
What Is Unsupervised Learning?
Every time Netflix recommends content based on users similar to you — without being told your preferences — unsupervised learning may be at work.
Unlike supervised learning, which relies on labeled answers, unsupervised learning allows artificial intelligence systems to discover hidden patterns inside raw data.
Unsupervised learning is a type of machine learning where models analyze unlabeled data to discover hidden patterns, clusters, or structures without predefined answers.
According to IBM’s machine learning overview, unsupervised learning is commonly used for clustering, dimensionality reduction, and anomaly detection in large datasets.
Instead of learning from examples with correct outputs, the model explores the data independently and identifies relationships on its own.
In simple terms:
Unsupervised learning finds patterns in data without being told what to look for.
Because there are no predefined categories like “spam” or “not spam,” the system must identify similarities, groupings, or anomalies automatically.
Unsupervised learning is especially valuable when large datasets exist but labels are unavailable, incomplete, or too expensive to create.
👉 Related: Supervised Learning Explained
How Unsupervised Learning Works
Unsupervised learning models attempt to organize data by identifying similarities, structures, and relationships between data points.
Because there are no labels, the model must:
- Analyze feature similarity
- Measure distance between data points
- Identify density patterns
- Detect clusters or anomalies
- Reduce complexity while preserving structure
The goal is not prediction — it is discovery.
Unsupervised learning answers questions like:
- Are there natural groupings in this data?
- Which items are similar?
- Are there hidden structures?
- Are there anomalies or outliers?
- Can we simplify this dataset without losing important information?
This makes unsupervised learning particularly useful for exploratory data analysis and early-stage machine learning projects.
The Two Main Types of Unsupervised Learning
