Introduction to Overfitting vs Underfitting
Overfitting vs Underfitting refers to two common problems in machine learning where a model either learns too much from training data (overfitting) or too little (underfitting). Overfitting leads to poor performance on new data, while underfitting results in inaccurate predictions even on training data.
Overfitting and underfitting are important concepts in machine learning and artificial intelligence because they directly affect prediction accuracy, model performance, and evaluation reliability.
Most machine learning models don’t fail because of bad data…
👉 They fail because they either learn too much or too little.
This is where overfitting vs underfitting comes in.
- Overfitting → memorizing the data
- Underfitting → not learning enough
Understanding this balance is essential in Machine Learning and is a core concept in building reliable AI systems.
What Is Overfitting?
Simple Definition
Overfitting happens when a model learns the training data too well, including noise and random patterns.
Instead of understanding patterns, it memorizes them.
Real-World Analogy
Imagine studying for a test by memorizing answers instead of understanding concepts:
- You score 100% on practice questions
- But fail when the exam changes slightly
That’s overfitting.
Key Characteristics of Overfitting
- Very high training accuracy
- Poor test accuracy
- Model is overly complex
- Sensitive to small changes in data
What Is Underfitting?
Simple Definition
Underfitting occurs when a model is too simple to capture patterns in the data.
It fails to learn meaningful relationships.
Real-World Analogy
Imagine barely studying for a test:
- You don’t understand the material
- You perform poorly everywhere
That’s underfitting.
Key Characteristics of Underfitting
- Low training accuracy
- Low test accuracy
- Model is too simple
- Misses important patterns
Overfitting vs Underfitting (Side-by-Side Comparison)
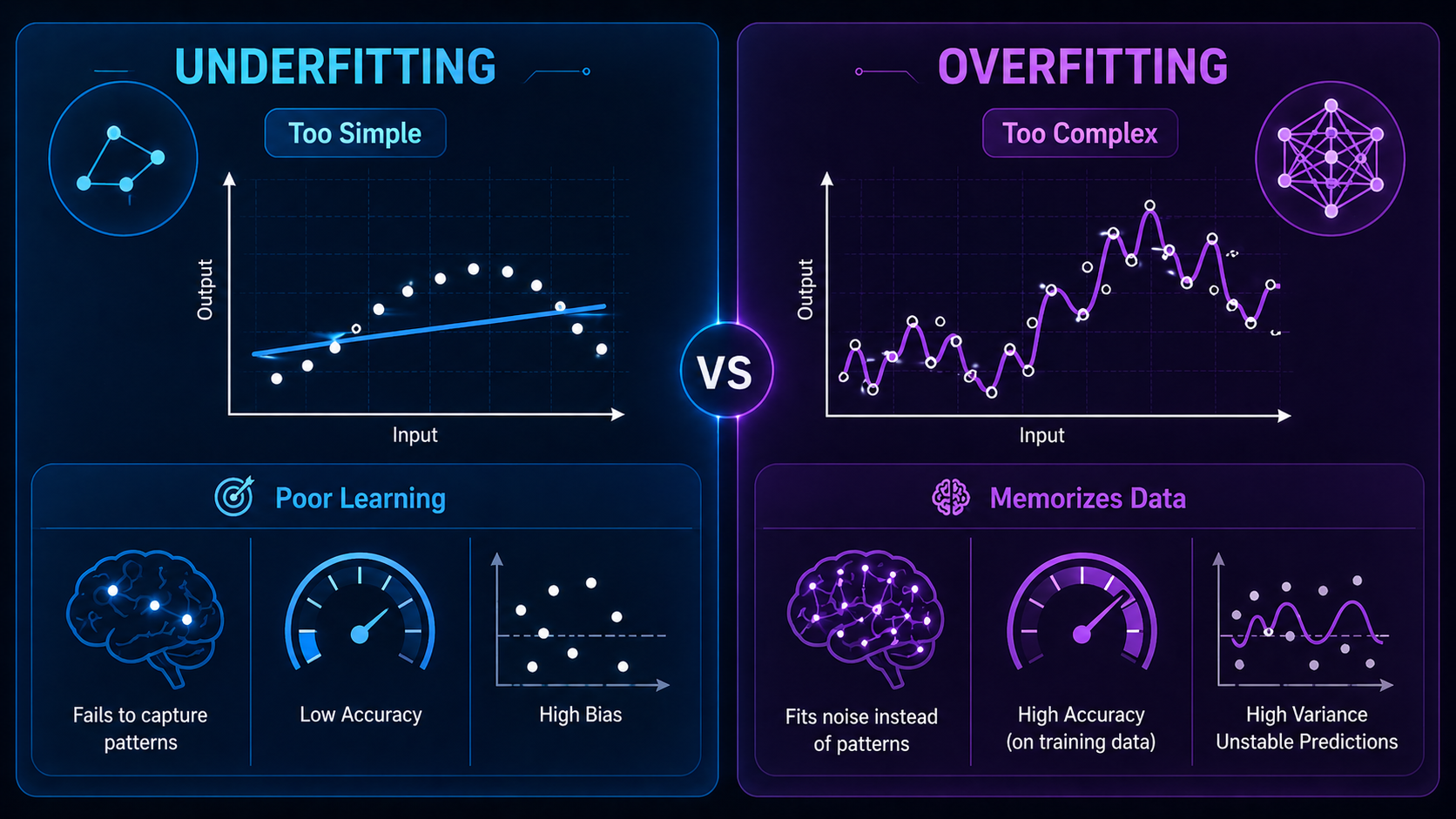
| Feature | Overfitting | Underfitting |
| Learning | Too much | Too little |
| Training accuracy | Very high | Low |
| Test accuracy | Low | Low |
| Model complexity | High | Low |
| Generalization | Poor | Poor |
| Main issue | Memorization | Lack of learning |
What Is the Ideal Model Fit?
