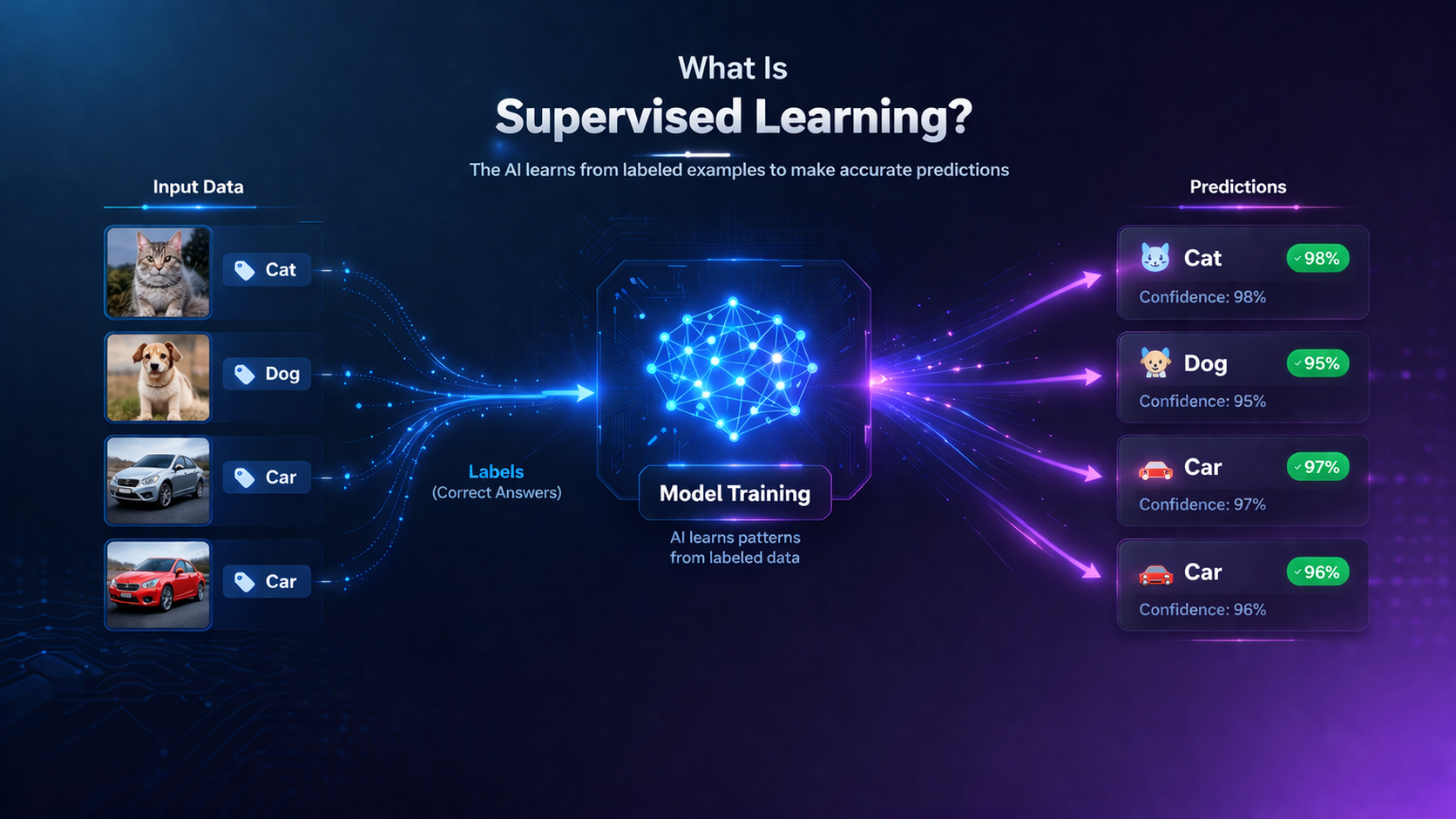
What Is Supervised Learning?
Supervised learning is one of the most important and widely used approaches in machine learning. It teaches computers to learn by example—just like a student learning from a teacher.
In supervised learning, the model is trained using a dataset that already contains the correct answers. These answers are called labels.
Supervised learning is a type of machine learning where an algorithm learns from labeled data, meaning each input comes with a correct output. The model uses this data to learn patterns and make accurate predictions on new, unseen data.
Simple Example
Imagine you want to teach a computer to recognize emails as spam or not spam:
- You give it thousands of emails
- Each email is labeled as “spam” or “not spam”
- The model learns patterns from these examples
- It can then classify new emails correctly
This learning process is called supervised learning because the model is guided with correct answers.
