

Machine Learning Explained: A Comprehensive Guide to Its Various Categories
Machine learning, a pivotal technology under the broad umbrella of artificial intelligence (AI), has transformed the way we interact with data, automate decision-making, and develop intelligent systems. This introduction provides an overview of machine learning, emphasizing its critical role in AI and introducing the various categories that constitute the field.
1. Introduction to Machine Learning: Exploring Its Impact and Categories

Understanding the Core Concepts of Machine Learning
Machine learning, a key technology within artificial intelligence (AI), has revolutionized how we handle data, automate decisions, and develop intelligent systems.
It teaches computers to learn from data and make decisions without being explicitly programmed.
This ability to extract patterns, predict outcomes, and generate responses makes machine learning fundamental to AI.
Machine learning is integral to modern technology, powering search engines, recommendation systems, voice assistants, and more.
It also drives advancements in fields like healthcare, finance, and environmental science, offering solutions to complex challenges.
Exploring the Different Categories of Machine Learning: An Overview
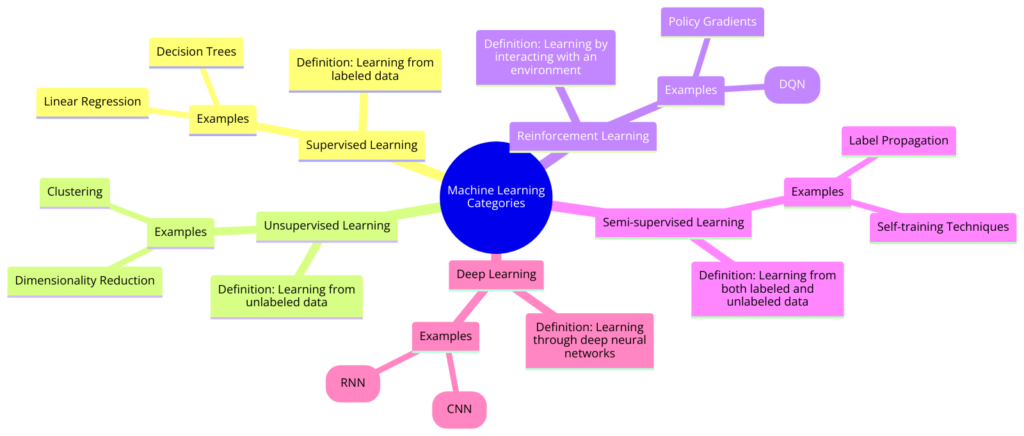
Machine learning is broadly categorized into several types, each with its own methods and applications:
- Supervised Learning: Uses labeled data to train models for classification and regression tasks.
- Unsupervised Learning: Analyzes unlabeled data to identify hidden patterns or structures.
- Reinforcement Learning: Trains models to make decisions by interacting with an environment and learning from rewards or penalties.
- Semi-supervised Learning: Combines a small amount of labeled data with a large amount of unlabeled data to improve learning accuracy.
- Self-supervised Learning: Generates supervisory signals from the input data itself, enabling learning without labeled data.
Understanding the various categories of machine learning is essential to appreciate AI’s capabilities. Each category offers unique tools and methods for solving specific problems, contributing to the versatility and power of machine learning.
2. A Deep Dive into Supervised Learning: The Foundation of Machine Learning Applications

Supervised learning stands as a foundational pillar in the realm of machine learning, characterized by its use of labeled datasets to train algorithms to classify data or predict outcomes accurately.
This approach has facilitated the development of a wide range of applications, from simple linear regression models to complex deep neural networks.
Understanding Supervised Learning
Supervised learning involves training a model on a labeled dataset, where input-output pairs are used to learn patterns. The model compares its output to the actual output, adjusting its parameters to minimize errors. The goal is for the model to generalize from the training data to make accurate predictions on new data.
There are two primary tasks in supervised learning:
- Classification: Predicting discrete labels, like spam detection in emails.
- Regression: Predicting continuous values, such as house prices.
Key Algorithms and Their Applications
- Linear Regression: Models relationships between variables using a linear equation, ideal for predicting numerical values.
- Logistic Regression: Used for binary classification tasks, estimating probabilities with a logistic function.
- Decision Trees: Model decisions and their consequences, useful for classification and regression tasks.
- Support Vector Machines (SVMs): Effective for high-dimensional data classification, finding the best separating hyperplane.
- Random Forests: An ensemble method using multiple decision trees to improve accuracy, reducing overfitting risks.
- Neural Networks: Composed of interconnected nodes that learn complex patterns, excelling in speech recognition, image classification, and NLP.
Applications of Supervised Learning
Supervised learning powers various applications:
- Healthcare: Predicting disease outbreaks, patient outcomes, and treatment effectiveness.
- Finance: Detecting fraud, predicting stock prices, and assessing creditworthiness.
- Retail: Analyzing customer data to predict purchasing behavior, optimize inventory, and personalize marketing.
Supervised learning’s ability to learn from labeled data and make accurate predictions makes it a foundational machine learning approach.
Its wide range of algorithms and applications demonstrates its versatility and effectiveness in solving diverse problems.
As machine learning evolves, supervised learning remains a critical pathway for developing intelligent systems that interpret and interact with the world.
3. Unraveling Data Patterns with Unsupervised Learning in Machine Learning