The goal in machine learning is not to avoid learning…
👉 It’s to learn just enough.
A well-balanced model:
- Captures real patterns
- Ignores noise
- Performs well on new data
Think of it as:
👉 Understanding concepts instead of memorizing answers
This balance is often explained through the Bias vs Variance Tradeoff.
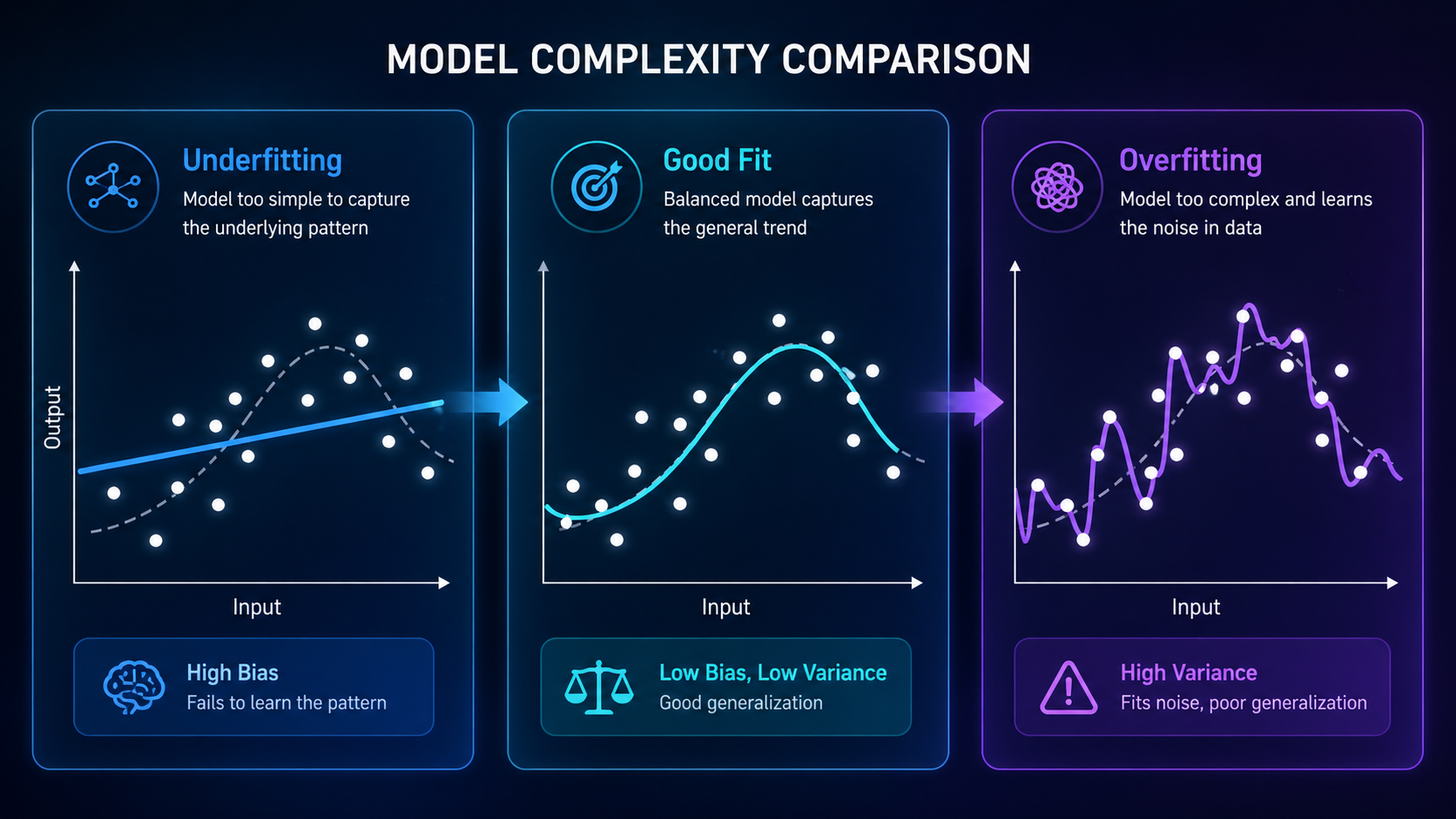