👉 For a broader understanding, see Machine Learning Explained and Artificial Intelligence Explained.
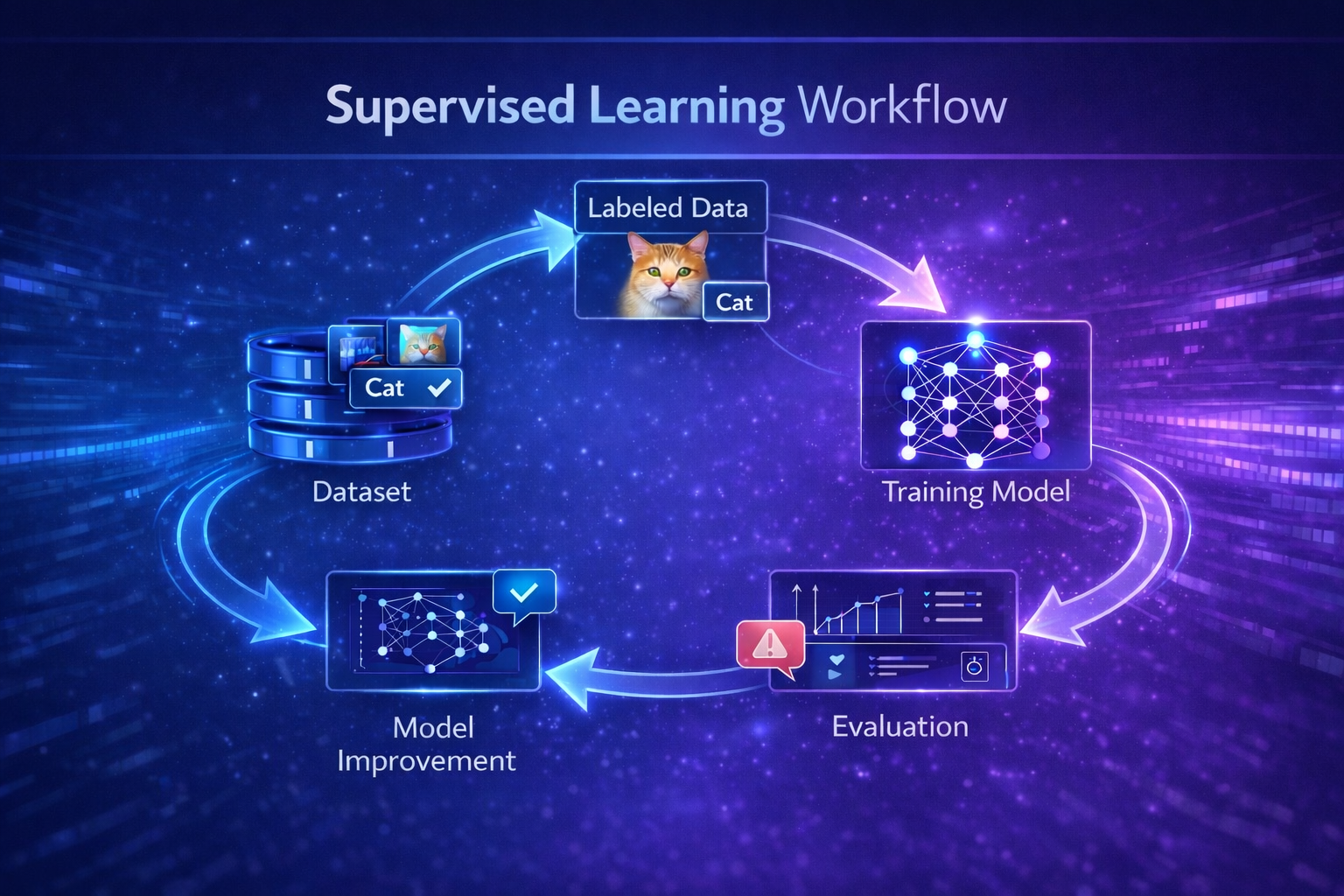
How Supervised Learning Works (Step-by-Step)

Supervised learning follows a clear process. Let’s break it down into simple steps:
Step 1: Collect Labeled Data
The first step is gathering data where:
- Inputs (features) are known
- Correct outputs (labels) are provided
Example:
| Input (Feature) | Output (Label) |
| House size | Price |
| Email text | Spam / Not spam |
| Image | Cat / Dog |
Step 2: Split Data (Training vs Testing)
The dataset is usually split into:
- Training data (used to teach the model)
- Testing data (used to evaluate performance)
👉 Learn more in Training vs Testing Data.
