the model can accurately predict outcomes on new, unseen data instead of simply memorizing patterns.
In machine learning, data is used to teach computers how to make decisions. But simply feeding all your data into a model isn’t enough—you need a way to train the model and then test what it has learned.
That’s where training vs testing data comes in.
- Training Data: The data used to teach the model
- Testing Data: The data used to evaluate how well the model performs
Training and testing data are essential parts of machine learning systems because they help artificial intelligence models learn patterns and measure prediction accuracy.
A Simple Mental Model
Imagine you have 1,000 photos of cats and dogs:
- You use 800 images to train the model
- You keep 200 images hidden as a final test
The model learns patterns (like ears, fur, and shapes) from the 800 images.
Then you ask:
👉 Can it correctly identify animals in the 200 images it has never seen before?
That’s exactly how training vs testing works.
Why Training vs Testing Data Matters
Without separating data, you can’t tell if your model truly understands the problem.
If you test on the same data you trained on:
- The model may appear perfect
- But it may have simply memorized the answers
This leads to overfitting (see: Overfitting vs Underfitting).
Key Benefits of Splitting Data
- Measures real-world performance
- Prevents memorization
- Builds trustworthy AI systems
- Helps compare different models fairly
How Training vs Testing Data Works (Step-by-Step)
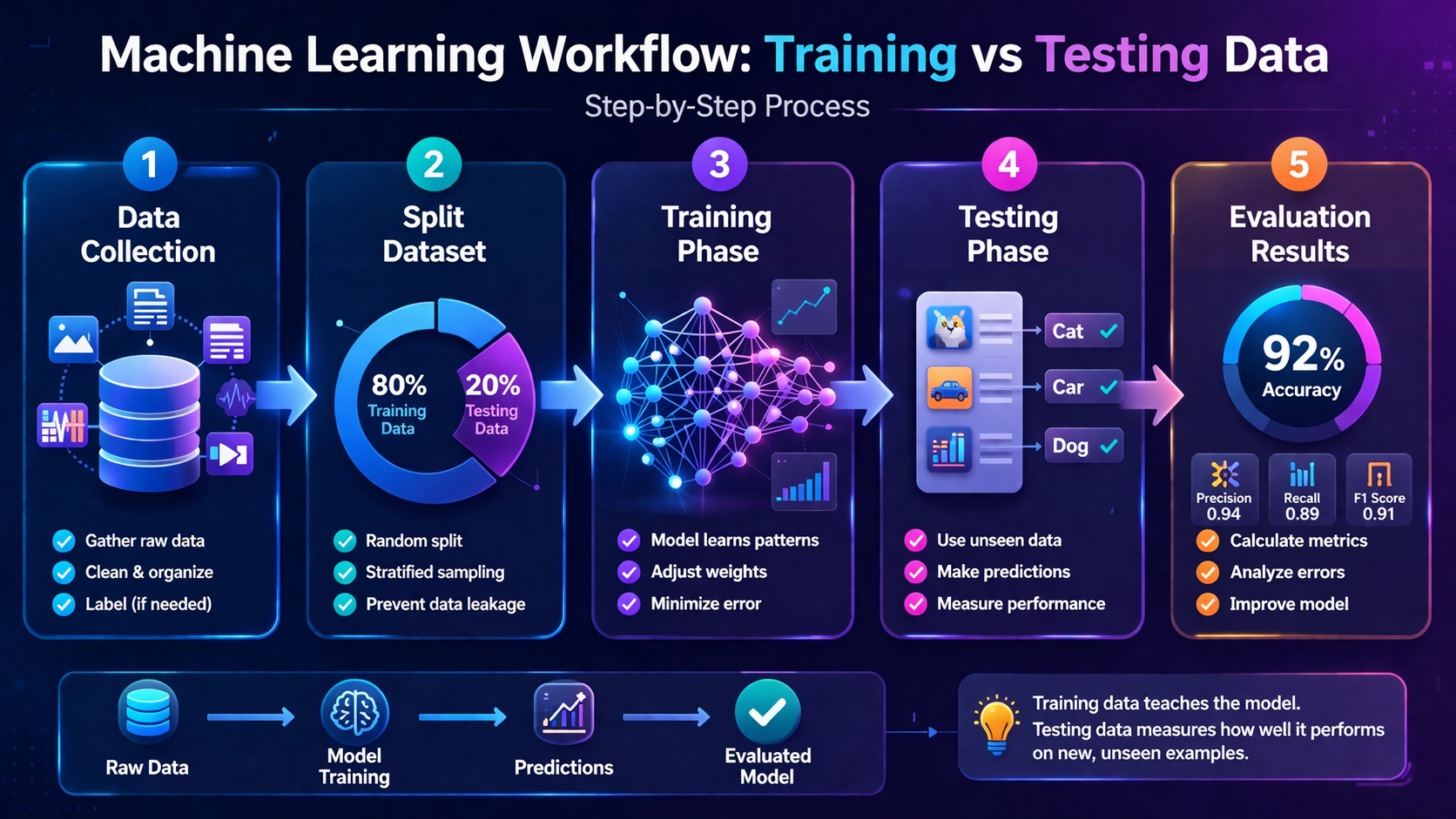
Step 1: Collect a Dataset
First, gather data (see: What Is a Dataset in Machine Learning).