Unsupervised learning, a pivotal category of machine learning, distinguishes itself by operating on unlabeled data.
This approach aims to uncover hidden structures or patterns within datasets without the guidance of explicitly provided outcomes or labels.
It plays a crucial role in exploratory data analysis, dimensionality reduction, and the discovery of intrinsic groupings within data.
Understanding Unsupervised Learning
Unsupervised learning operates on unlabeled data to uncover hidden structures or patterns. It groups similar data points and organizes them into clusters, enabling the discovery of intrinsic relationships within the data.
There are two main tasks in unsupervised learning:
- Clustering: Grouping objects based on similarity.
- Dimensionality Reduction: Reducing the number of variables to simplify models, visualize data, and improve computational efficiency.
Common Algorithms and Techniques
- K-Means Clustering: Partitions data into K clusters based on feature similarity, used in market segmentation, document clustering, and image compression.
- Hierarchical Clustering: Builds a tree-like structure of clusters, useful for understanding data hierarchies.
- Principal Component Analysis (PCA): Transforms data to new coordinates, reducing variables while highlighting significant relationships.
- Autoencoders: Neural networks that learn efficient codings of data, effective for dimensionality reduction and anomaly detection.
- t-Distributed Stochastic Neighbor Embedding (t-SNE): A nonlinear technique for visualizing high-dimensional data in 2D or 3D.
Use Cases of Unsupervised Learning
Unsupervised learning is applied across various domains:
- Customer Segmentation: Businesses use clustering to segment customers for targeted marketing.
- Anomaly Detection: Identifying unusual data points for fraud detection and network security.
- Genomics: Categorizing genes and understanding genetic variations for personalized medicine.
- Recommendation Systems: Discovering similar items or content to enhance user recommendations.
Unsupervised learning’s ability to reveal hidden patterns in unlabeled data makes it a powerful tool. It enables the exploration of intrinsic data structures, providing new insights and discoveries across various fields. As data grows in complexity, unsupervised learning’s role in extracting value and understanding will become increasingly important.
4. Mastering Decision-Making: The Role of Reinforcement Learning in Machine Learning

Reinforcement learning (RL) involves an agent learning to make decisions by interacting with an environment. The agent takes actions and receives rewards or penalties based on outcomes, aiming to maximize cumulative rewards over time.
Key components of RL include:
- Agent: The learner or decision-maker.
- Environment: The world the agent interacts with.
- Action: Possible moves the agent can make.
- State: The current situation of the agent in the environment.
- Reward: Feedback from the environment to evaluate actions.
Applications of Reinforcement Learning
RL is applied in various domains:
- Gaming: AlphaGo’s success in defeating a world champion in Go highlights RL’s capabilities. It’s also used in video games to improve non-player character behavior.
- Robotics: RL enables robots to learn tasks like walking, object manipulation, and navigation with minimal human intervention.
- Autonomous Vehicles: RL helps self-driving cars learn optimal navigation strategies and decision-making.
- Personalized Recommendations: Streaming services and e-commerce platforms use RL to dynamically adjust recommendations, enhancing user engagement.
Unique Aspects of Reinforcement Learning
RL differs from other learning paradigms:
- Decision Making Under Uncertainty: RL agents make sequential decisions with long-term consequences.
- Exploration vs. Exploitation: Balances exploring new strategies and exploiting known ones to maximize rewards.
- Delayed Rewards: Agents consider long-term benefits and strategies.
Reinforcement learning represents a powerful approach to machine learning, focusing on learning through interaction and feedback. Its applications in gaming, robotics, autonomous systems, and personalized services highlight its potential to tackle complex decision-making tasks. As RL evolves, it promises to unlock new capabilities and applications, advancing AI.
5. Enhancing Machine Learning with Semi-supervised and Self-supervised Learning