Step 3: Train the Model
The algorithm studies the training data and tries to find patterns.
For example:
- Bigger houses → higher prices
- Certain words → spam emails
Step 4: Make Predictions
Once trained, the model can:
- Predict outputs for new data
- Generalize beyond what it has seen
Step 5: Evaluate Performance
The model’s accuracy is tested using unseen data.
If performance is poor:
- The model may need more data
- Or better tuning
👉 Learn more: Overfitting vs Underfitting
Key Concepts Beginners Must Understand
To truly understand supervised learning, you need to know these core ideas:
1. Features and Labels
- Features = input data (e.g., size, color, words)
- Labels = correct output (e.g., price, category)
2. Training Data
The data used to teach the model.
3. Model
The algorithm that learns patterns (e.g., decision tree, regression model)
4. Prediction
The output the model generates for new inputs.
5. Error (Loss)
The difference between:
- predicted output
- actual output
The goal is to minimize this error.
6. Generalization
The model’s ability to perform well on new, unseen data.
Types of Supervised Learning
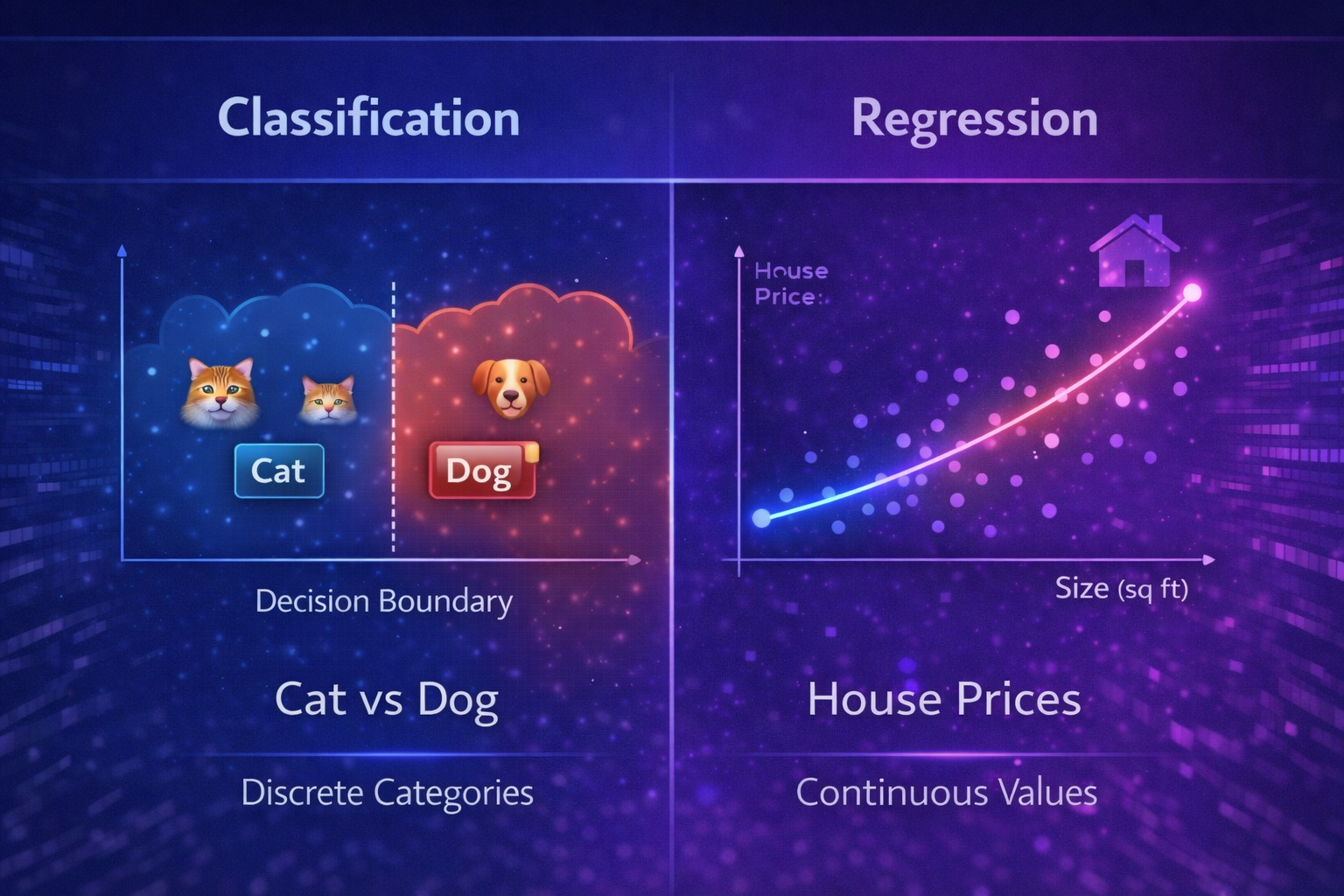
Supervised learning is mainly divided into two categories:
1. Classification
Classification predicts categories or labels.
