Introduction to Machine Learning
Machine learning is one of the most important technologies in modern artificial intelligence. It powers everything from Netflix recommendations to fraud detection and self-driving cars.
At its core, machine learning teaches computers to learn from experience, similar to how humans learn from past examples.
If you’re new to AI, start here:
👉 What Is Artificial Intelligence (Beginner Guide)
Machine learning is a core subset of artificial intelligence, focused specifically on learning from data rather than relying on pre-written instructions.
What Is Machine Learning?

Machine learning is a branch of artificial intelligence that allows computers to learn patterns from data and make predictions or decisions without being explicitly programmed.
Instead of following fixed rules, machine learning systems improve automatically as they process more data over time.
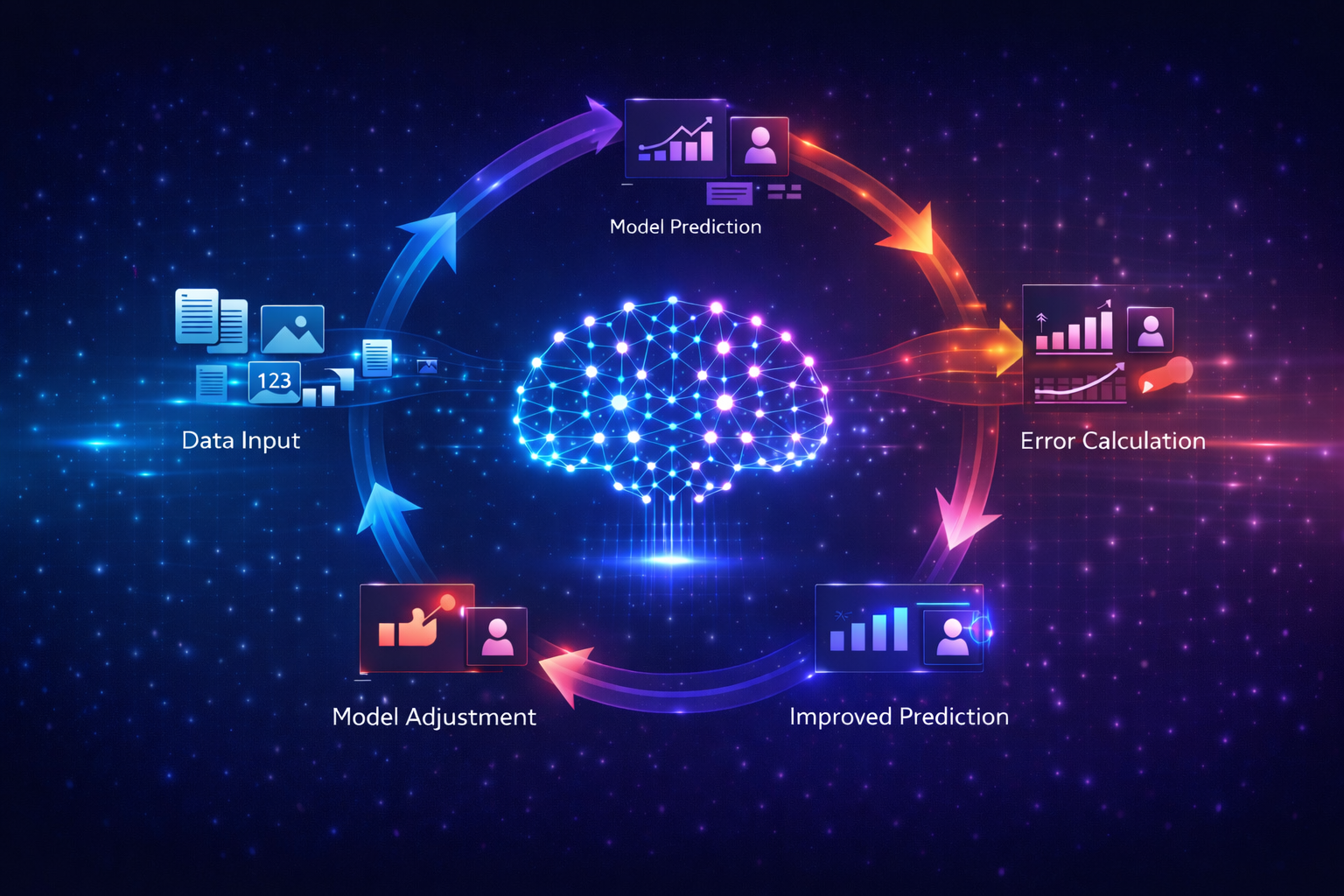
How Machine Learning Works (Step-by-Step)

Machine learning works by turning raw data into useful predictions through a structured process.