Examples:
- Images (cats vs dogs)
- Text (emails, reviews)
- Numbers (sales, temperature)
Step 2: Split the Dataset
The dataset is divided into two main parts:
| Dataset Type | Purpose | Typical Size |
| Training Data | Teach the model | 70–80% |
| Testing Data | Evaluate performance | 20–30% |
Step 3: Train the Model
The model learns patterns from the training data.
For example:
- Identifying features in images
- Learning relationships between inputs and outputs
This is where algorithms (see: Machine Learning Algorithms Overview) learn from data.
Step 4: Test the Model
Now the model is evaluated using data it has never seen before.
👉 Can the model generalize to new data?
Step 5: Measure Performance
Performance is measured using metrics like:
- Accuracy
- Precision
- Recall
(See: Model Evaluation Metrics Explained)
Visualizing Training vs Testing Data
Think of the process as a simple workflow:
Dataset → Split → Train → Test → Evaluate → Improve
- The model learns from one portion
- Then proves itself on another
- Results guide future improvements
Key Concepts Beginners Must Understand
Generalization
The model can perform well on new, unseen data.
Overfitting
The model performs well on training data but poorly on testing data.
Underfitting
The model performs poorly on both training and testing data.
Data Leakage
Testing data accidentally influences training.
Random Splitting
Data should be split randomly to avoid bias.
Proper evaluation techniques help reduce overfitting, improve model performance, and measure how accurately machine learning systems make predictions.
Types of Data Splits

Train/Test Split
- 80% training
- 20% testing
Train/Validation/Test Split
| Dataset Type | Purpose |
| Training | Learn patterns |
| Validation | Tune model settings |
| Testing | Final evaluation |
Cross-Validation
Multiple splits are used for more reliable results.
Common Mistakes When Using Training vs Testing Data
Using the Same Data for Training and Testing
Leads to overfitting and misleading results.
Poor Data Splitting
Non-random splits can bias results.
Too Small Testing Set
Gives unreliable performance.
Ignoring Real-World Differences
Training data may not reflect real-world conditions.
Data Leakage
Test data influences training.
Real-World Examples

Email Spam Detection
- Training: labeled emails
- Testing: new emails
Image Recognition
- Training: labeled images
- Testing: new images
Recommendation Systems
- Training: user behavior
- Testing: new interactions
Advantages of Training vs Testing Data

Prevents Overfitting
Training vs testing data helps prevent overfitting by ensuring the model is evaluated on data it has never seen before. This forces the model to learn general patterns instead of simply memorizing the training data.
Improves Reliability
By testing the model on separate data, you get a more realistic measure of how it will perform in real-world situations. This makes the model’s predictions more trustworthy.
Enables Fair Comparison
Using a consistent training vs testing data split allows you to compare different machine learning models fairly. Each model is evaluated under the same conditions, making results more meaningful.
Supports Continuous Improvement
Testing results help identify weaknesses in the model, allowing developers to refine and improve performance over time. This creates a continuous feedback loop for better results.
Limitations of Training vs Testing Data
Limited Data
If the dataset is too small, splitting it into training and testing sets can reduce the amount of data available for learning. This may lead to weaker model performance.
Potential Bias
If the data is not split properly, one dataset may not represent the real-world distribution. This can lead to misleading evaluation results.