Examples:
- Spam vs not spam
- Fraud vs legitimate transaction
- Disease vs no disease
2. Regression
Regression predicts continuous values.
Examples:
- House price prediction
- Stock market trends
- Temperature forecasting
Comparison Table
| Type | Output | Example |
| Classification | Categories | Email spam detection |
| Regression | Numbers | House price prediction |
Real-World Applications of Supervised Learning

Supervised learning powers many technologies you use every day.
1. Email Spam Detection
- Classifies emails as spam or safe
- Used by Gmail and Outlook
2. Image Recognition
- Identifies objects in photos
- Used in social media and security systems
👉 Learn more: Computer Vision Explained
3. Medical Diagnosis
- Predicts diseases based on patient data
- Helps doctors make faster decisions
4. Credit Scoring
- Determines if someone is likely to repay a loan
- Used by banks and financial institutions
5. Voice Assistants
- Recognizes speech and intent
- Used in Alexa, Siri, and Google Assistant
6. Recommendation Systems
- Suggests movies, products, or music
- Used by Netflix, Amazon, Spotify
Advantages of Supervised Learning
1. High Accuracy (With Good Data)
Because the model learns from labeled examples, it can achieve high accuracy.
2. Clear Learning Process
The training process is structured and easier to understand.
3. Predictable Outcomes
Results are easier to evaluate because correct answers are known.
4. Wide Range of Applications
From healthcare to finance, supervised learning is used everywhere.
Limitations of Supervised Learning
1. Requires Labeled Data
Labeling data is:
- Time-consuming
- Expensive
2. Limited to Known Patterns
The model can only learn from what it has seen.
3. Risk of Overfitting
If the model memorizes data instead of learning patterns, performance suffers.
👉 Learn more in Overfitting vs Underfitting
4. Data Bias Issues
If training data is biased:
- The model will also be biased
Supervised Learning vs Other Machine Learning Types
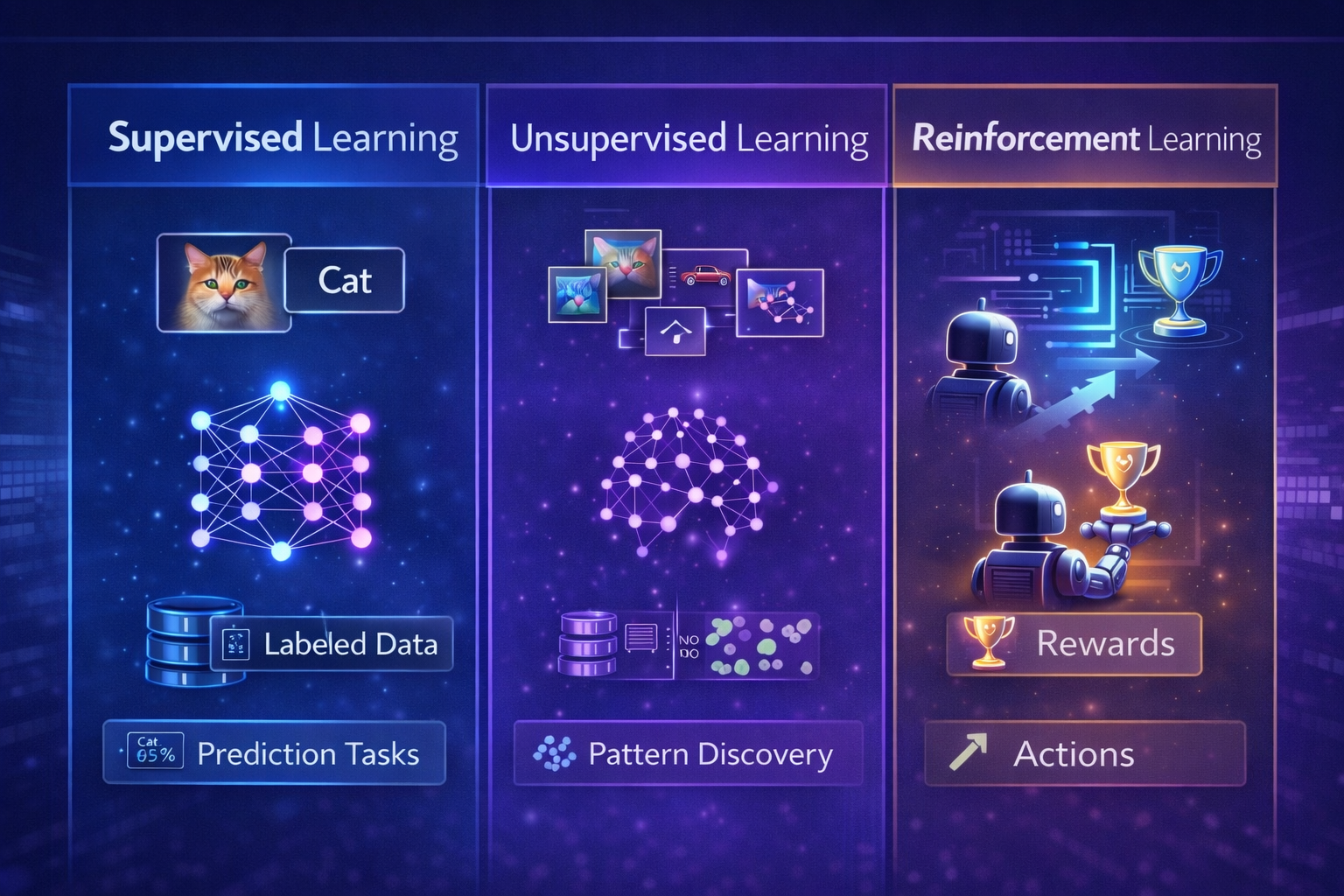
Understanding how supervised learning compares to other approaches is important.
Comparison Table
| Learning Type | Data Type | Goal |
| Supervised Learning | Labeled | Predict outputs |
| Unsupervised Learning | Unlabeled | Find patterns |
| Reinforcement Learning | Feedback-based | Learn through rewards |
Supervised vs Unsupervised Learning
- Supervised → learns with correct answers
- Unsupervised → discovers patterns on its own
👉 See: Unsupervised Learning Explained
Supervised vs Reinforcement Learning
- Supervised → learns from labeled data