Step 1 – Data Collection
Everything starts with data.
Examples include:
- Images (photos, medical scans)
- Text (emails, reviews)
- Numbers (sales data, sensor data)
- User behavior (clicks, watch history
👉 The more high-quality data you have, the better the model can learn.
Step 2 – Data Preparation
Raw data is cleaned and organized before training.
This includes:
- Removing errors or duplicates
- Filling missing values
- Selecting useful features
Analogy:
This is like preparing ingredients before cooking a meal.
Step 3 – Training the Model
The machine learning algorithm analyzes the data and learns patterns.
It adjusts its internal parameters to reduce prediction errors.
Example:
A spam filter learns that emails with certain keywords are more likely to be spam.
Step 4 – Evaluation
The model is tested using new data to measure performance.
Common evaluation metrics:
- Accuracy
- Precision
- Recall
- F1 score
Step 5 – Prediction (Deployment)
Once trained, the model can make predictions in real-world scenarios.
Examples:
- Recommending movies
- Detecting fraud
- Recognizing faces
Simple Real-World Example of Machine Learning
Netflix Recommendation System
Let’s make this simple.
- You watch action movies
- Netflix tracks your viewing behavior
- It compares you with similar users
- It identifies patterns
- It recommends movies you’re likely to enjoy
👉 This is machine learning in action—learning from data to improve recommendations over time.
Key Concepts Beginners Must Understand
Dataset
A collection of data used to train a model.
Features
The inputs used for predictions.
Example (house price prediction):
- Size
- Location
- Number of bedrooms
Model
A system that learns patterns from data.
Training vs Testing Data
- Training data teaches the model
- Testing data evaluates performance
Overfitting vs Generalization
- Overfitting: Model memorizes data but fails on new inputs
- Generalization: Model performs well on unseen data
👉 Learn more: Overfitting vs Underfitting
Types of Machine Learning
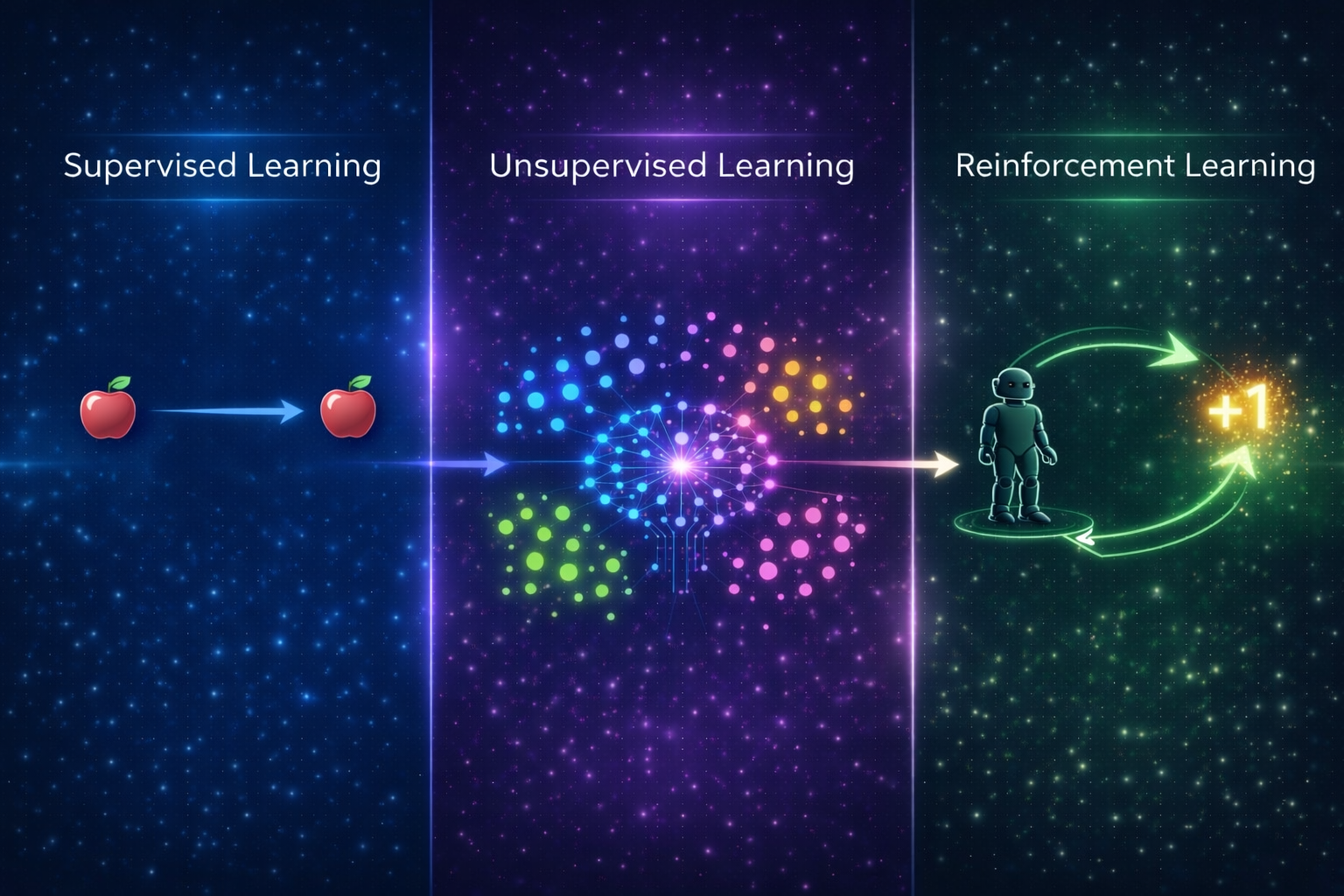