Machine learning’s landscape is enriched by the nuanced approaches of semi-supervised and self-supervised learning, which blend elements of supervised, unsupervised, and reinforcement learning paradigms.
These methodologies address the challenges of data labeling constraints and leverage the vast amounts of unlabeled data available, providing efficient and innovative ways to train models.
Semi-supervised Learning
Semi-supervised learning uses partially labeled datasets, combining labeled and unlabeled data. This approach is beneficial when acquiring labeled data is costly or impractical. Algorithms aim to improve accuracy by leveraging the unlabeled data to understand the dataset structure.
Key concepts and applications:
- Consistency Regularization: Ensures similar predictions for slightly modified unlabeled examples, used in image and speech recognition.
- Self-training: Uses a model trained on labeled data to label unlabeled data, progressively incorporating confident predictions.
- Semi-supervised Clustering: Enhances clustering with some labeled data, useful in customer segmentation and bioinformatics.
Self-supervised Learning
Self-supervised learning generates supervisory signals from the data itself, eliminating the need for external labels. It trains models to predict parts of the input from other parts, leveraging inherent data structures.
Key concepts and applications:
- Predictive Tasks: Models learn by predicting missing parts of data, such as masked word prediction in text.
- Contrastive Learning: Models distinguish between similar and dissimilar data instances, enhancing representation learning.
- Self-supervised Pretraining: Pretrains models on large unlabeled data and fine-tunes on smaller labeled datasets, improving performance in NLP and computer vision.
Bridging the Gap Between Supervised and Unsupervised Learning
Semi-supervised and self-supervised learning leverage unlabeled data, addressing supervised learning limitations and reducing the need for large labeled datasets. They enhance model performance, reduce annotation costs, and expand application areas.
Semi-supervised and self-supervised learning represent innovative machine learning approaches, efficiently using unlabeled data to address AI challenges. These methodologies play a crucial role in developing more capable, efficient, and broadly applicable AI systems.
6. Navigating Challenges in Machine Learning: Ethical and Practical Considerations

Machine learning, despite its significant advancements and applications across various domains, is not without its challenges.
Each category of machine learning—supervised, unsupervised, reinforcement, semi-supervised, and self-supervised learning—faces unique hurdles that can impact model performance, scalability, and ethical considerations.
Challenges in Machine Learning Categories
- Supervised Learning: Depends on large labeled datasets, which can be costly and time-consuming. Models risk overfitting.
- Unsupervised Learning: Validating model performance is difficult without labeled data. Determining the right number of clusters and interpreting results can be challenging.
- Reinforcement Learning: Designing effective reward systems is complex. Training requires substantial computational resources.
- Semi-supervised Learning: Balancing labeled and unlabeled data use is tricky. Models may rely too heavily on labeled data.
- Self-supervised Learning: Designing predictive tasks that lead to useful feature learning without introducing biases is challenging.
Ethical and Practical Considerations
- Bias and Fairness: Models can learn and amplify biases, leading to unfair outcomes. Ensuring fairness requires ongoing evaluation.
- Privacy: Using personal data raises privacy concerns. Techniques like differential privacy and federated learning mitigate concerns but add complexity.
- Transparency and Explainability: Making complex models understandable is crucial for trust in critical applications.
- Sustainability: The environmental impact of training large models is a concern. Reducing computational resource requirements is important for sustainable AI development.
Machine learning’s potential is transformative, but addressing challenges and ethical considerations is essential for responsible development. Balancing innovation with fairness, privacy, transparency, and sustainability ensures AI benefits are realized equitably.
7. Predicting the Future: Evolving Categories in Machine Learning