- Reinforcement → learns through trial and error
👉 See: Reinforcement Learning Explained
How Supervised Learning Connects to Deep Learning
Supervised learning is the foundation of many deep learning systems.
- Neural networks often use supervised learning
- Large datasets improve performance
- Used in image recognition, NLP, and AI systems
👉 Related topics:
Future of Supervised Learning

Supervised learning continues to evolve as AI advances.
1. Automation of Data Labeling
New tools are reducing the need for manual labeling.
2. Hybrid Learning Systems
Combining supervised + unsupervised learning for better results.
3. Larger Datasets and Models
More data → better performance → smarter AI systems
4. Real-Time Learning
Models that continuously update with new data.
FAQ: Supervised Learning Explained
1. What is supervised learning in simple terms?
It is a method where a model learns from examples with correct answers.
2. Why is it called supervised learning?
Because the model is guided using labeled data
3. What are examples of supervised learning?
Spam detection, image classification, and price prediction.
4. What is the difference between classification and regression?
- Classification → categories
- Regression → numerical values
5. Does supervised learning require a lot of data?
Yes, especially labeled data.
6. What is labeled data?
Data that includes both input and correct output.
7. Can supervised learning be used in deep learning?
Yes, most deep learning models use supervised learning.
8. What are common algorithms used?
- Linear regression
- Decision trees
- Support vector machines
- Neural networks
9. What is overfitting?
When a model memorizes training data instead of learning patterns.
10. Is supervised learning still important today?
Yes, it is one of the most widely used AI techniques.
Conclusion
Supervised learning is a foundational concept in machine learning and artificial intelligence. By learning from labeled data, it enables systems to make accurate predictions and power real-world applications like spam detection, recommendation systems, and medical diagnostics.
As AI continues to evolve, supervised learning remains a core building block for more advanced technologies, including deep learning and large-scale AI systems.
Recommended Next Articles
To continue your learning journey on AllForTheAI.com:
- Artificial Intelligence Explained
- Machine Learning Explained
- Types of Machine Learning
- Unsupervised Learning Explained
- Reinforcement Learning Explained
- Neural Networks Explained
- Deep Learning Explained