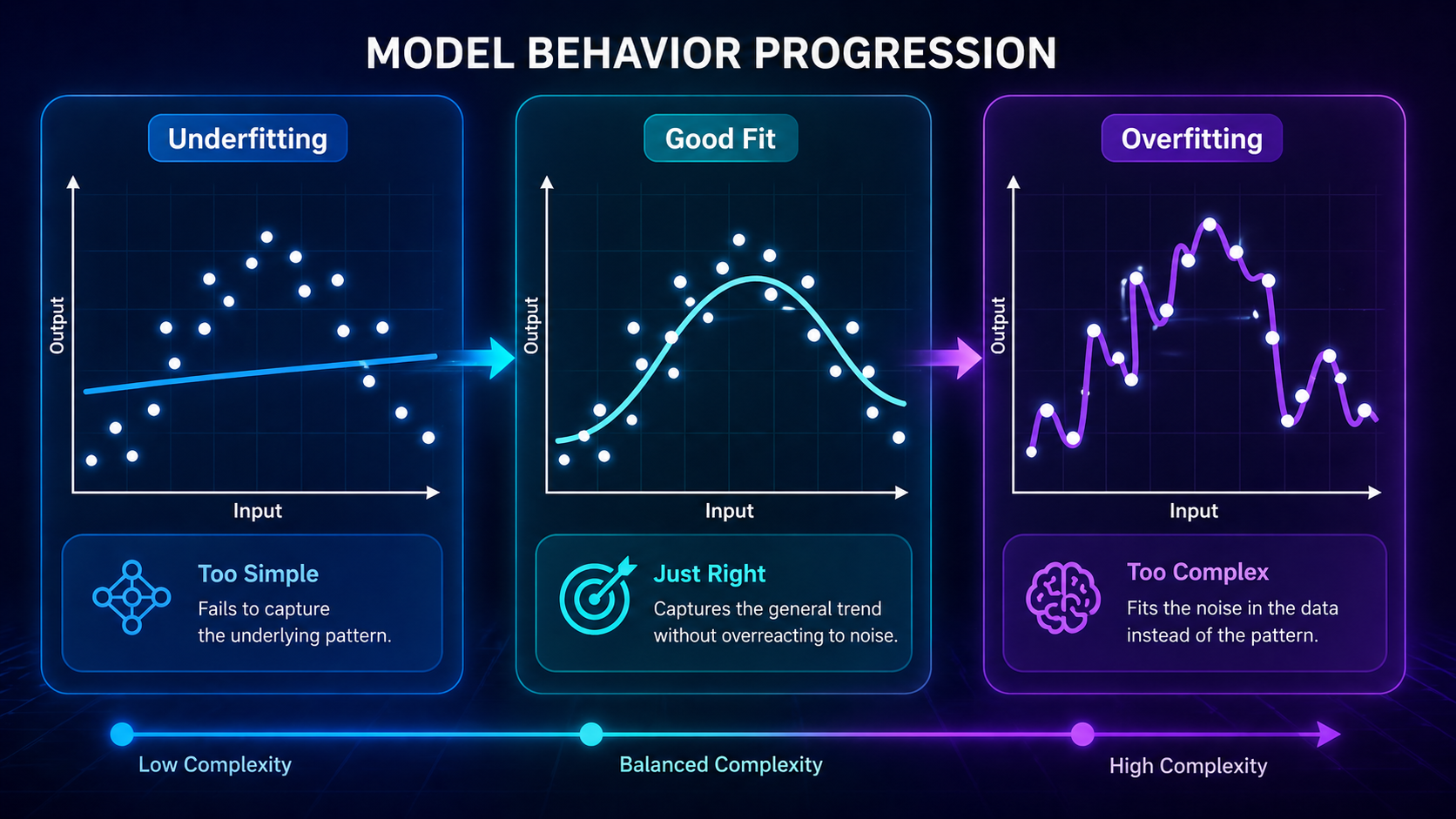
Visualizing Overfitting vs Underfitting
A simple way to understand this concept is through curves:
- Underfitting → a straight line that misses the pattern
- Good fit → a smooth curve that captures trends
- Overfitting → a wiggly curve that follows every data point
👉 This is why visual diagrams are powerful for learning this concept.