Not Always Sufficient
A simple train/test split may not fully capture model performance. More advanced techniques like cross-validation are often needed for better evaluation.
Real-World Complexity
Even well-prepared testing data may not reflect real-world conditions perfectly. Models can still struggle when deployed in dynamic or unpredictable environments.
Training vs Testing Data vs Validation Data
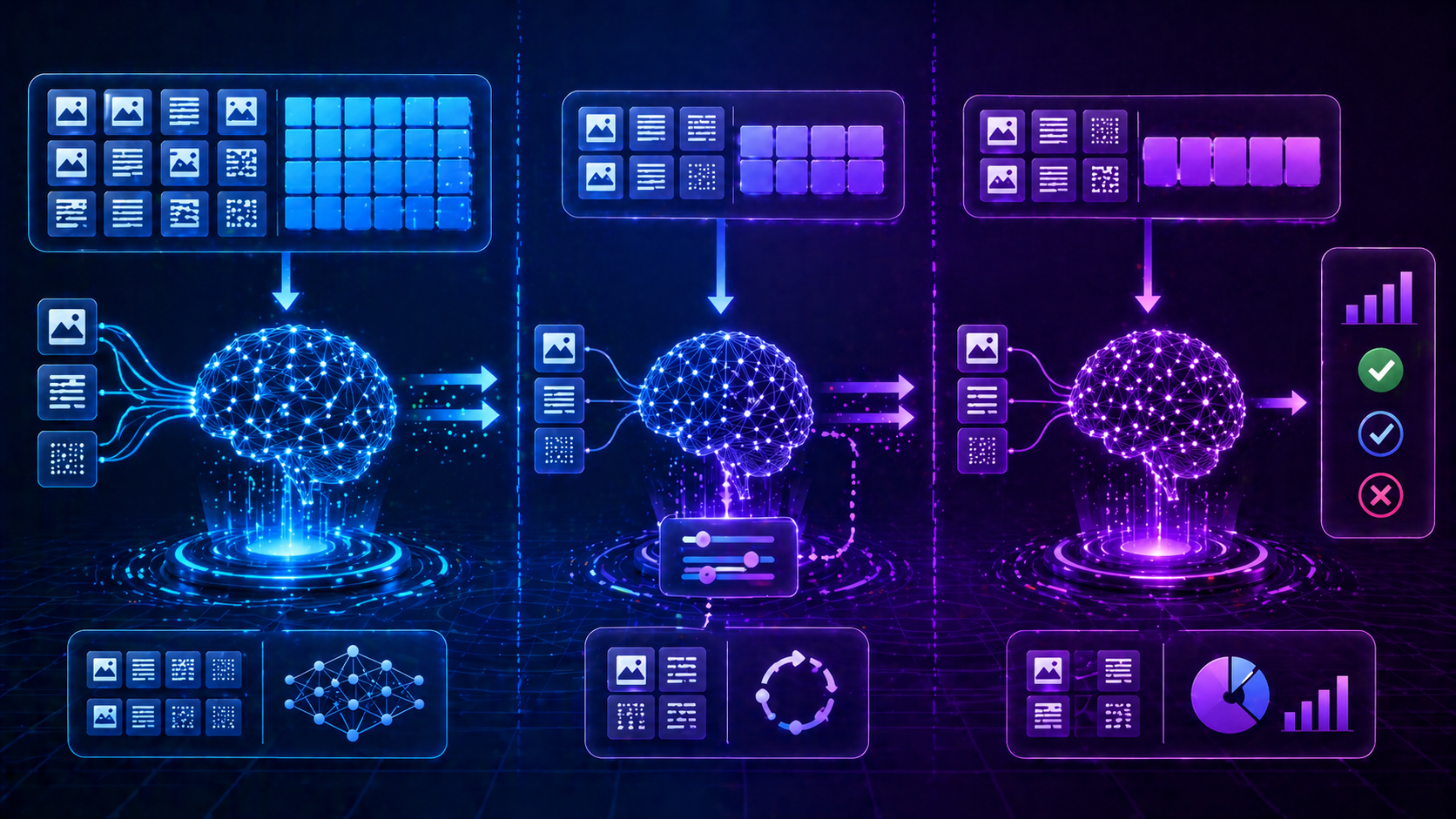
| Feature | Training Data | Testing Data | Validation Data |
| Purpose | Learn | Evaluate | Tune |
| Seen by Model | Yes | No | Sometimes |
| Role | Build | Final check | Improve |
Training vs Testing Data vs Related Concepts
- Artificial Intelligence Explained
- Machine Learning Explained
- Deep Learning Explained
- Neural Networks Explained
- Supervised Learning Explained
- Unsupervised Learning Explained
- Reinforcement Learning Explained
External Resources for Further Learning
Future of Training vs Testing Data

Automated Data Pipelines
In the future, data preparation and splitting will increasingly be handled by automated systems. Machine learning pipelines can automatically clean, split, and prepare data, reducing human error and improving efficiency.