Unsupervised learning typically falls into two primary categories.
1) Clustering

Clustering groups similar data points together based on shared characteristics.
The algorithm does not know what the groups represent — it simply identifies natural divisions within the dataset.
Common clustering applications:
- Grouping customers by purchasing behavior
- Segmenting users by browsing patterns
- Organizing photos by visual similarity
- Detecting unusual financial transactions
- Identifying communities in social networks
Clustering algorithms often rely on distance metrics such as Euclidean distance or cosine similarity to determine how closely related data points are.
In practice, selecting the right number of clusters and evaluating cluster quality (using methods like silhouette scores) can significantly impact results.
2) Dimensionality Reduction
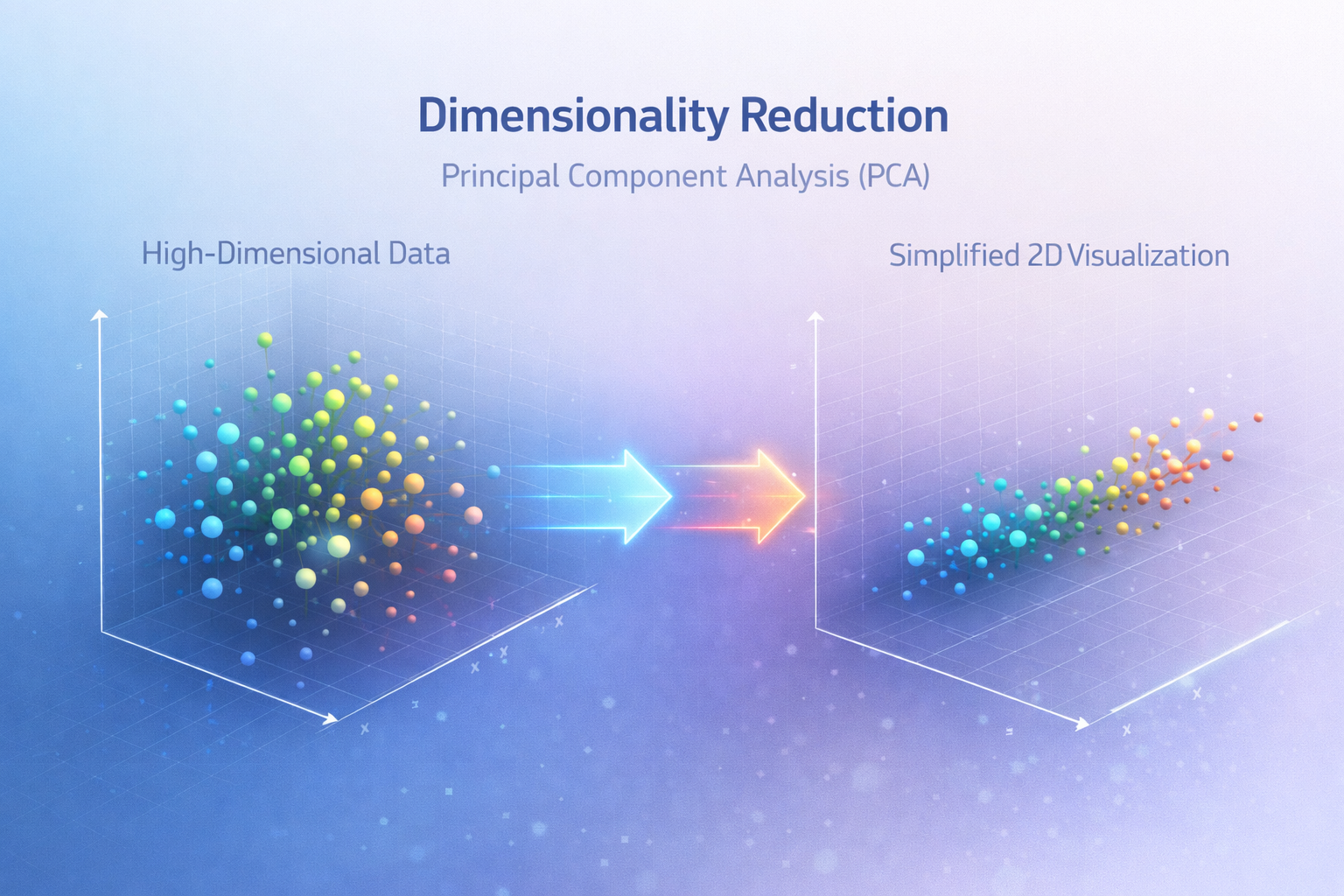
Dimensionality reduction simplifies complex datasets by reducing the number of variables while preserving essential information.
It is commonly used to:
- Visualize high-dimensional data
- Improve model efficiency
- Remove redundant features
- Speed up computation
- Reduce noise in datasets
Instead of grouping data, dimensionality reduction compresses it while maintaining structure.
This technique is especially important when working with large datasets containing dozens or hundreds of features.
Common Unsupervised Learning Algorithms
Several algorithms power modern unsupervised learning systems.
K-Means Clustering
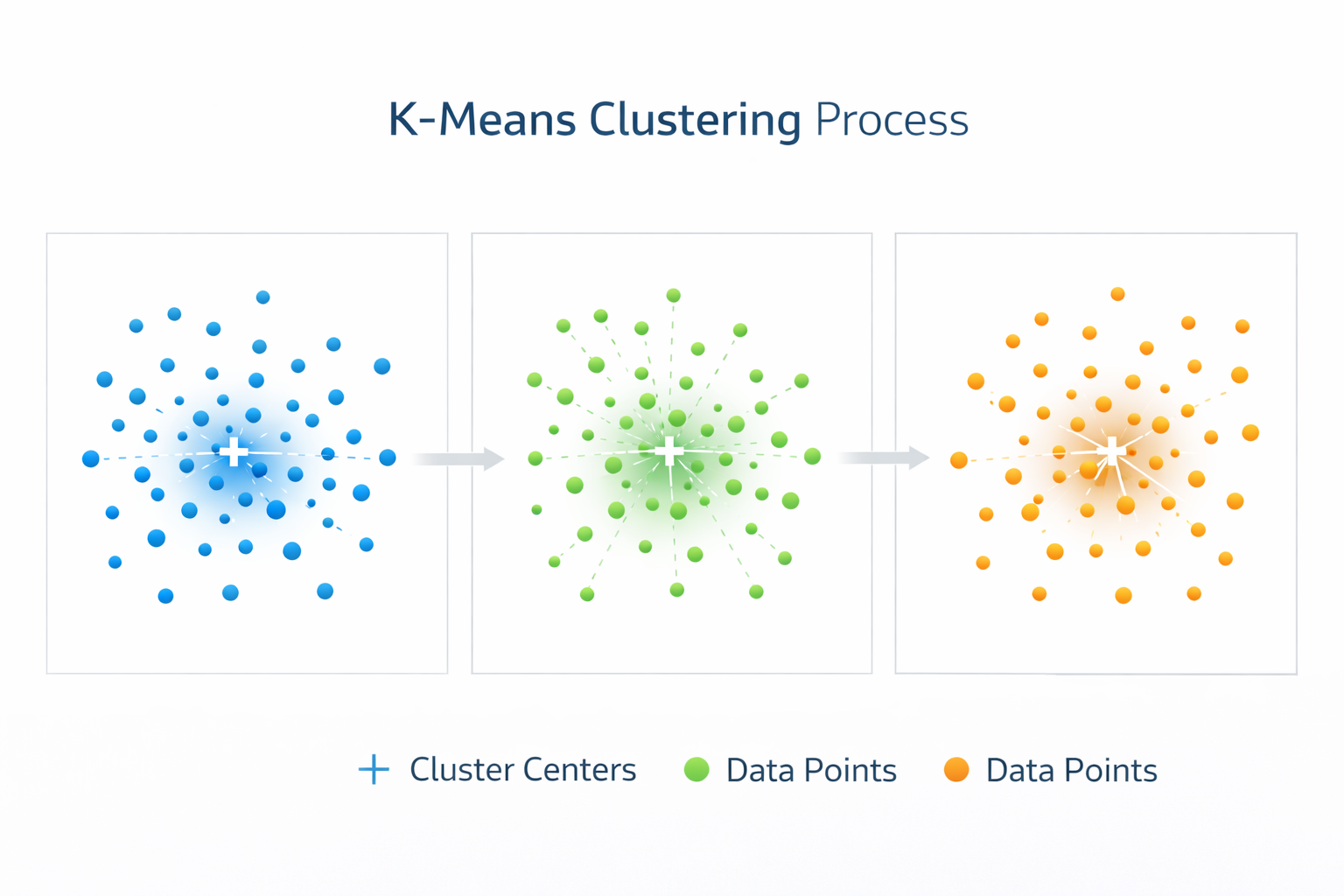
One of the most widely used clustering algorithms.
K-means divides data into a predefined number (K) of clusters by assigning points to the nearest cluster center.
Common use cases:
- Customer segmentation
- Market analysis
- Image compression
- Behavioral grouping
While efficient and simple, K-means requires choosing the number of clusters in advance.
Hierarchical Clustering
Builds a tree-like structure of clusters, known as a dendrogram.
It does not require specifying the number of clusters upfront and helps visualize data relationships.
Useful for:
- Biological classification