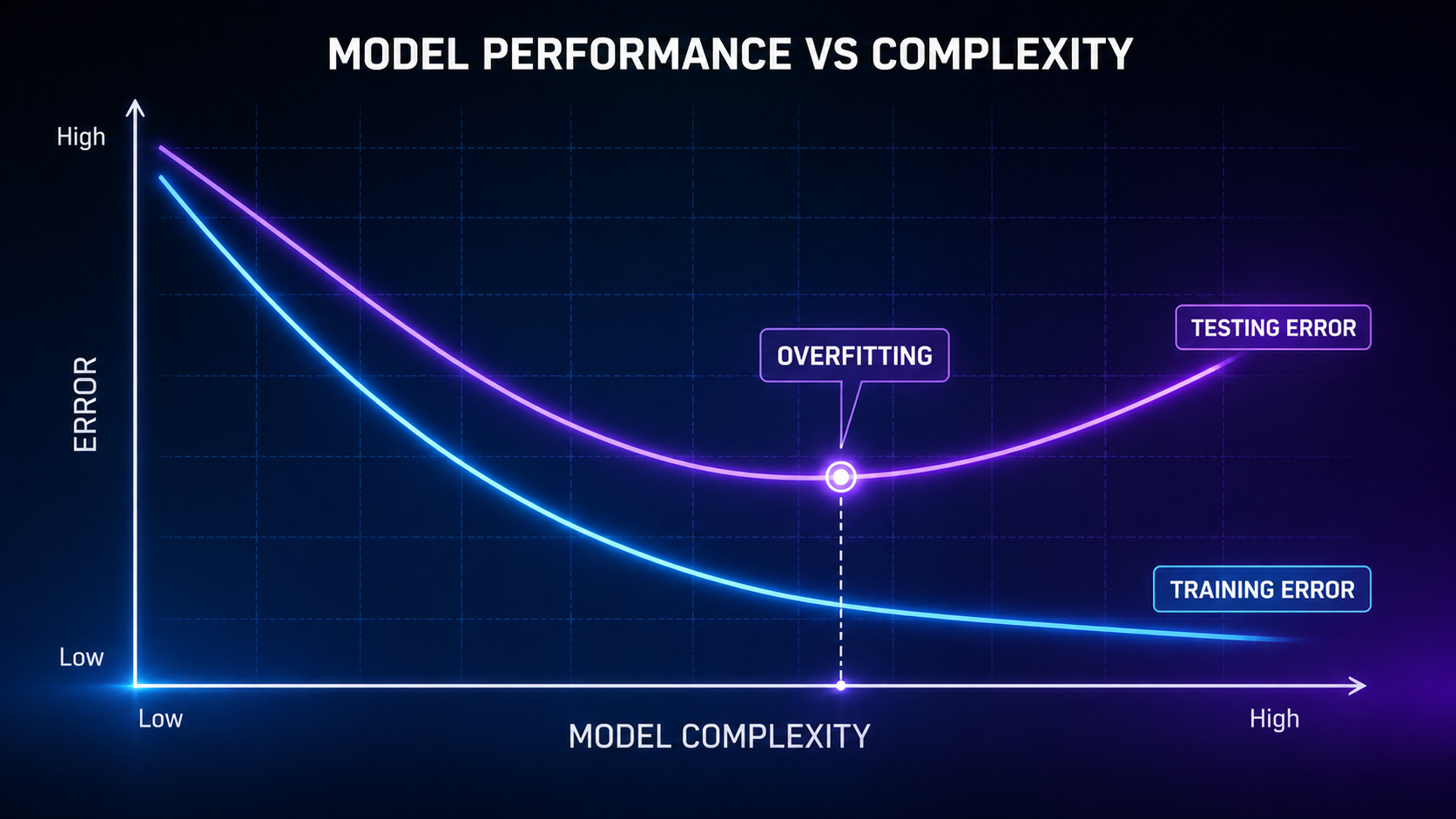
How Overfitting vs Underfitting Happens (Step-by-Step)
Step 1: Training the Model
The model learns from training data.