Larger Datasets
As AI continues to grow, models are being trained on massive datasets containing millions or even billions of data points. This allows models to learn more complex patterns but also requires more careful data splitting and evaluation.
Advanced Evaluation Methods
Simple train/test splits are being supplemented with more advanced techniques like cross-validation and real-world testing. These methods provide a more accurate understanding of how models perform in different scenarios.
Continuous Learning Systems
Some modern AI systems are moving toward continuous learning, where models update themselves over time using new data. In these systems, the traditional training vs testing split becomes more dynamic and ongoing.
FAQ: Training vs Testing Data
What is the difference between training and testing data?
Training data is used to teach a machine learning model how to recognize patterns, while testing data is used to evaluate how well the model performs on new, unseen data. The key difference is that testing data is never shown during training, ensuring an unbiased evaluation.
Why can’t we use the same data for both training and testing?
Using the same data for both training and testing leads to overfitting, where the model memorizes the data instead of learning general patterns. This results in poor performance when the model encounters new data in real-world situations.
What is a typical split ratio for training vs testing data?
A common split is 70–80% training data and 20–30% testing data. However, the ideal ratio can vary depending on the size of the dataset and the complexity of the machine learning task.
What is overfitting in training vs testing data?
Overfitting occurs when a model performs very well on training data but poorly on testing data. This happens because the model has memorized the training data instead of learning patterns that generalize to new data.
What is validation data?
Validation data is a separate dataset used during model development to fine-tune parameters and improve performance. Unlike testing data, it may be used multiple times while building the model, but testing data should only be used for final evaluation.
What is data leakage?
Data leakage happens when information from the testing dataset accidentally influences the training process. This leads to overly optimistic results and makes the model appear more accurate than it actually is in real-world use.
Is training vs testing data used in deep learning?
Yes, training vs testing data is essential in deep learning. Deep learning models often require very large training datasets and carefully separated testing data to ensure accurate and reliable performance.
What is cross-validation?
Cross-validation is a technique where the dataset is split into multiple parts, and the model is trained and tested several times using different splits. This provides a more reliable estimate of model performance than a single train/test split.
Can models improve after testing?
Yes, models can improve after testing by analyzing performance results and retraining with better data or adjusted parameters. This iterative process helps refine the model and increase accuracy over time.
Why is training vs testing data important in real-world AI?
Training vs testing data is critical because it ensures that AI models can perform accurately in real-world situations. Companies like Google, Amazon, and Netflix rely on this approach to build reliable systems that work on new, unseen data.
Explore More Data & Machine Learning Guides
If you want to continue learning about training data, testing data, and machine learning systems, explore these beginner-friendly guides covering datasets, model evaluation, neural networks, and AI optimization.
Artificial Intelligence Foundations
👉 Artificial Intelligence Explained
Data & Training
👉 What Is a Dataset in Machine Learning
👉 Data Preprocessing Explained
👉 Feature Engineering Explained
👉 Feature Selection vs Feature Extraction
Neural Networks & Deep Learning
👉 Deep Learning vs Machine Learning
Model Evaluation & Optimization
👉 Model Evaluation Metrics Explained
👉 Accuracy vs Precision vs Recall
These guides will help you build a stronger understanding of machine learning training systems and modern AI technologies.
Conclusion
Training vs testing data is one of the most important foundations in machine learning. It ensures models don’t just memorize information—but actually learn patterns that apply to the real world.
👉 Mastering this concept is essential before moving on to advanced topics like cross-validation, model optimization, and deep learning systems.