- Social network analysis
- Document grouping
DBSCAN (Density-Based Clustering)
Groups data points based on density rather than distance from a center.
Effective for:
- Detecting irregular cluster shapes
- Identifying outliers
- Fraud detection
DBSCAN is powerful when clusters are not evenly distributed.
Principal Component Analysis (PCA)
A dimensionality reduction technique.
PCA transforms complex datasets into fewer components while preserving variance.
Common uses:
- Data visualization
- Noise reduction
- Feature compression
- Preprocessing before supervised learning
PCA is often used as a preprocessing step before training supervised models.
Techniques such as Principal Component Analysis (PCA) help reduce dimensionality and visualize complex datasets.
Research from MIT CSAIL highlights how dimensionality reduction techniques are essential for analyzing high-dimensional data efficiently.
Autoencoders
Neural network-based unsupervised models.
They compress data into lower-dimensional representations and then reconstruct it.
Common applications:
- Anomaly detection
- Representation learning
- Image denoising
- Feature extraction
Autoencoders are widely used in deep learning systems trained on large unlabeled datasets.
👉 Related: Deep Learning 101
Real-World Examples of Unsupervised Learning

Unsupervised learning powers many modern systems.
✔ Customer Segmentation
Businesses group customers based on behavior to personalize marketing campaigns and optimize pricing strategies.
✔ Recommendation Systems
Platforms like Netflix and Spotify cluster users with similar preferences to suggest relevant content.
✔ Fraud & Anomaly Detection
Banks identify unusual transactions by detecting patterns that deviate from normal behavioral clusters.
✔ Genomics & Medical Research
Researchers cluster gene expressions to discover patterns linked to diseases.
✔ Image & Pattern Recognition
Large image datasets can be grouped automatically by similarity, enabling better organization and tagging.
Unsupervised learning often works behind the scenes to structure raw data before further modeling.