- In Supervised Learning Explained, it learns from labeled data
- In Unsupervised Learning Explained, it finds hidden patterns
Step 2: Evaluating Performance
The model is tested on new data:
- Big gap between training and testing → overfitting
- Poor performance everywhere → underfitting
Step 3: Adjusting the Model
Engineers adjust:
- Model complexity
- Features
- Training time
- Hyperparameters
This process is part of Model Evaluation Metrics Explained.
Why Overfitting vs Underfitting Matters
These issues directly impact real-world AI systems:
- Self-driving cars misreading objects
- Medical AI making incorrect diagnoses
- Recommendation systems giving poor suggestions
According to IBM, overfitting is one of the most common reasons machine learning models fail in production.
Key Concepts Beginners Must Understand
1. Bias vs Variance Tradeoff
- High bias → underfitting
- High variance → overfitting
👉 Learn more in Bias vs Variance Tradeoff
2. Training vs Testing Data
- Training data → learning
- Testing data → evaluation
👉 Covered in Training vs Testing Data
3. Generalization
A good model should:
👉 Perform well on unseen data
4. Model Complexity
- Simple models → underfit
- Complex models → overfit
Types of Overfitting
1. High Variance Overfitting
The model reacts too strongly to small changes in data.
2. Noise Overfitting
The model learns random noise instead of meaningful patterns.
3. Feature Overfitting
Too many irrelevant features confuse the model.
Types of Underfitting
1. Simple Model Underfitting
The model lacks the capacity to learn.
2. Insufficient Training
The model hasn’t trained long enough to learn patterns.
3. Poor Feature Representation
Important information is missing from the data.
Balancing model complexity, bias, and evaluation techniques is essential for improving machine learning performance and reducing prediction errors.
How to Fix Overfitting
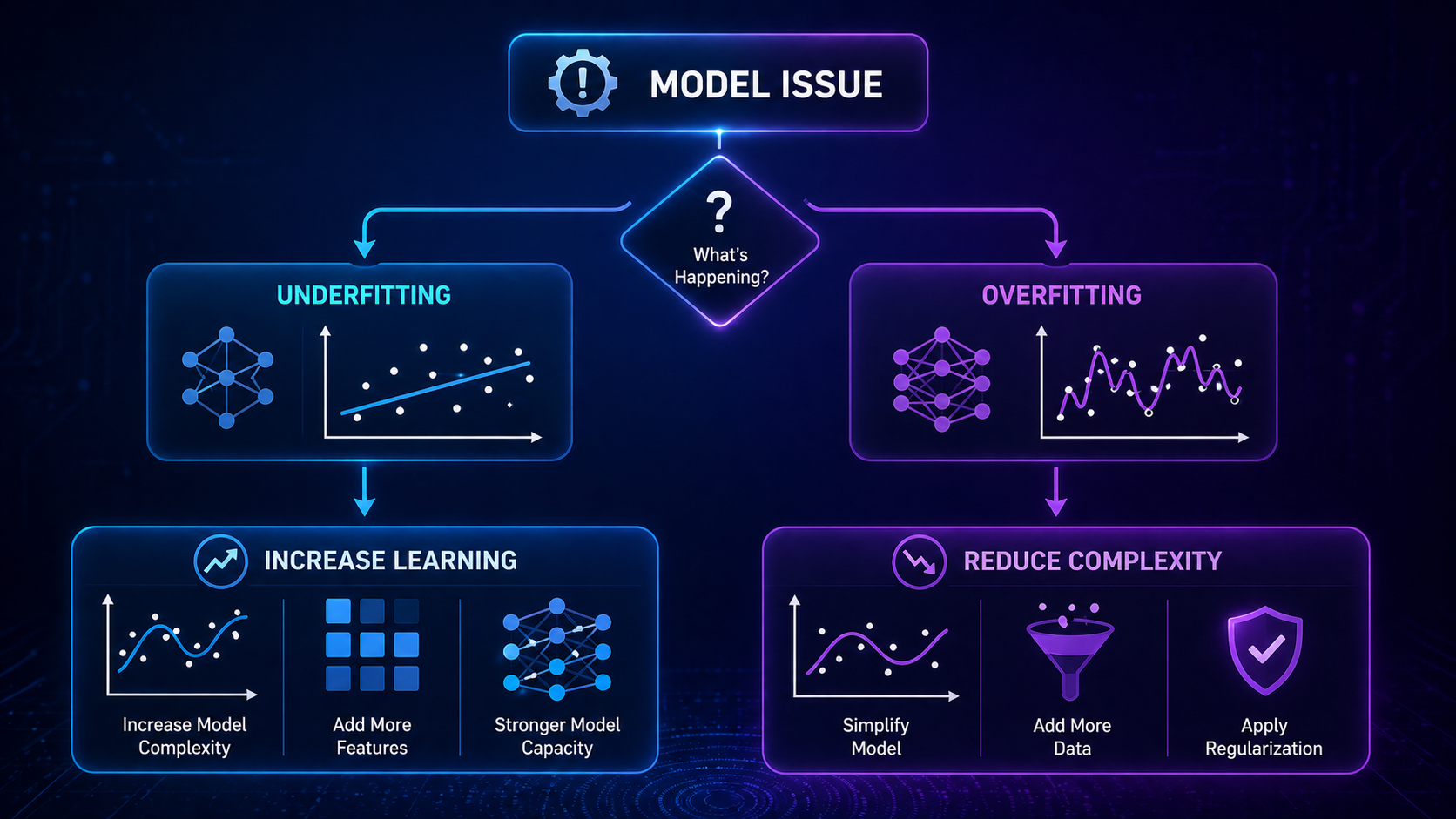
Common Techniques
- Use more training data → reduces memorization