The future of machine learning (ML) is poised for even more groundbreaking advancements, with each category of ML—supervised, unsupervised, reinforcement, semi-supervised, and self-supervised learning—expected to evolve in exciting ways.
This evolution will be driven by both technological innovations and the increasing integration of ethical considerations into AI development.
Emerging trends and potential advancements suggest a future where machine learning not only becomes more powerful and efficient but also more equitable and accessible.
Emerging Trends and Potential Advancements
- Advancements in Algorithms and Architectures: Research will yield more efficient and accurate algorithms, enhancing learning from fewer examples. Innovations in few-shot and transfer learning will improve adaptability.
- Increased Focus on Efficiency and Sustainability: Developing energy-efficient training methods and models will reduce environmental impact. Techniques like model pruning and quantization will gain importance.
- Greater Emphasis on Ethical AI: Robust frameworks and tools will ensure fairness, privacy, and transparency in models, addressing bias and distributing AI benefits.
- Expansion of Self-supervised and Unsupervised Learning: Methods requiring less human annotation will advance, making better use of vast unlabeled data.
- Cross-disciplinary Approaches and Applications: Integrating ML with other fields will open new research avenues and applications, solving complex real-world problems innovatively.
Evolution with AI’s Progression
- Supervised Learning: Will require less labeled data and become more generalizable, reducing training costs.
- Unsupervised and Semi-supervised Learning: Will leverage unlabeled data more efficiently, playing key roles in knowledge discovery and autonomous AI systems.
- Reinforcement Learning: Will become more practical for broader applications with advanced simulation environments and reward shaping.
- Self-supervised Learning: Will drive innovations in machine understanding and interaction, leading to more intuitive AI systems.
The future of machine learning is marked by innovation, ethical advancements, and expanding applications. Balancing power and responsibility ensures AI development benefits all. Embracing machine learning’s diversity and leveraging its potential will advance AI, solving global challenges and enriching lives.
8. Conclusion: Harnessing the Diversity of Machine Learning for Future Innovations

The exploration of machine learning’s various categories—supervised, unsupervised, reinforcement, semi-supervised, and self-supervised learning—reveals a field that is both rich in diversity and brimming with potential.
Each category, with its unique methodologies and applications, contributes to the vast ecosystem of artificial intelligence, enabling machines to learn from data in ways that mimic and sometimes surpass human capabilities.
The Significance of Machine Learning Categories
Understanding the different categories of machine learning is crucial for several reasons. First, it enables practitioners and researchers to choose the most appropriate methods for their specific tasks, whether it be classifying data, uncovering hidden patterns, or enabling machines to interact with their environments.
Second, a deep understanding of these categories fosters innovation, as knowledge of one approach can inspire novel applications or the development of hybrid methods that blend elements from multiple categories.
Lastly, awareness of the strengths and limitations of each category guides the ethical application of machine learning, ensuring that models are not only effective but also fair, transparent, and respectful of privacy.
Encouraging Responsible and Innovative Use
Understanding different machine learning categories is crucial for choosing appropriate methods, fostering innovation, and guiding ethical AI applications. Each category offers unique approaches for solving specific tasks, inspiring novel applications and hybrid methods.
Encouraging Responsible and Innovative Use
Responsible development and deployment of machine learning technologies are essential. Addressing data biases, privacy, transparency, and sustainability ensures AI advancements are equitable and beneficial. Interdisciplinary collaboration and lifelong learning are key to navigating challenges and leveraging AI’s full potential.
Looking Forward
The potential of machine learning to transform industries and solve global challenges is immense. Realizing this potential requires technical ingenuity and ethical considerations. By prioritizing responsible development, the machine learning community can ensure AI advancements contribute to a more equitable, sustainable, and prosperous future for all.
Machine Learning categories offers opportunities for innovation and impact. Navigating with a commitment to responsible AI ensures that machine learning enriches lives and addresses global challenges effectively.
FAQ & Answers
1. What are the main categories of machine learning?
The main categories include supervised, unsupervised, reinforcement, semi-supervised, and self-supervised learning.
2. How do supervised and unsupervised learning differ?
Supervised learning uses labeled data for training, while unsupervised learning finds patterns in unlabeled data.
Quiz
Quiz 1: Match ML Category to Application
Instructions: For each real-world application listed below, match it to the appropriate machine learning category from the list provided.
ML Categories:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
- Semi-supervised Learning
- Deep Learning
- Transfer Learning
Applications:
A. Predicting house prices based on various features (e.g., location, size, and number of bedrooms).
B. Organizing personal photos into clusters based on the people present in the photos without prior labeling of individuals.
C. An AI playing and improving at chess or Go by playing games against itself.
D. Using a small labeled dataset and a large unlabeled dataset to improve the accuracy of image classification models.
E. Recognizing and interpreting human speech to convert it into text.
F. Applying a model trained on one language to understand sentiment in another language with minimal additional training.
Answers:

A. 1. Supervised Learning – This involves using labeled data (e.g., historical data on house features and their sold prices) to predict the price of a house.
B. 2. Unsupervised Learning – This involves clustering or grouping data based on similarities without any prior labels. The algorithm identifies patterns itself.
C. 3. Reinforcement Learning – This involves an agent learning to make decisions by taking actions in an environment to achieve some goals.
D. 4. Semi-supervised Learning – This combines a small amount of labeled data with a large amount of unlabeled data during training, improving learning efficiency and accuracy.
E. 5. Deep Learning – This subset of machine learning involves neural networks with many layers. It is particularly good at recognizing patterns in unstructured data like audio for speech recognition.
F. 6. Transfer Learning – This involves taking a pre-trained model (on one task or dataset) and adapting it to a similar but different task or dataset with minimal re-training.
This quiz can help illustrate the wide range of applications for machine learning technologies and the specific categories they fall into.
Quiz 2: ML Techniques
Instructions: For each description provided below, identify the machine learning technique it refers to.
Descriptions:
- This technique involves models that are capable of making decisions and predictions based on input data. It is characterized by its ability to learn from labeled data, using input-output pairs to learn a mapping from inputs to outputs.
- A model-free reinforcement learning algorithm that estimates the quality of actions without requiring a model of the environment. It’s particularly useful for learning optimal policies in complex environments.
- This unsupervised learning technique is used for reducing the dimensionality of data while preserving as much of the data’s variability as possible. It’s often used for data visualization and noise reduction.
- A supervised learning algorithm that constructs a decision tree to model the decision process. It’s known for its simplicity and effectiveness in classification tasks, capable of handling both numerical and categorical data.
- A type of neural network that is particularly effective in processing sequential data such as time series, speech, or text. Its architecture allows it to remember inputs from the past, making it well-suited for tasks that involve sequential dependencies.
- This technique involves training a model in one domain and then transferring the learned features to a different but related domain or task. It’s useful for leveraging pre-trained models to improve performance when data is scarce in the target task.
Answers:
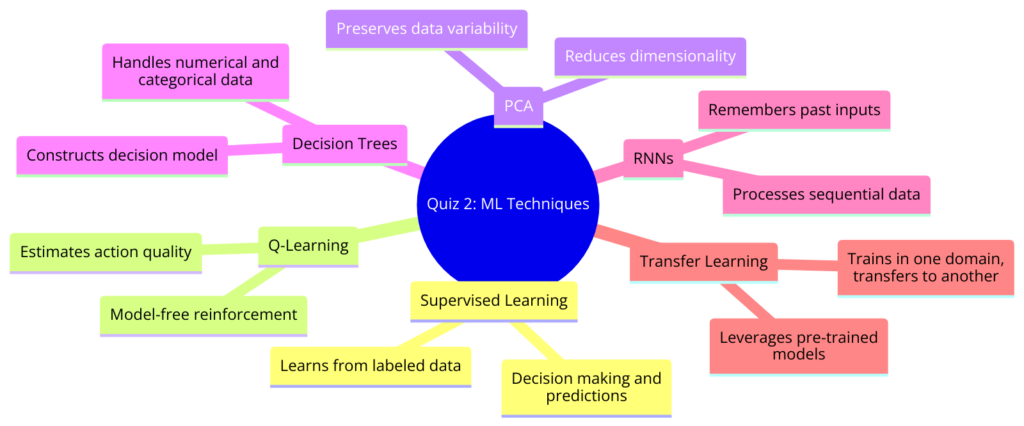
- Supervised Learning – This is the process where a model learns to map inputs to outputs based on example input-output pairs.
- Q-Learning – A type of reinforcement learning algorithm that doesn’t require a model of the environment and works by learning the quality of actions.
- Principal Component Analysis (PCA) – A statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables.
- Decision Trees – A decision support tool that uses a tree-like model of decisions and their possible consequences, including chance event outcomes, resource costs, and utility.
- Recurrent Neural Networks (RNNs) – A class of neural networks that is powerful for modeling sequence data such as time series or natural language.
- Transfer Learning – The practice of reusing a pre-trained model on a new problem, transferring knowledge from one domain to another.
This quiz is designed to test the participant’s knowledge of different machine learning techniques and their practical applications.