Unsupervised vs Supervised Learning
Many beginners confuse the two approaches.
| Feature | Supervised Learning | Unsupervised Learning |
| Data Required | Labeled | Unlabeled |
| Main Goal | Predict outcomes | Discover patterns |
| Example | Spam detection | Customer segmentation |
| Evaluation | Accuracy metrics | Cluster validation metrics |
| Typical Algorithms | Logistic regression, SVM | K-means, PCA |
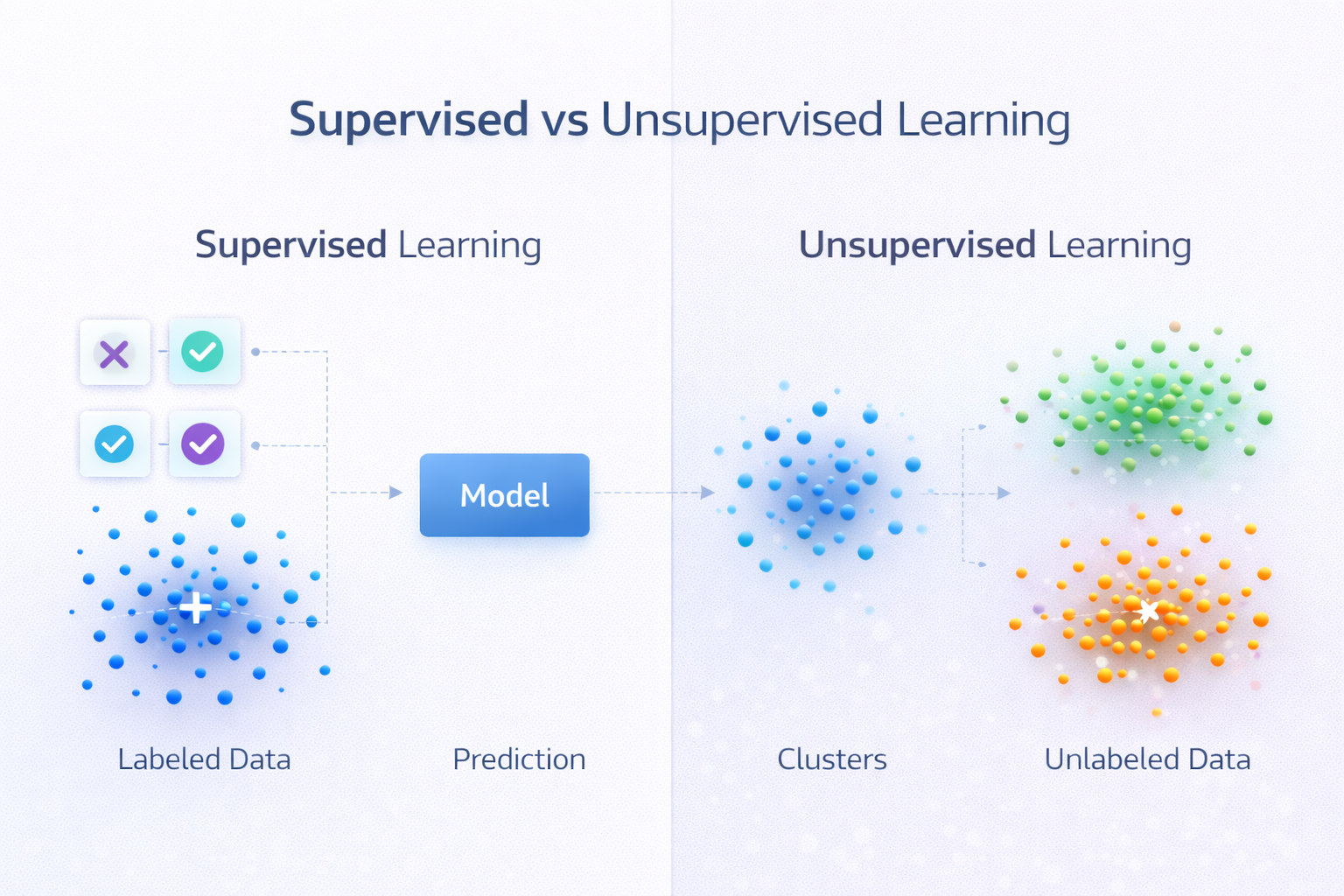
Supervised learning focuses on prediction.