Machine learning is divided into three main categories.
Machine Learning Types Comparison
| Type | Data Type | Goal | Example |
| Supervised Learning | Labeled | Predict outcomes | Spam detection |
| Unsupervised Learning | Unlabeled | Find patterns | Customer segmentation |
| Reinforcement Learning | Reward-based | Learn actions | Self-driving cars |
1. Supervised Learning
Supervised learning uses labeled data.
Examples:
- Email classification (spam vs not spam)
- House price prediction
👉 Read more: Supervised Learning Explained
2. Unsupervised Learning
Unsupervised learning finds patterns in unlabeled data.
Examples:
- Customer segmentation
- Grouping similar products
👉 Read more: Unsupervised Learning Explained
3. Reinforcement Learning
Reinforcement learning uses rewards and penalties to learn.
Examples:
- Game-playing AI
- Robotics
👉 Read more: Reinforcement Learning Explained
Real-World Applications of Machine Learning

Machine learning is used across many industries.
Healthcare
- Disease detection
- Medical imaging analysis
- Drug discovery
Finance
- Fraud detection
- Credit scoring
- Risk analysis
Technology
- Voice assistants (Siri, Alexa)
- Search engines
- Image recognition
Marketing
- Personalized recommendations
- Customer segmentation
- Ad targeting
Transportation
- Self-driving cars
- Traffic prediction
- Route optimization
Machine Learning vs Related Concepts
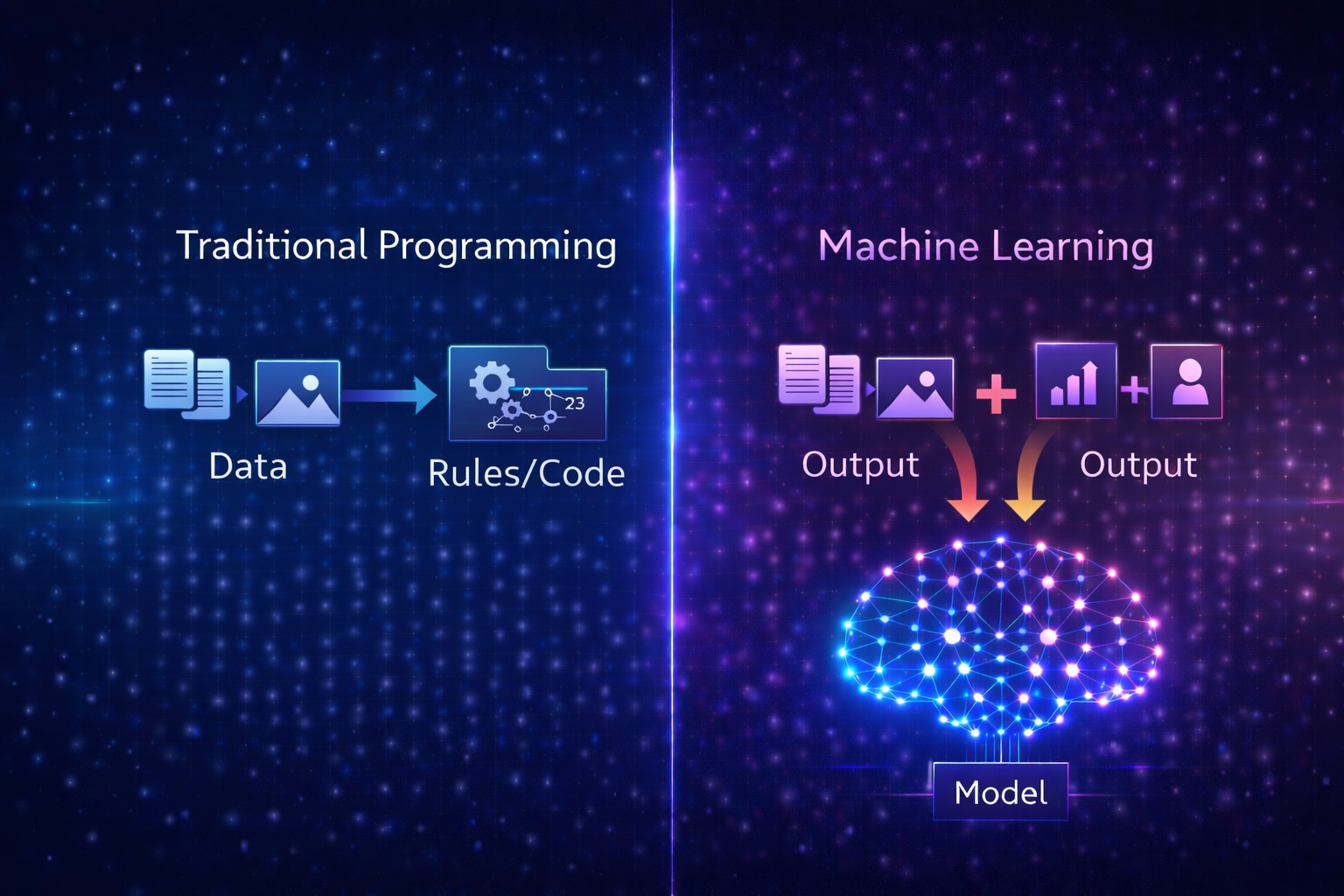
Machine Learning vs Artificial Intelligence
- Artificial Intelligence: Broad field of intelligent systems
- Machine Learning: Subset focused on learning from data
👉 What Is Artificial Intelligence (Beginner Guide)
Machine Learning vs Deep Learning
- Machine Learning: Uses many different algorithms
- Deep Learning: Uses neural networks with many layers
Machine Learning vs Neural Networks
- Machine Learning: Broad field
- Neural Networks: A specific technique within ML
Advantages of Machine Learning
- Automates complex decision-making
- Improves with more data
- Handles large-scale datasets
- Detects hidden patterns
Limitations of Machine Learning
Data Dependency