- Regularization → adds a penalty for complexity to prevent overfitting
- Reduce model complexity → simpler models generalize better
- Dropout (in neural networks) → randomly removes connections to prevent memorization
- Cross-validation → ensures consistent performance across different data splits
Example
In Neural Networks Explained, dropout helps models avoid memorizing training data.
How to Fix Underfitting
Common Techniques
- Increase model complexity → allows learning more patterns
- Train longer → gives the model more time to learn
- Add better features → improves data representation
- Reduce regularization → allows the model to learn more freely
Example
A linear model may underfit complex relationships, while a neural network can capture them more effectively.
Real-World Applications
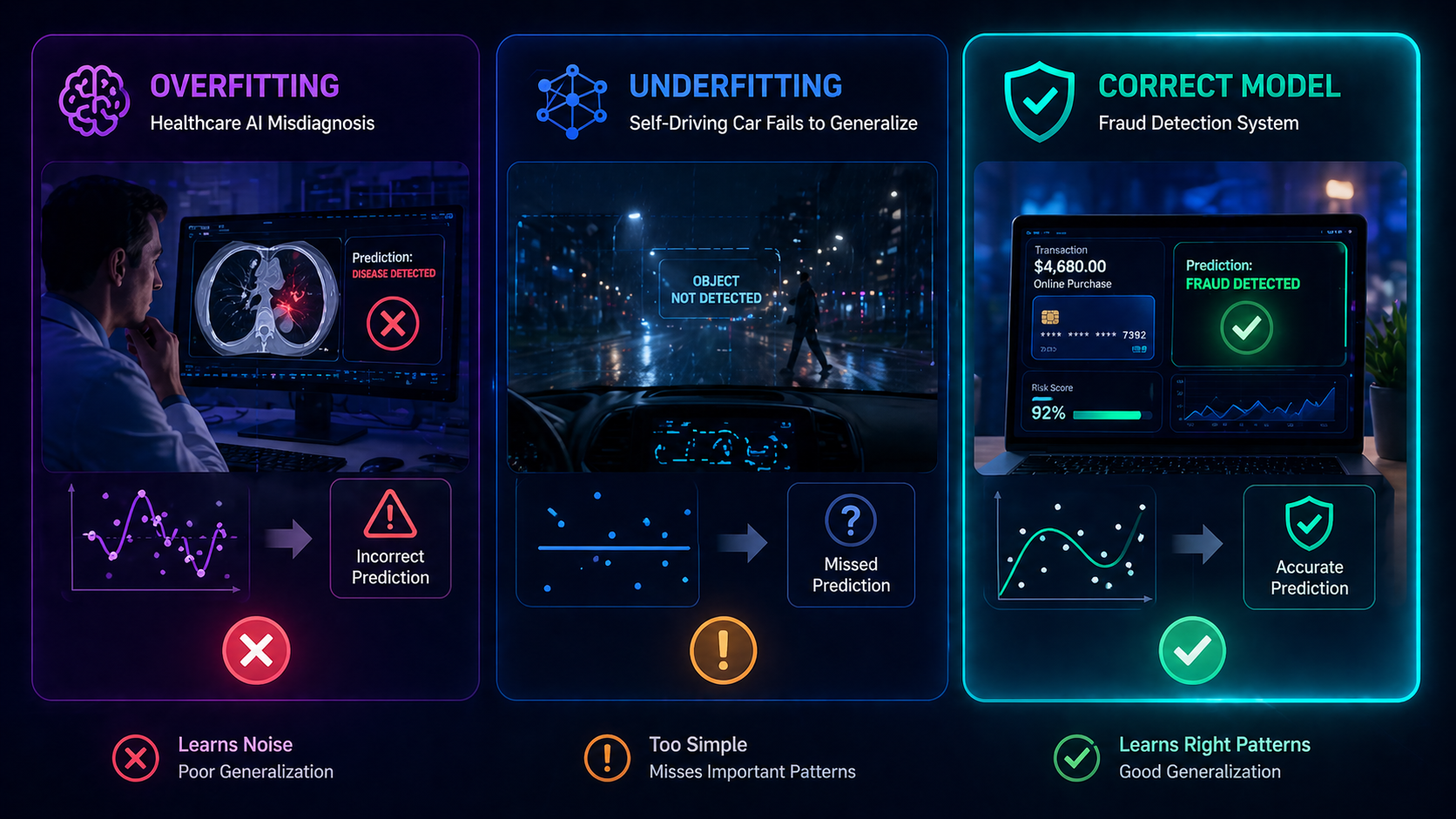
1. Healthcare AI
- Overfitting → incorrect diagnoses
- Underfitting → missed disease patterns
2. Finance
- Overfitting → unreliable predictions
- Underfitting → inaccurate forecasts
3. Recommendation Systems
- Overfitting → overly specific recommendations
- Underfitting → generic suggestions
4. Computer Vision
Used heavily in Deep Learning Explained:
- Overfitting → memorizes images
- Underfitting → fails to detect objects
Advantages and Limitations
Advantages of Understanding This Concept
- Improves model accuracy
- Builds more reliable AI systems
- Prevents costly real-world errors
Limitations
- Requires experimentation and tuning
- No universal solution
- Depends heavily on data quality
Comparison With Related Concepts
Overfitting vs Bias vs Variance
| Concept | Meaning |
| Overfitting | Too much learning |
| Underfitting | Too little learning |
| Bias | Error from incorrect assumptions |
| Variance | Error from sensitivity to data |
Overfitting vs Data Leakage
- Overfitting → model memorizes patterns
- Data leakage → model sees information it shouldn’t
Future Outlook
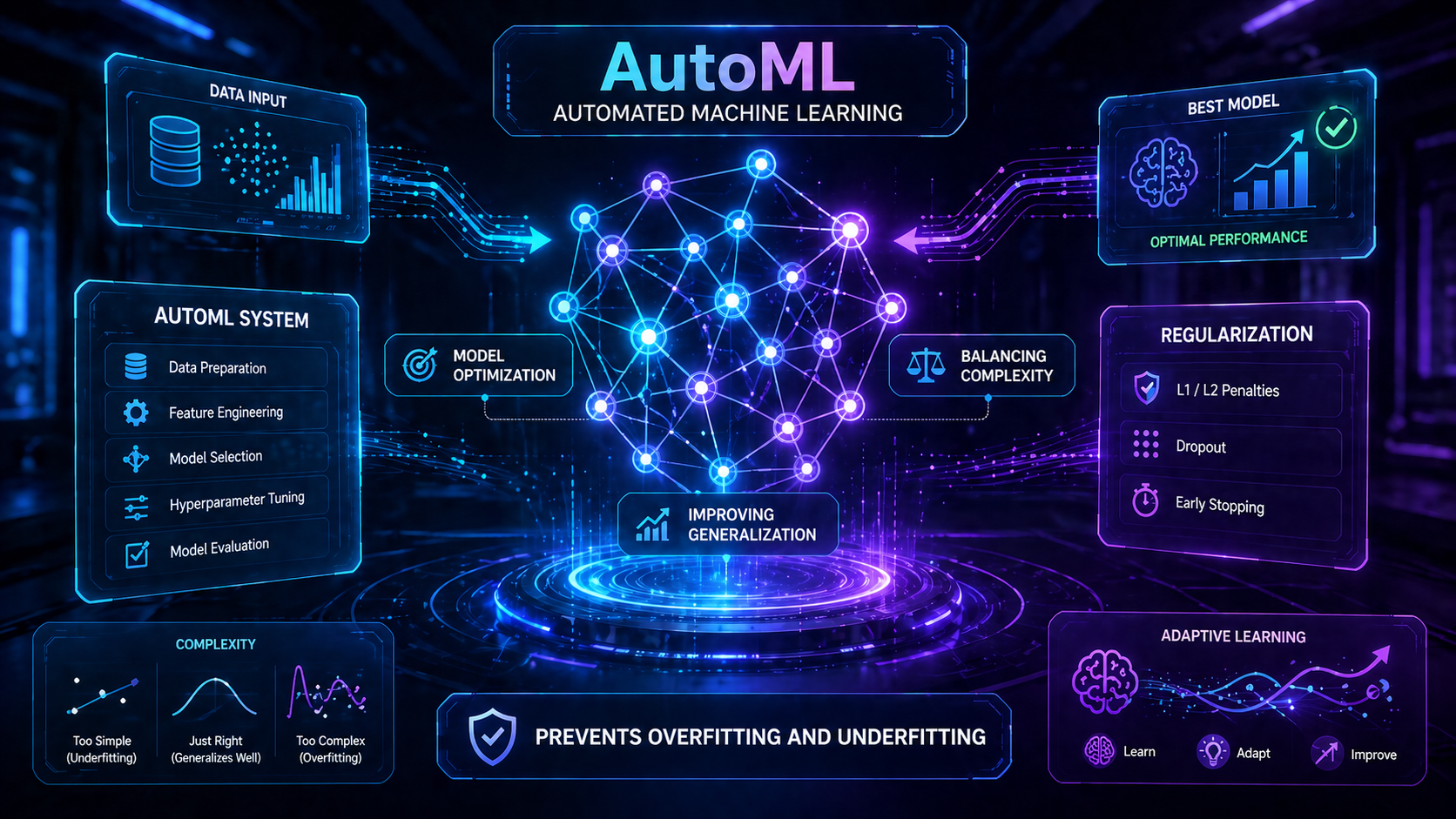