Unsupervised learning focuses on pattern discovery.
In real-world artificial intelligence systems, both approaches are often combined.
👉 Related: Machine Learning Explained
Advantages of Unsupervised Learning
Unsupervised learning offers several benefits:
- No need for labeled data
- Useful for exploratory analysis
- Identifies hidden patterns
- Reduces data complexity
- Detects anomalies
- Helps preprocess data before supervised modeling
It is especially powerful when dealing with large volumes of raw, unlabeled information.
Limitations of Unsupervised Learning
Despite its usefulness, unsupervised learning has challenges:
- Harder to evaluate performance
- Clusters may not have clear meaning
- Results can be subjective
- Sensitive to parameter selection
- Interpretation may require domain expertise
Because there are no correct labels, validating outcomes can be complex.
When Should You Use Unsupervised Learning?
Unsupervised learning is ideal when:
- You lack labeled data
- You want to explore hidden structures
- You need customer segmentation
- You want anomaly detection
- You want dimensionality reduction before modeling
It is best suited for discovery and exploratory data analysis rather than direct prediction.
The Future of Unsupervised Learning

As datasets grow larger and more complex, unsupervised learning is becoming increasingly important in artificial intelligence.
Modern AI systems often begin with large-scale unsupervised pretraining before being fine-tuned with labeled data. Foundation models and large language models are frequently trained on massive volumes of unlabeled information.
Emerging trends include:
Self-Supervised Learning
Models generate their own labels from raw data.
Foundation Models
Large-scale models trained on internet-scale unlabeled datasets.
Data-Centric AI
Improving data structure and quality rather than only increasing model complexity.
Cross-Modal Learning
Discovering relationships between images, text, and audio without explicit labels.
As AI systems become more autonomous, unsupervised learning will remain central to how machines understand and structure raw information.
FAQ: Unsupervised Learning Explained
Unsupervised learning is a type of machine learning where models analyze unlabeled data and discover hidden patterns or groupings without predefined answers.
What are examples of unsupervised learning?
Examples include customer segmentation, recommendation systems, anomaly detection, and clustering gene data.
Clustering is a method that groups similar data points together based on shared characteristics.
What is dimensionality reduction?
Dimensionality reduction simplifies complex datasets by reducing the number of variables while preserving important information.
How is unsupervised learning different from supervised learning?
Supervised learning predicts outcomes using labeled data, while unsupervised learning discovers patterns without labels.
Conclusion
Unsupervised learning plays a crucial role in modern machine learning by uncovering hidden structures within data. While it does not make direct predictions like supervised learning, it provides essential insights that help organizations understand complex datasets.
As artificial intelligence continues evolving, unsupervised learning will remain foundational for data discovery, pattern recognition, and large-scale AI systems.
To continue building your AI foundation:
{
“@context”: “https://schema.org”,
“@type”: “FAQPage”,
“mainEntity”: [
{
“@type”: “Question”,
“name”: “What is unsupervised learning in simple terms?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Unsupervised learning is a type of machine learning where models analyze unlabeled data and discover hidden patterns or groupings without predefined answers.”
}
},
{
“@type”: “Question”,
“name”: “What are examples of unsupervised learning?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Examples include customer segmentation, recommendation systems, anomaly detection, and clustering gene data.”
}
},
{
“@type”: “Question”,
“name”: “What is clustering in unsupervised learning?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Clustering is a method that groups similar data points together based on shared characteristics or similarity.”
}
},
{
“@type”: “Question”,
“name”: “What is dimensionality reduction?”,
“acceptedAnswer”: {
“@type”: “Answer”,
“text”: “Dimensionality reduction simplifies complex datasets by reducing the number of variables while preserving important information.”
}
}
]
}
{
“@context”: “https://schema.org”,
“@type”: “Article”,
“headline”: “Unsupervised Learning Explained: Clustering, Pattern Discovery & Real Examples”,
“description”: “Unsupervised learning explained in simple terms. Learn how clustering and dimensionality reduction work, real examples, and key algorithms like K-means and PCA.”,
“author”: {
“@type”: “Organization”,
“name”: “All For The AI”
},
“publisher”: {
“@type”: “Organization”,
“name”: “All For The AI”
},
“mainEntityOfPage”: {
“@type”: “WebPage”,
“@id”: “https://allfortheai.com/unsupervised-learning-explained/”
}
}