Poor data leads to poor results.
Bias
Models can inherit bias from training data.
Lack of Interpretability
Some models act like “black boxes.”
High Computational Cost
Training models requires significant computing resources.
The Future of Machine Learning

Machine learning continues to evolve rapidly.
Key trends include:
- Generative AI (creating text, images, and video)
- Self-supervised learning
- Edge AI (running models on devices)
- Automation across industries
Machine learning will play a central role in shaping future technology.
External Resources for Further Learning
FAQ — What Is Machine Learning?
What is machine learning in simple terms?
Machine learning allows computers to learn from data and improve without being explicitly programmed.
Is machine learning the same as artificial intelligence?
No. Machine learning is a subset of artificial intelligence.
What are the main types of machine learning?
Supervised, unsupervised, and reinforcement learning.
Do I need math to understand machine learning?
Not at the beginner level. You can understand the core concepts without advanced math.
Where is machine learning used?
Healthcare, finance, marketing, transportation, and more.
What is a machine learning model?
A model is a system that learns patterns from data to make predictions.
What is overfitting?
Overfitting happens when a model performs well on training data but poorly on new data.
Can machine learning improve over time?
Yes. With more data, models typically become more accurate.
What is the difference between supervised and unsupervised learning?
Supervised learning uses labeled data, while unsupervised learning finds patterns in unlabeled data.
Conclusion
Machine learning is a powerful technology that allows computers to learn from data and make intelligent decisions.
It is a core part of modern AI and is used in many industries today.
To continue learning, explore:
👉 Supervised Learning Explained
👉 Unsupervised Learning Explained
👉 Reinforcement Learning Explained
These topics will help you build a complete understanding of artificial intelligence.