As AI continues to evolve:
- Automated ML tools will reduce overfitting risks
- Larger datasets will improve generalization
- Techniques like ensemble learning and regularization will become standard
Research from organizations like Stanford AI continues to improve how models balance learning and generalization.
FAQ: Overfitting vs Underfitting
What is the difference between overfitting and underfitting in machine learning?
Overfitting occurs when a model learns too much from training data, including noise and irrelevant details, while underfitting happens when a model learns too little and misses important patterns. Overfitting performs well on training data but poorly on new data, whereas underfitting performs poorly on both.
Why is overfitting bad in machine learning?
Overfitting is bad because the model memorizes data instead of learning general patterns. This leads to poor performance when the model is applied to real-world or unseen data.
Why does underfitting happen in machine learning?
Underfitting happens when a model is too simple, lacks sufficient features, or is not trained long enough. As a result, it cannot capture the underlying patterns in the data.
How do you detect overfitting?
You can detect overfitting by comparing training and testing performance. If the model has very high accuracy on training data but significantly lower accuracy on test data, it is likely overfitting.
What is a good model fit in machine learning?
A good model fit captures meaningful patterns in the data without learning noise. It performs consistently well on both training data and unseen data, showing strong generalization.
How do you fix overfitting in machine learning?
Overfitting can be fixed by reducing model complexity, using regularization, adding more training data, or applying techniques like dropout and cross-validation. These methods help the model generalize better.
How do you fix underfitting in machine learning?
Underfitting can be fixed by increasing model complexity, training the model longer, improving feature selection, or reducing regularization. This allows the model to better learn patterns in the data.
Is overfitting common in deep learning?
Yes, overfitting is common in deep learning because neural networks are highly complex and can easily memorize training data. Techniques like dropout and data augmentation are used to prevent this.
Can more data reduce overfitting?
Yes, increasing the amount of training data helps reduce overfitting by allowing the model to learn general patterns instead of memorizing specific examples.
Why is overfitting vs underfitting important in machine learning?
Overfitting vs underfitting is important because it determines how well a model performs in real-world scenarios. Balancing both is essential for building accurate and reliable AI systems.
What is an example of overfitting and underfitting?
An example of overfitting is a model that perfectly predicts training data but fails on new data. An example of underfitting is a model that cannot even accurately predict training data because it is too simple.
Explore More Model Optimization Guides
If you want to continue learning about overfitting, model performance, and machine learning optimization, explore these beginner-friendly guides covering datasets, evaluation metrics, neural networks, and AI training systems.
Artificial Intelligence Foundations
👉 Artificial Intelligence Explained
Data & Training
👉 What Is a Dataset in Machine Learning
👉 Data Preprocessing Explained
👉 Feature Engineering Explained
Model Evaluation & Optimization
👉 Model Evaluation Metrics Explained
👉 Accuracy vs Precision vs Recall
Neural Networks & Deep Learning
👉 Deep Learning vs Machine Learning
Conclusion
Overfitting vs Underfitting is a fundamental concept in machine learning.
To build effective models, you must:
- Avoid memorization
- Avoid oversimplification
- Find the right balance
This balance is what allows AI systems to succeed in real-world applications.